

第四课 句法结构与依存分析
人类语言的成分
单词
有八个类别,常见的是名词(N.)、动词(V.)、形容词(Adj.)、介词(Prep.)和限定词(Det.)
短语
由单词组合而成
名词短语(NP.)
如"the door"
构建规则:Det.(+Adj.)\(^*\)+N.
介词短语(PP.)
如"by the door"
构建规则:Prep.+NP.
动词短语(VP.)
如"talk to"
构建规则:V.+PP.
不同短语之间的结合
不同短语之间还可以结合成更大的短语,如"the cat by the door"
依存关系
依存关系的定义
依存关系可以用来捕捉句子的结构从而理解句子的意思
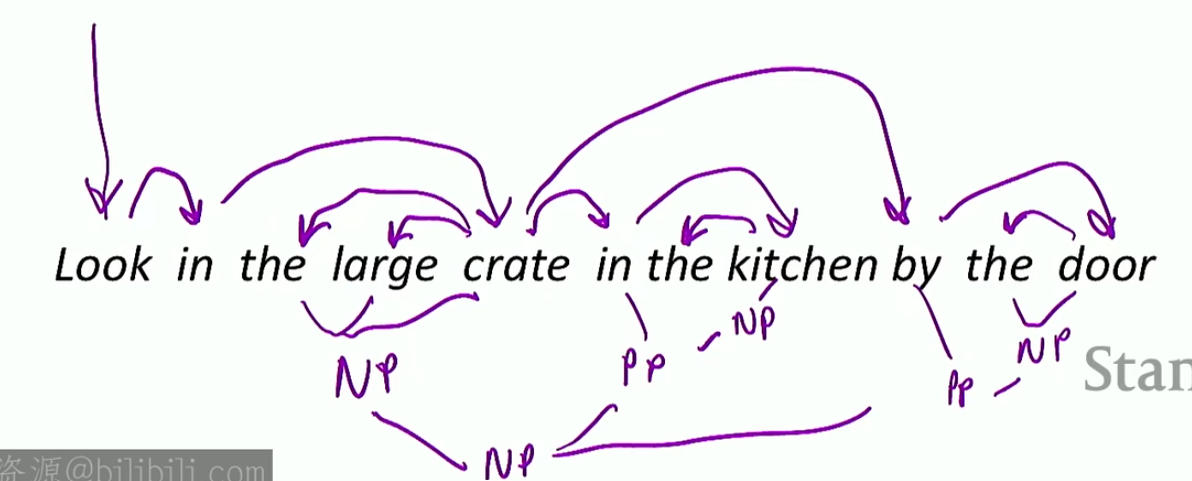
图中的箭头,从被修饰词指向修饰词,也就是说修饰词是“依存于”被修饰词存在的(如果被修饰词没有了那么修饰词就没有意义了);每一个句子都有一个起点,也即中心词(这个句子中是"Look")
写的正式一点的话就长成下面这个样子
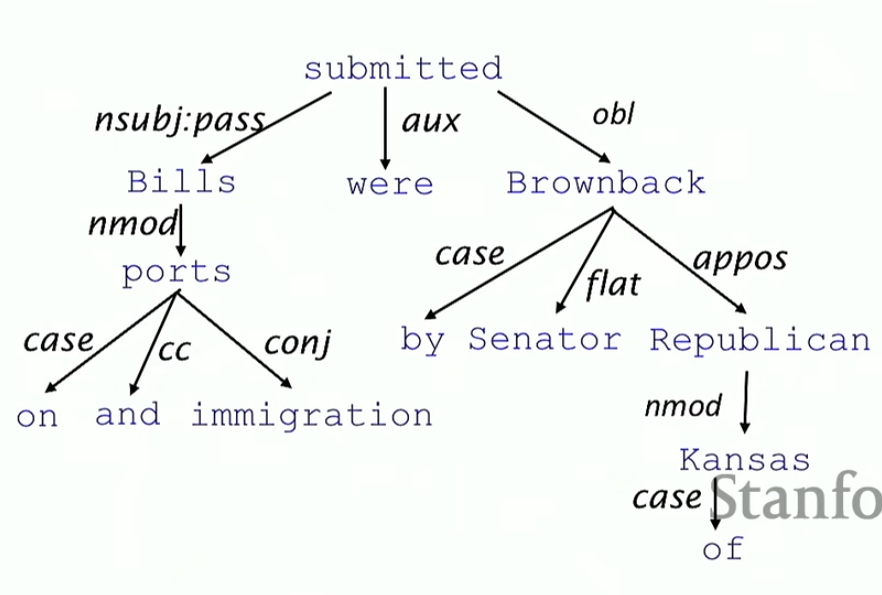
简单来说,箭头就表示了依赖关系,箭头旁边的字就明确了具体是什么依赖关系。我们不需要掌握具体的细节,明白是怎么来的就好了。
树库
上面那个比较正式的图就是树库
早期的树库是由人工构建的,耗时耗力,但是也存在很多优点,如下
- 复用劳动成果(Reusability of the labor)
树库的标注需要大量人工劳动,但一旦完成,即可被多次重复利用。研究者无需重复标注,可直接在不同项目中共享资源。
示例:英语的 Penn Treebank 是早期经典树库,被广泛用于句法分析、词性标注等任务,节省了后续研究的时间和成本。
- 支持构建多种工具(Parsers, taggers, etc.)
基于树库的标注数据,可以训练或优化多种自然语言处理工具。
示例:- 句法分析器:如 Stanford Parser 使用 Penn Treebank 训练,能够自动分析句子结构。
- 词性标注器:如 SpaCy 的部分模型依赖树库数据提升标注准确性。
- 语言学研究的资源(Valuable resource for linguistics)
树库为语言学家提供了真实的语法结构数据,支持对语言现象的定量分析。
示例:通过分析树库中的疑问句标注,语言学家可以研究英语倒装结构的分布规律(如 "What did you see?" vs. "You saw what?")。
- 广泛的覆盖范围(Broad coverage)
树库通常包含多样化的语料(如新闻、对话、学术文本),而非局限于少量人工构造的例句。
示例:Universal Dependencies (UD) Treebanks 涵盖 100+ 种语言的多样化语料,包括社交媒体文本和正式文献。
- 频率与分布信息(Frequencies and distribution)
树库能统计语法结构在实际使用中的频率,揭示语言规律。
示例:通过分析树库数据,可发现英语中被动语态在学术文本中的使用频率显著高于口语(如 "The experiment was conducted" vs. "Someone did the experiment")。
- 评估 NLP 系统(Evaluation of NLP systems)
树库作为“黄金标准”,可量化评估 NLP 工具的性能。判断模型是否能够像人类一样解析句子结构。有趣的是,在机器学习的早期年代,是根本没有评估方法的,人们判断一个模型好不好就是通过输入一个句子,然后看输出是否达到了预期的效果。所以树库作为评估方法是具有革命意义的
示例:句法分析器的准确率常通过在 Penn Treebank 上的测试结果衡量(如标注匹配率或依存关系准确率)。
依存关系所导致的语言中的歧义
由于我们人类理解句子的意思是先将大的句子拆分为上面讲的小的结构,然后确定小的结构中/之间的修饰关系,再理解整个句子的,于是不可避免地就是我们会错误地确认,这就是语言中存在歧义现象,如下
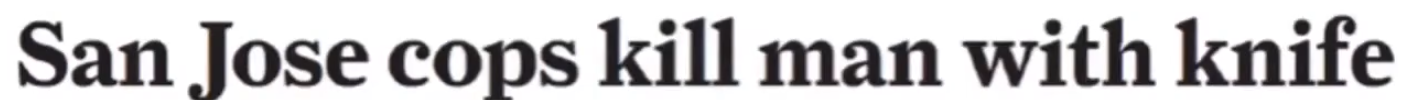
这个句子可以理解为警察用刀杀了人,也可以理解为警察杀了持刀的人
还比如
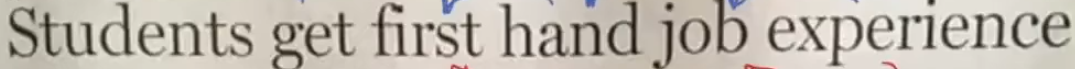
这个句子人类一般都不会发生歧义了,但是其实是有两种解读方法的,除了一眼看上去的那种,还有一种是Students get first / hand job / experience.
那么我们人类的大脑是有非常好的辨识歧义的能力的,比如这里肯定就是后一种意思。对于模型来说,他也需要具备我们人类这种能力,而他则是通过概率来选择/理解最有可能的情况的
树库所能提供的信息
那么模型如何从树库中获取信息呢?有四种方法
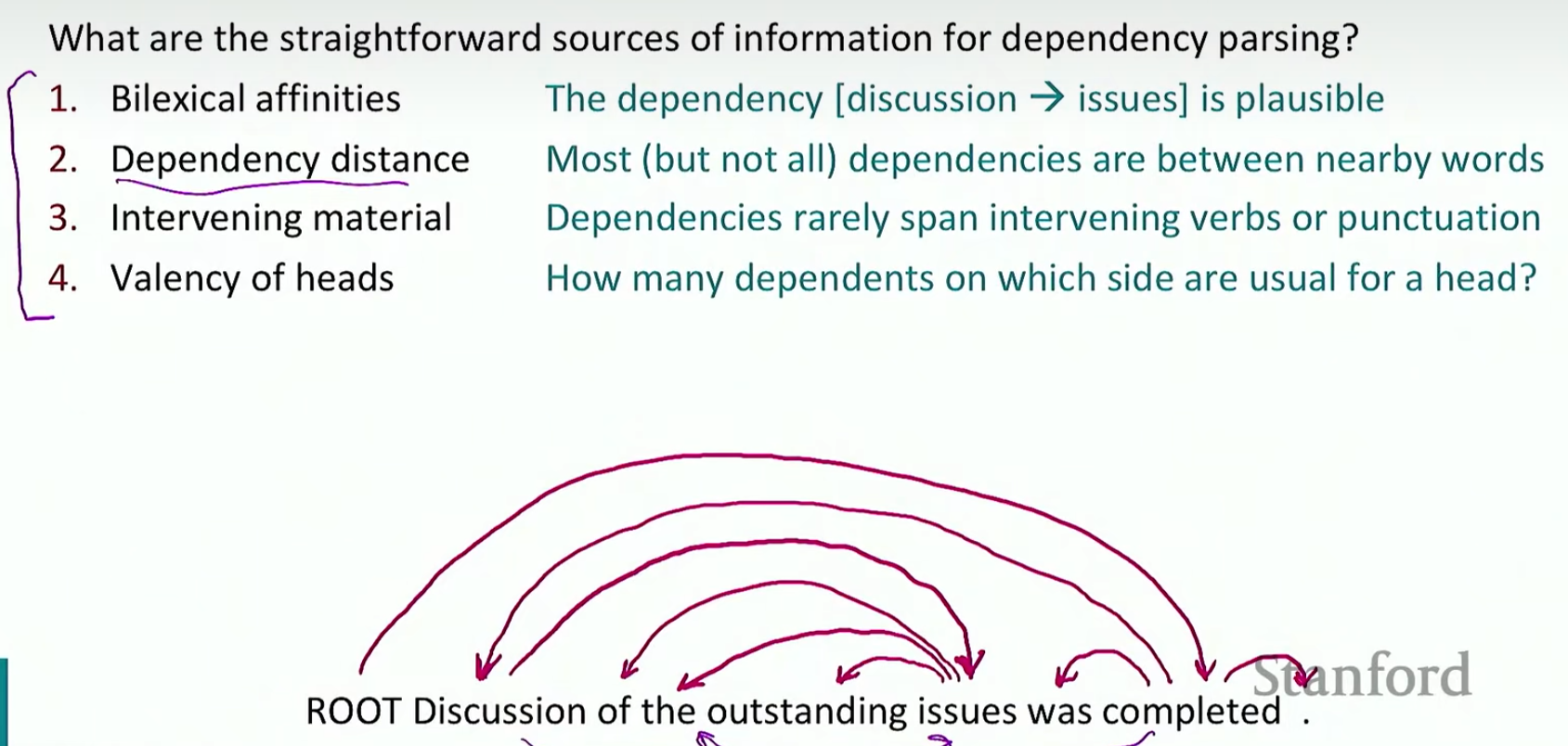
- 双射性(Bilexical affinities):依存关系可以通过词语之间的搭配倾向来确定。讨论和问题需要被解决。
- 依存距离(Dependency distance):大多数(但并非全部)依存关系存在于相邻的词语之间。这意味着依存关系通常在句子中距离较近的词语之间形成。
- 介入材料(Intervening material):依存关系很少跨越介入的动词或标点符号。这意味着依存关系通常不会被其他动词或标点符号打断。
- 中心词的从属词数量(Valency of heads):一个中心词通常有多少从属词?这涉及到中心词在句子中可以支配的从属词的数量。
依存句法分析的方式
符号学习方法
符号学习方法见视频00:53:40,感觉没啥用
深度学习方法
具体步骤
这个要先学习符号学习方法,具体见视频01:09:20
结果
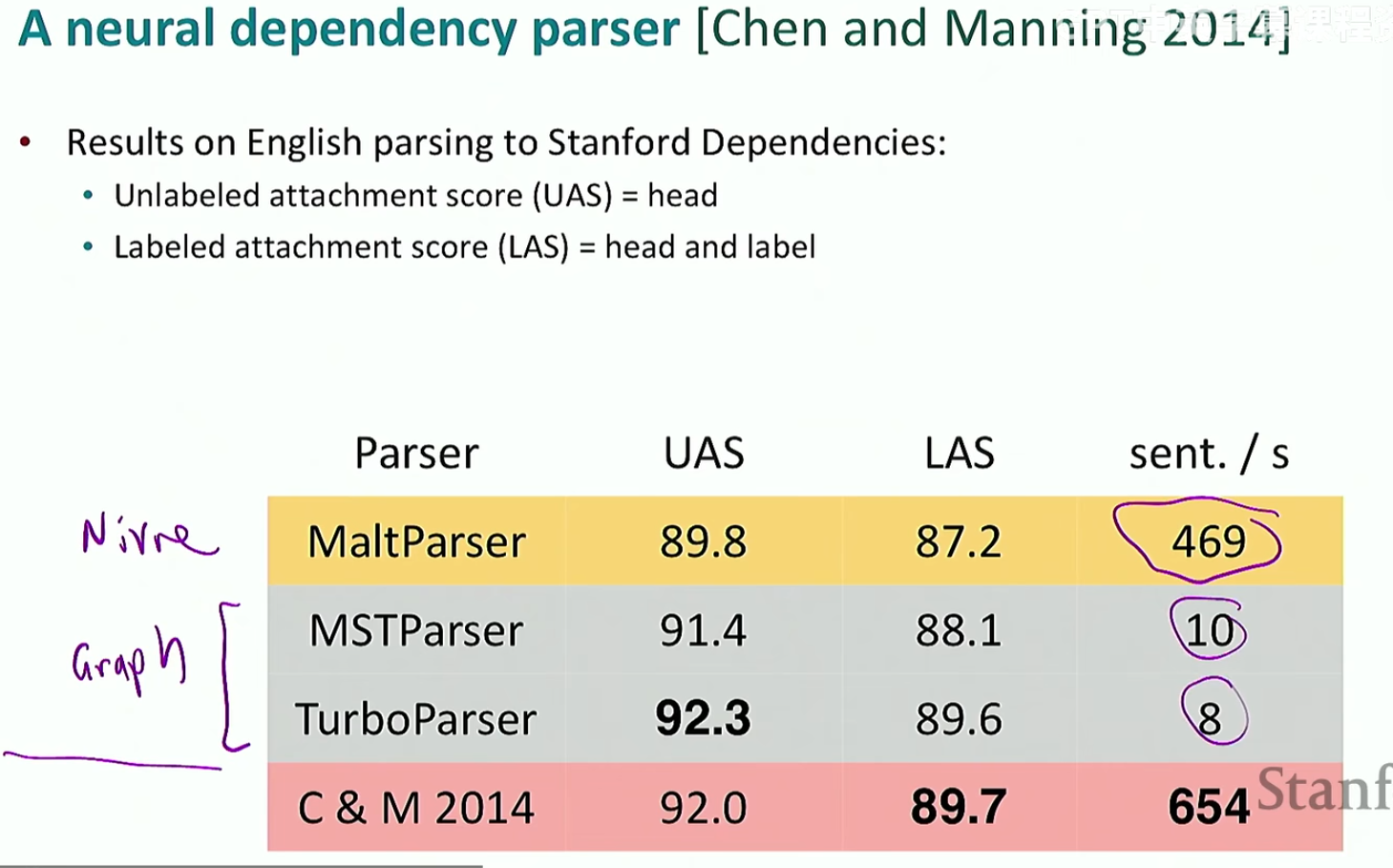
可以看到深度学习方法既可以实现高准确性也可以实现很快的计算速度
基于图的方法
具体见视频01:15:20
依存句法分析的评估方法
核心就是判断是否准确识别了箭头,如下
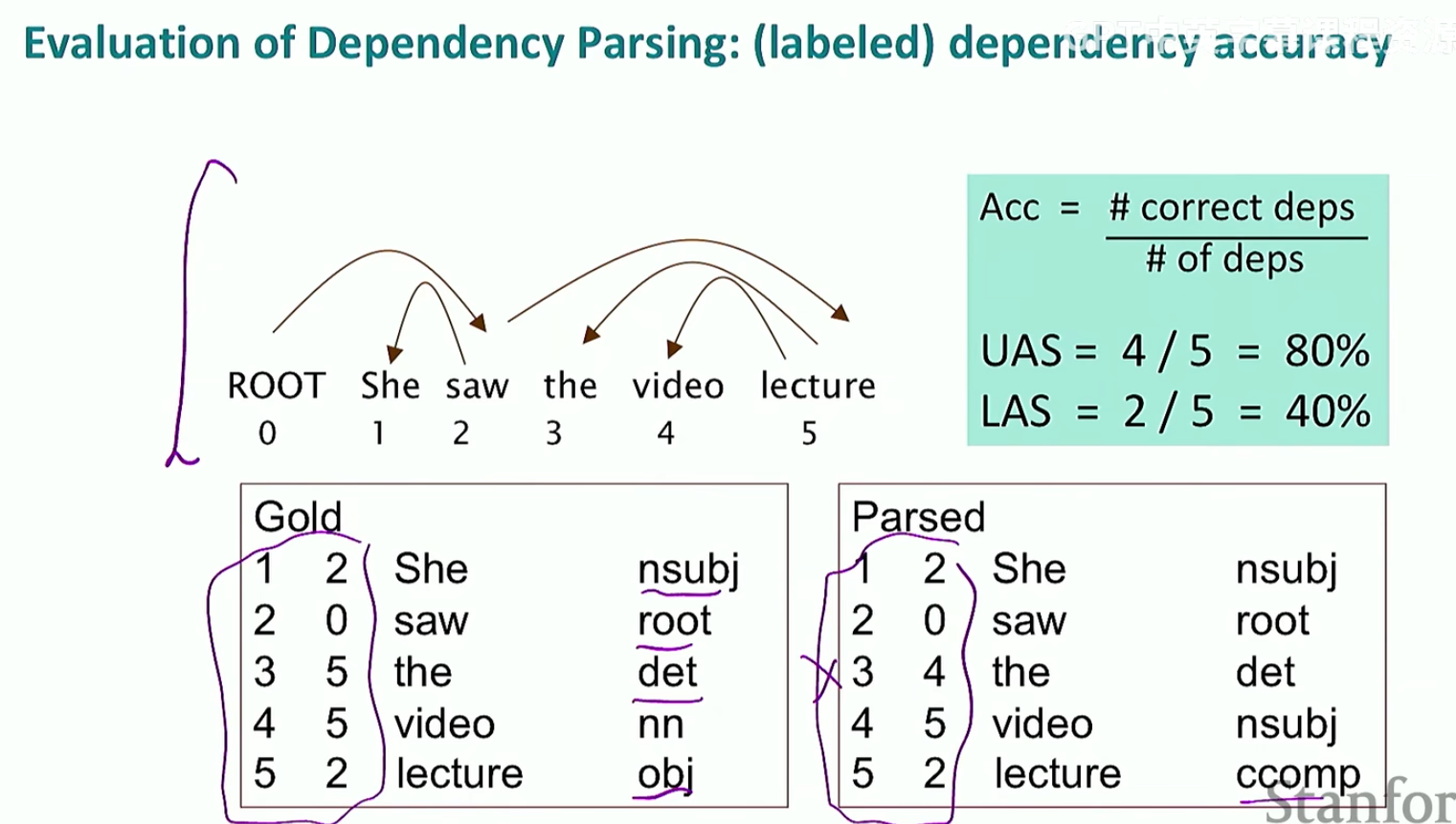
UAS是无标签依存准确率,也就是不去看每个单词的词性是否正确,只评估箭头是否对了;LAS则要求箭头和单词的词性都要正确

 浙公网安备 33010602011771号
浙公网安备 33010602011771号