

第二课 神经分类器
目录
Word2Vec的直观理解
上一课讲了词嵌入实际上是把单词嵌入到高维空间中,然而我们展示的时候只能通过降维在二维平面中展示,如下

但是实际上高维空间中的接近与二维平面中的接近不同,高维空间中的接近可以从多个维度进行接近,所以高维向量可以同时接近多个向量
如果采用直接计数的方法呢
现在一般的做法是训练嵌入向量,那么可不可以直接采用计数的方法呢?也就是如下

我们以采用窗口的情况为例,如下
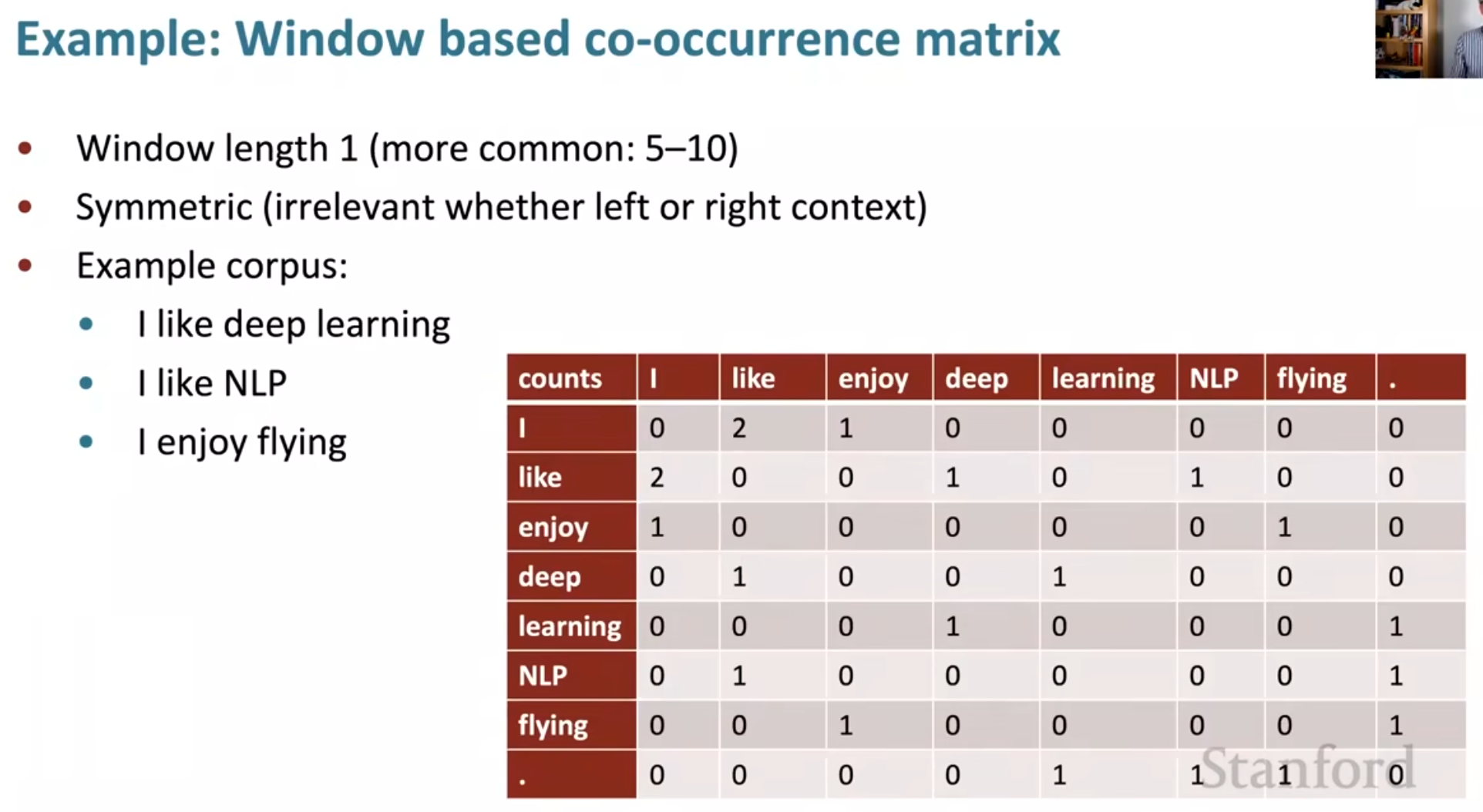
实际上,以前人们是用过这种方法的,但是很快就发现了这种方法的局限性,如下

解释一下最后一条:由于向量的维度很大,可能向量很稀疏,而噪声的含量也会增大
所以人们使用维度数较少的向量来表示词,让向量的每一维存储多种信息,如下

然后视频在00:32:00讲了一下如何通过SVD优化上述的矩阵,没看
作业一里面有实现上述计数词向量的代码,后面要用截断SVD进行降维,可以看一下
评估词向量的方法
上面讲了这么多词向量,我们如何去评估一个词向量呢?有两种评估方法:内在评估和外在评估,如下

中间任务与实际任务
在自然语言处理(NLP)中,“中间任务”是专门设计用于直接评估词向量质量的测试任务,它们不直接服务于实际应用目标,而是聚焦于验证词向量是否捕捉到了语言的核心规律(如语义、语法关系)。以下是详细解释:
1. 什么是中间任务?
- 定义:
中间任务是介于“词向量训练”和“实际应用任务”之间的诊断性任务,用于检验词向量的内在特性。 - 典型例子:
- 词义相似度判断:计算两个词向量之间的余弦相似度(如“猫”与“狗”是否语义相近)。
- 类比推理:解决类似“国王 - 男人 + 女人 = ?”的问题,验证词向量是否能捕捉语法或语义关系。
- 聚类分析:查看同义词、反义词是否在向量空间中聚集。
- 特点:
- 任务简单、可快速计算;
- 直接针对词向量的特性设计,而非实际应用效果。
2. 为什么能直接分析词向量?
- 无需复杂模型:
中间任务仅依赖词向量本身的数学性质(如距离、方向),无需将其嵌入到下游模型中。- 例如:计算“猫”和“狗”的余弦相似度,只需两个向量点乘和归一化。
- 聚焦词向量属性:
中间任务的设计目标明确,专门用于验证词向量是否满足以下特性:- 语义相似性:语义相近的词在向量空间中距离较近;
- 语法规律性:词向量能反映语法关系(如动词时态、单复数变化);
- 类比关系:向量空间中存在“国王 - 男人 + 女人 ≈ 女王”的线性关系。
- 快速反馈:
内在评估通过中间任务提供即时结果(秒级到分钟级),帮助研究人员快速调试词向量模型。
内在评估
1. 内在评估(Intrinsic Evaluation)
- 定义:直接针对词向量本身的特性进行评估,通常聚焦于中间任务(如词义相似度、类比推理等)。
- 例子:
- 计算词向量之间的相似度(如判断“猫”和“狗”的语义相近程度)。
- 解决类比问题(如“国王 - 男人 + 女人 = 女王”)。
- 优点:
- 快速计算:仅需简单的数学运算(如余弦相似度)。
- 直观解释:帮助理解词向量是否捕捉到了语言规律(如语义、语法关系)。
- 缺点:
- 与实际任务脱节:即使词向量在类比任务中表现好,也不一定在真实任务(如情感分析)中有效,需验证其相关性。
词语类比的例子如下
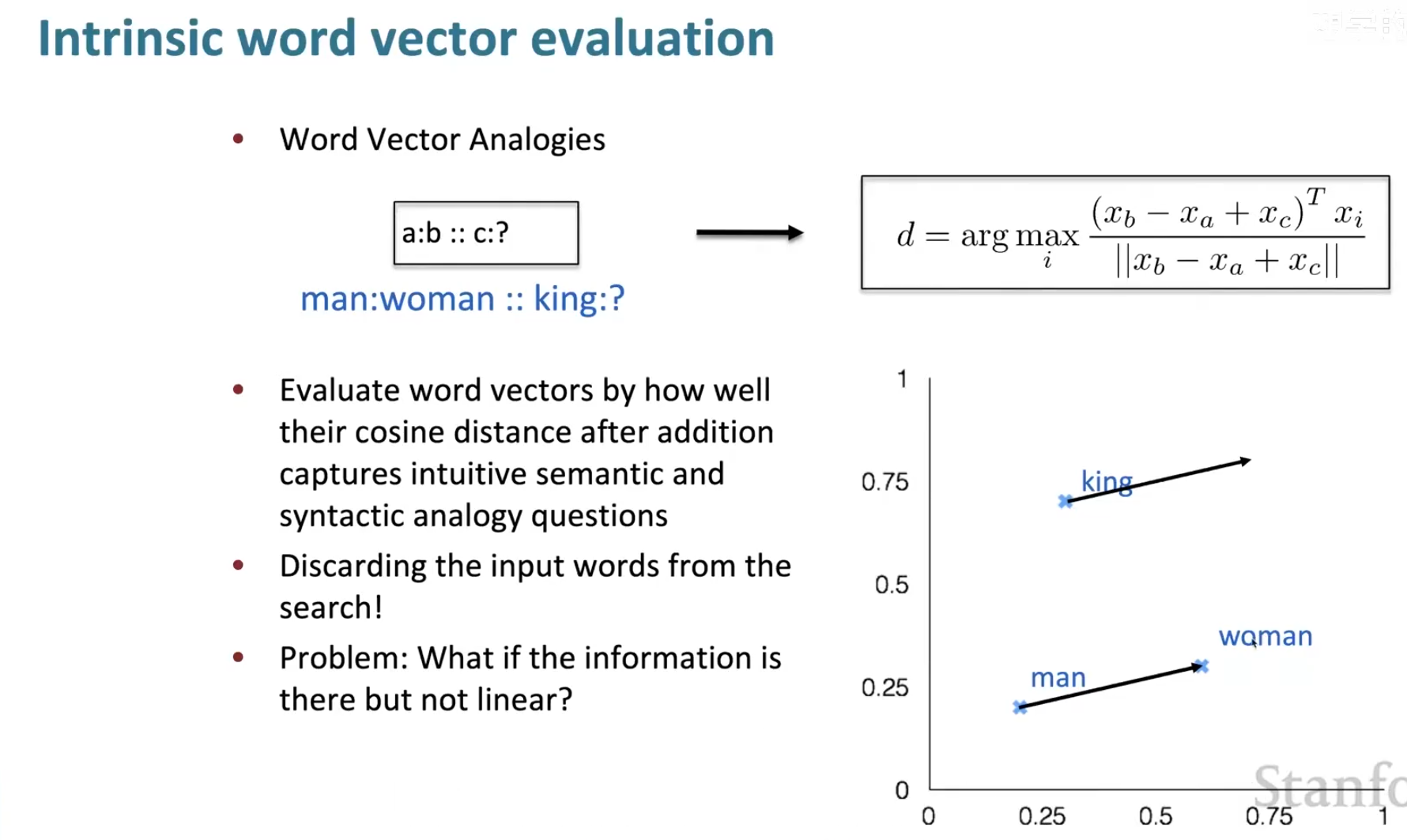
一般来说,人们评估的结果如下
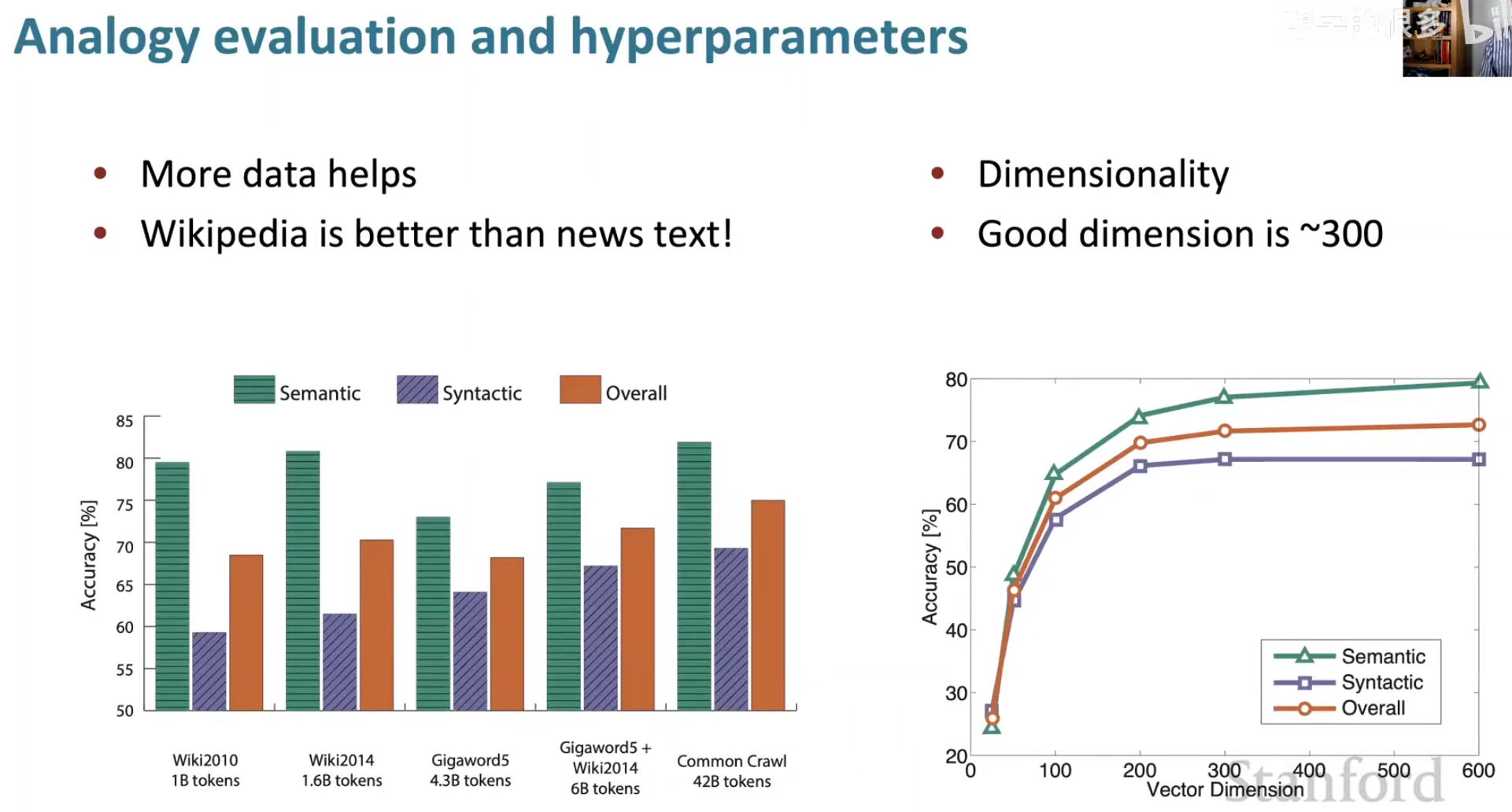
语义分析即例如“男人:女人::国王:王后”,语法分析即例如“slow:slowest::fast:fastest”
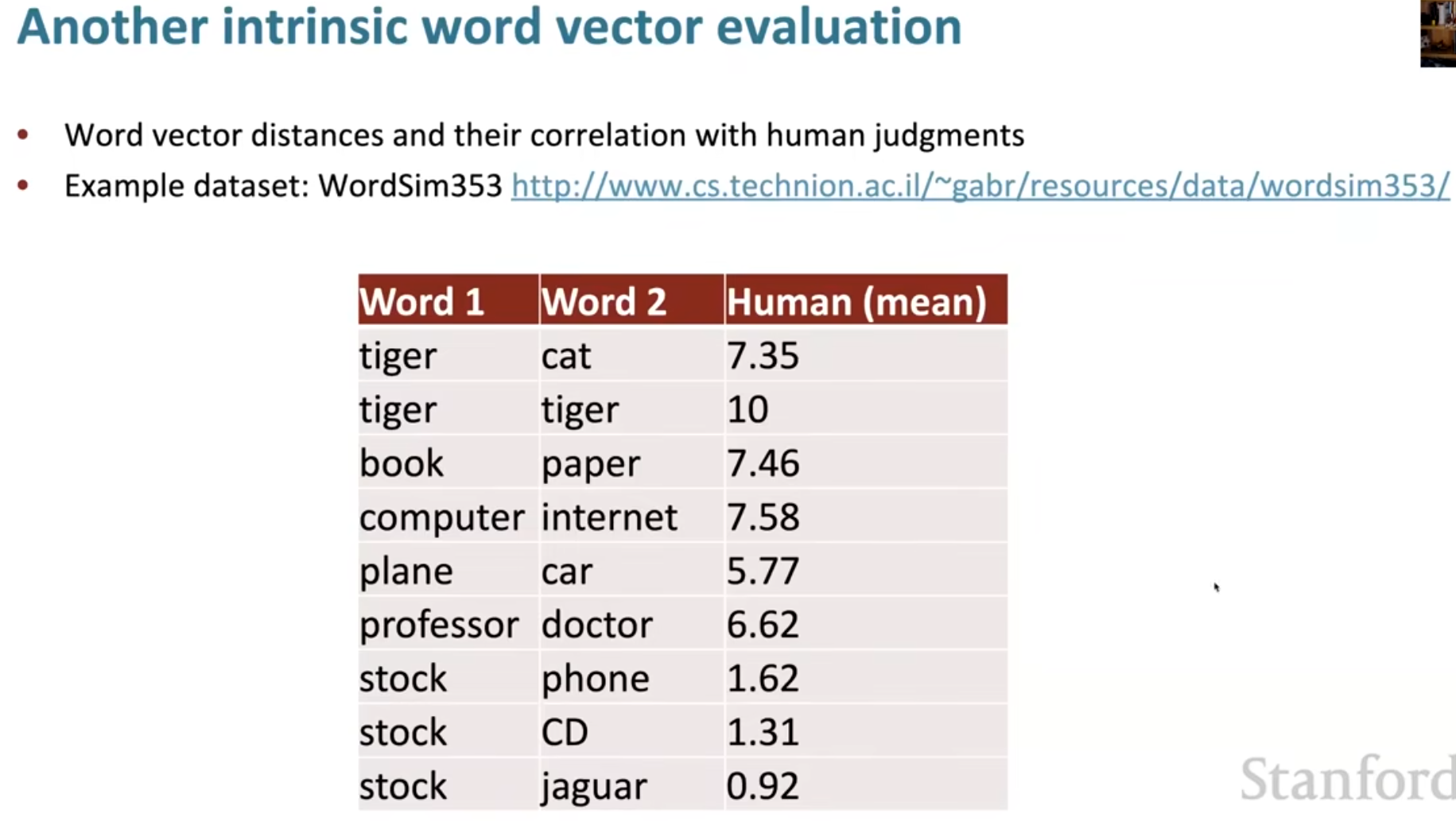
还有一种内在评估是词相似度。计算词向量之间的余弦相似度,并与人工标注的相似度评分进行比较
外在评估
2. 外在评估(Extrinsic Evaluation)
- 定义:将词向量嵌入到实际任务(如下游应用)中,评估整体系统的性能提升。
- 例子:
- 在文本分类、机器翻译、命名实体识别等任务中使用词向量,观察准确率变化。
- 优点:
- 真实场景验证:直接反映词向量对实际应用的价值。
- 明确改进:若替换词向量后系统效果提升(如准确率↑),则证明其优越性。
- 缺点:
- 耗时耗资源:需训练完整模型,计算成本高。
- 调试困难:若效果差,难以定位是词向量问题,还是模型其他部分的缺陷。
一种外在特征是命名实体识别
GloVe我确实没看懂为什么这么设计了,AI也问遍了,建议看看有没有什么其他视频讲明白吧(好像要用到什么LSA)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号