14.7.2 应用预训练词向量
在词类比任务中,为什么用\(\text{vec}(c)+\text{vec}(b)-\text{vec}(a)\)来进行近似呢?以man,woman,son,daughter为例.\(\text{vec}(\text{son})-\text{vec}(\text{man})\)后,就在son中去除了男性的成分,然后再加上女性的成分,即\(\text{vec}(\text{woman})\)就可以得到daughter
我们接下来关注一下可能存在的偏差问题。这里的偏差不是我们之前所说的偏置,而是下面

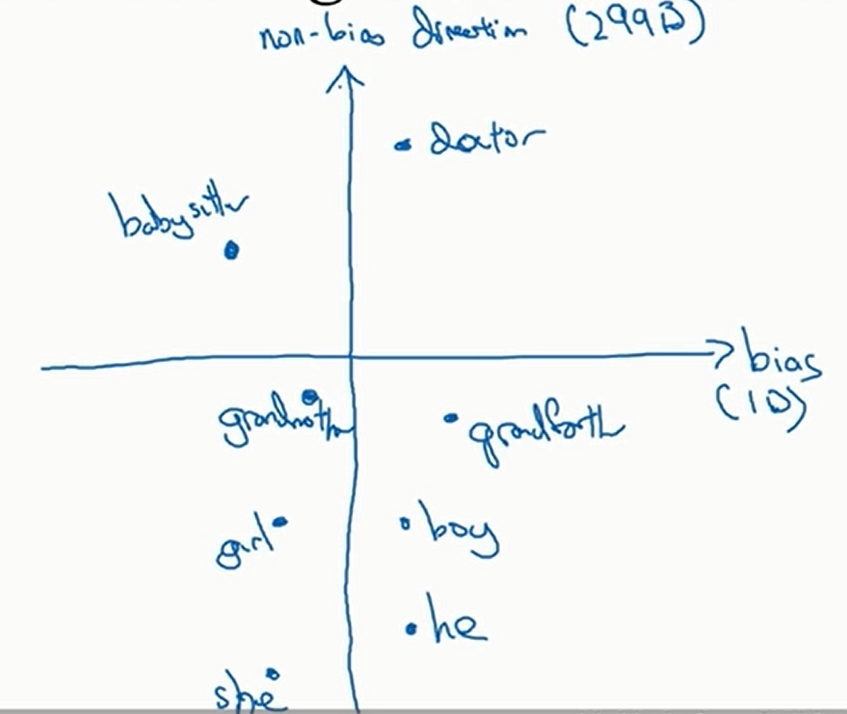
以性别歧视为例,假设经过\(\text{t-SNE}\)可视化之后的图像是下面这个样子

除偏的步骤如下
- 识别性别所代表的方向。我们在训练出来嵌入矩阵后,嵌入矩阵的每一行都是某个高维空间的一个坐标轴,我们使用SVD将这个高维空间中性别所代表的方向找出来
![image]()
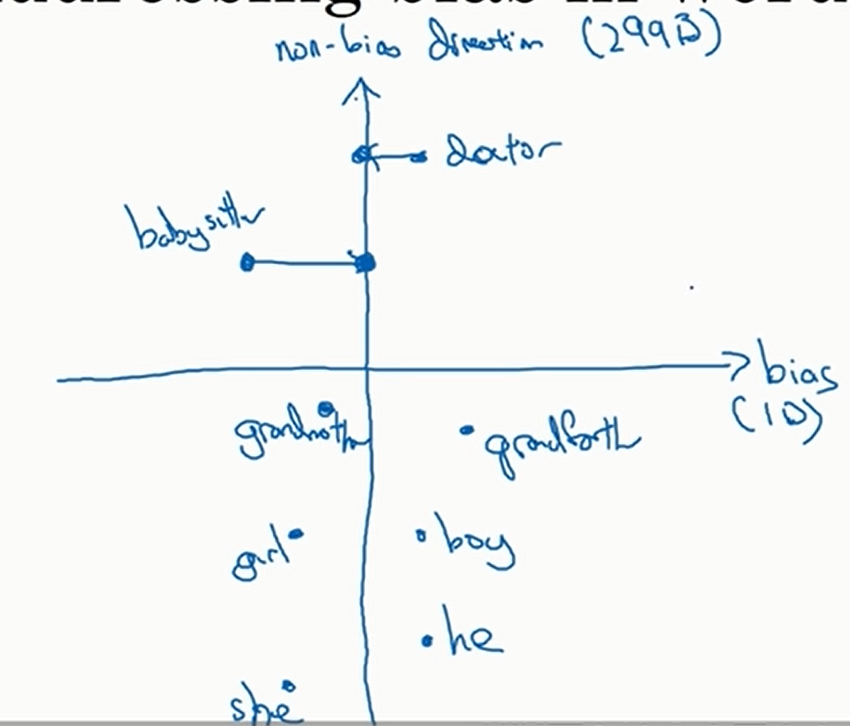
注意这里图中虽然性别这个方向是一维的,但实际上可能是高维的 - 中立化。将不含性别意义(单词比如girl,boy,grandmother,grandfather等就是包含性别意义的)的词语消除性别偏差,也就是将他们投影到非性别方向上面,比如下图中babysiter和doctor进行的移动
![image]()
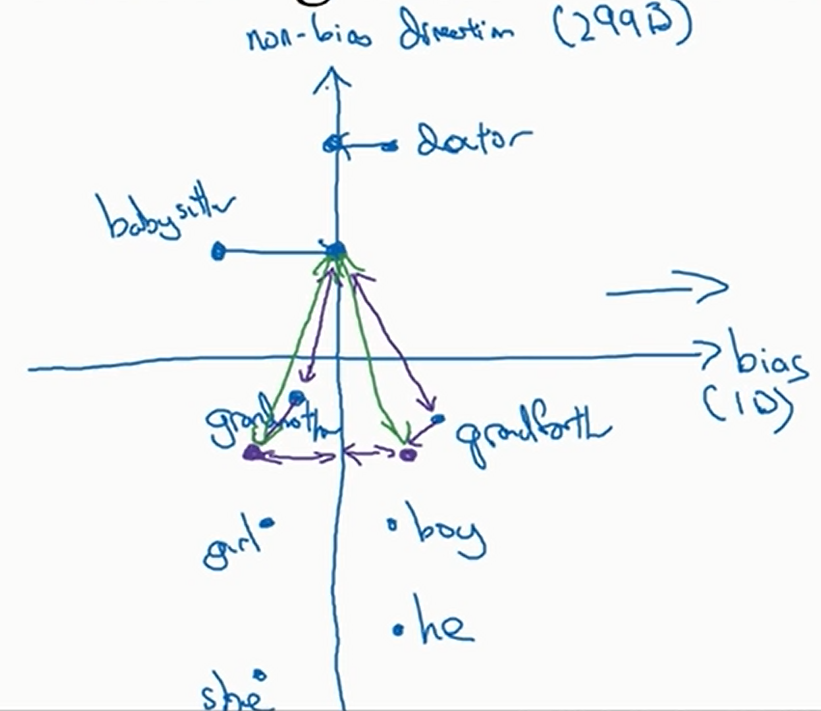
但是有时不含性别意义的单词是比较难判别的,比如beard,只是说统计意义上男性的胡须更多,但是女性也有胡须。一般来说会训练一个二元分类器判断单词是否有性别意义 - 均匀化。将含性别意义的词进行变换,使得每个词到非性别方向上的距离相等,于是这些词只有性别上的差异,如下
![image]()
grandmother和grandfather被移动到了紫色点
这样做是为了让不包含性别意义的词到包含性别意义的词的距离是相等的(比如图中babysiter到grandmother和grandfather的距离在移动前不等,在移动后就相等了),从而减少偏见
注意变换是成对成对的,比如grandmother和grandfather到非性别方向的距离相等(设为\(d_1\)),boy和girl到非性别方向的距离相等(设为\(d_2\)),不一定有\(d_1=d_2\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号