

186 语音识别
语音识别使用注意力机制,输入是不同时间帧的音频,如下

但是有一个问题,就是语音识别中,很可能输入的长度要比(我们想要的)输出的长度长的多,这个时候可以利用类似“填充”的技巧让两者的长度一样,如下(假设输入的音频说的话是the quick brown fox)
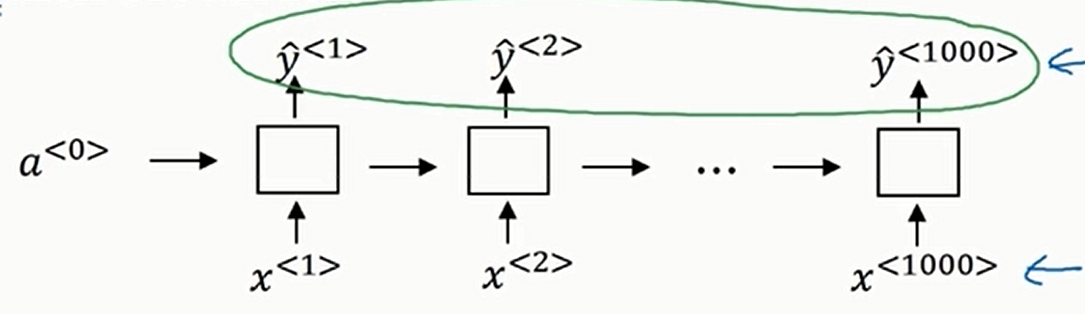
上图只是一个很简单的示例。现实中很可能使用双向LSTM或者GRU什么的。\(\hat{y}^{\left<i\right>},i=1,2,...,1000\)不是我们想要的输出,而是长成下面这个样子
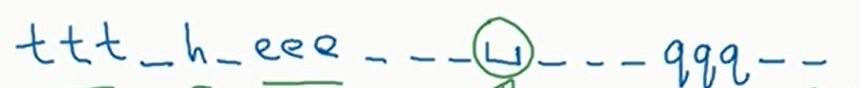
注意区别空格和空白的区别。得到了上面的输出后我们将所有重复的字符进行压缩,并且删除空白,就可以得到我们想要的句子。上面部分经过处理后变成下面这个样子

语音识别的一个应用就是敏感词触发,比如Hey,Siri.
一种简单的方法就是RNN输出\(0/1\)标识,当识别到敏感词的时候就输出\(1\)否则输出\(0\)
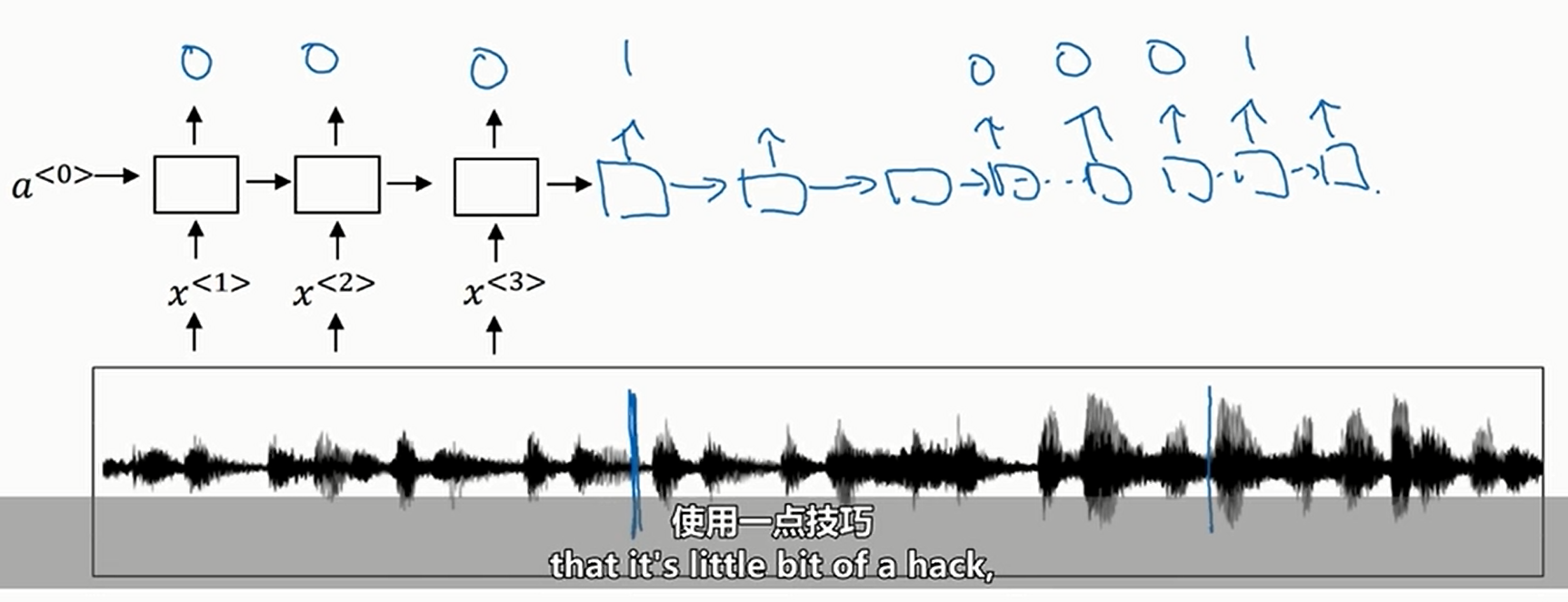
音频中蓝色竖线就是敏感词
这种方法很简单,但是有一个缺点就是样本严重不均衡。有一个比较简单的解决方法,就是在每个\(1\)的后面一段时间也标记为\(1\),这样会稍微均衡一点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号