

14.1.1 为何独热向量是一个糟糕的选择
我们之前都是用独热编码表示单词的,可能会出现下面的问题

显然,对于第二个句子的空格,我们也应该填写"juice",但是目前没有任何的机制表明"apple"与"orange"的关系比"apple"与"man"等的关系更近,所以我们不一定填的出来
此时可以使用词嵌入,如下
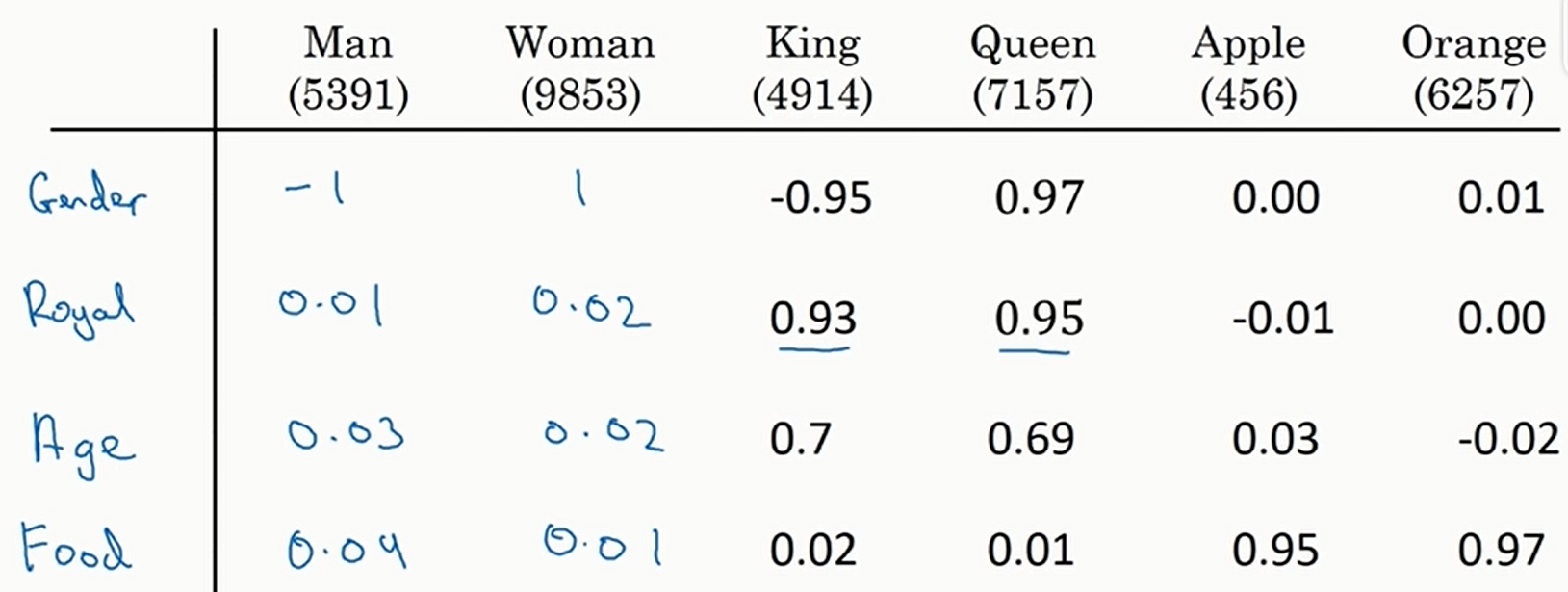
绝对值大小表示相关性。此时一个数列就是一个单词的特征
那么通过这个表,我们就可以知道"apple"与"orange"的关系比"apple"与"man"等的关系更近,于是就可以填出来了
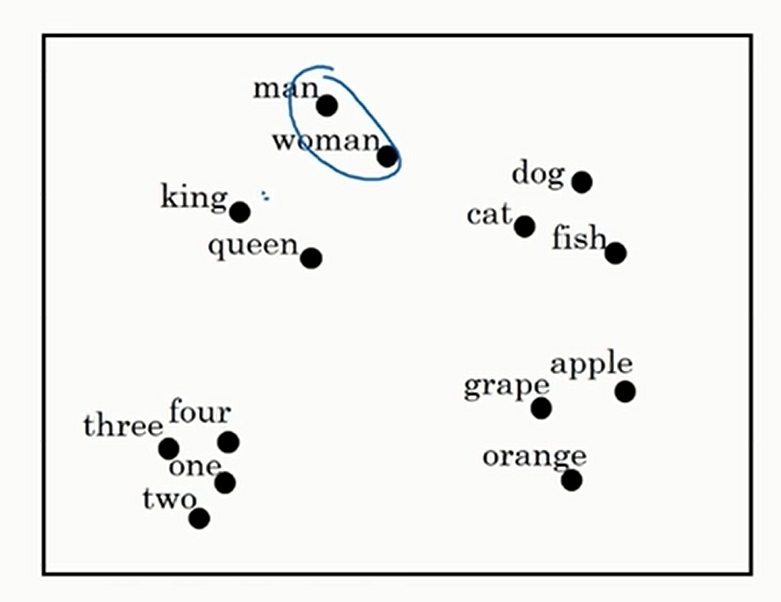
我们还可以通过一个叫做t-SNE的算法将高维数据的聚类可视化如下
使用独热向量还有如下缺点。以判断人名为例。如果我们只使用独热编码,那么我们的训练集不能太大(否则维度爆炸),所以遇到了下面这种情况
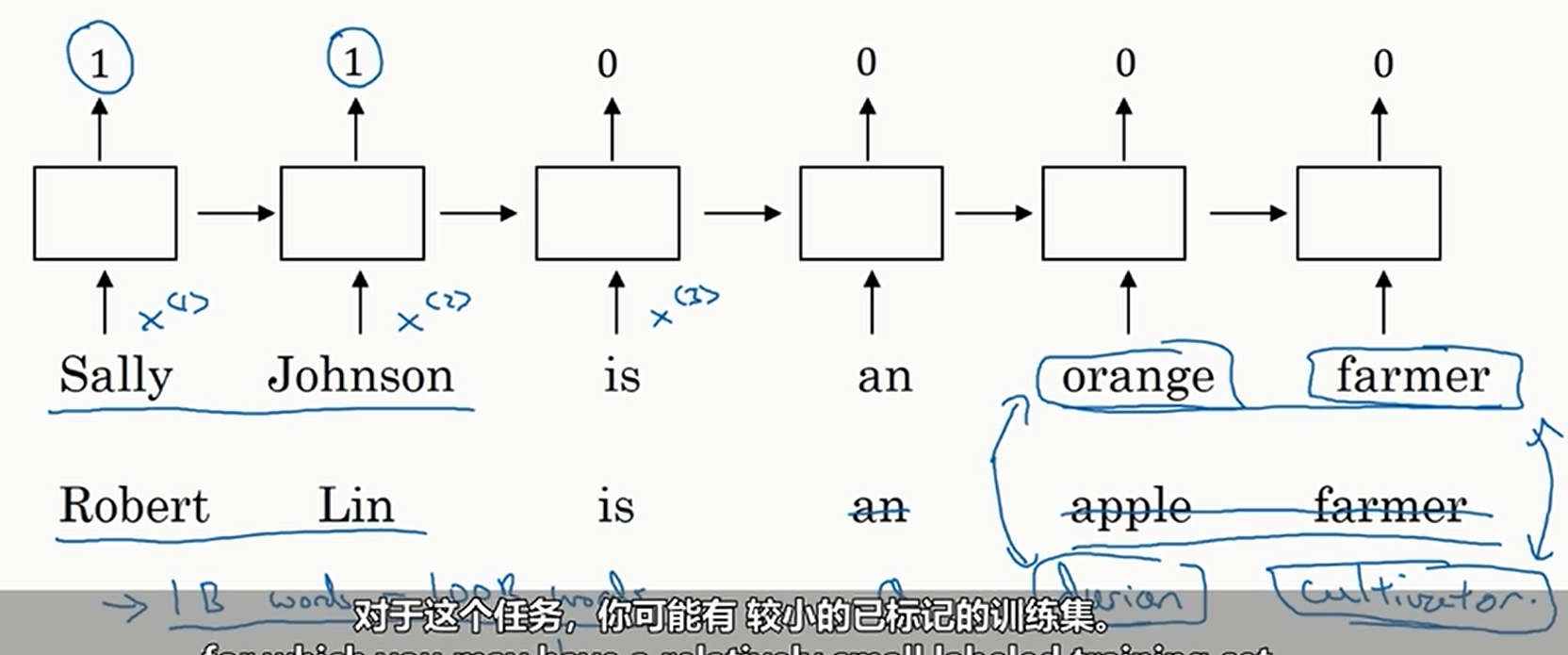
我们没有在训练集中坚果durian和cultivator,导致我们没有判断出来Robert Lin是人名
但是如果我们使用词嵌入,我们的训练集就可以很大(从网上下载即可),然后通过神经网络将词嵌入学出,最后判断的时候我们就可以发现两组词之间的相关性,于是我们在训练集中没见过的词就大大降低了。但是其实还是可能存在没见过的词,此时一般使用BPE(当然还有其他的做法,可以搜索一下)
最后还要提一点,我们举例的嵌入矩阵一直是下面这个

每一行似乎可以人为解释(性别,年龄等),但实际上无论我们用什么办法跑出来的嵌入矩阵的每一行都可能是无法解释的。一个很简单的理解方法:假设学出来的嵌入矩阵的每一行是可解释的,若我们有一个可逆矩阵\(A\),则有\(\theta^Te=(A\theta)^T(A^{-T}e)\),这就是将学出来的嵌入矩阵的坐标轴进行了变换,很显然就可以变换到一个我们根本不知道长成什么样子的时空,所以我们是无法保证我们学习出来的嵌入矩阵是可以解释的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号