学术流片复盘(二):idea、流片到点亮
fab 延期交付再加上第一次流片经验不足,让这最近两三周不能再充实:回片、封装、点亮、测试…… 跌跌撞撞终于赶在 DDL 临门把文章投了出去。一直不断听闻流片难,可难在哪?是 RTL 开发本身生态封闭抽象底层难?是集成电路前端后端知识体系高深?经过完整这一轮捶打后再对芯片生产全 flow 做个复盘。
芯片生产三阶段
以 AI 加速器为例,个人总结芯片整个生产周期如下图,其中蓝色表示需要设计开发的数字文件、绿色代表接口、黄色代表输入/输出文件、紫色代表必要资本投入、红色则是生成的实物。很多文件是有层层输入/输出关系,比如综合网表又是 RTL 网表综合输出,蓝色-黄色划分界限模糊大致意会:
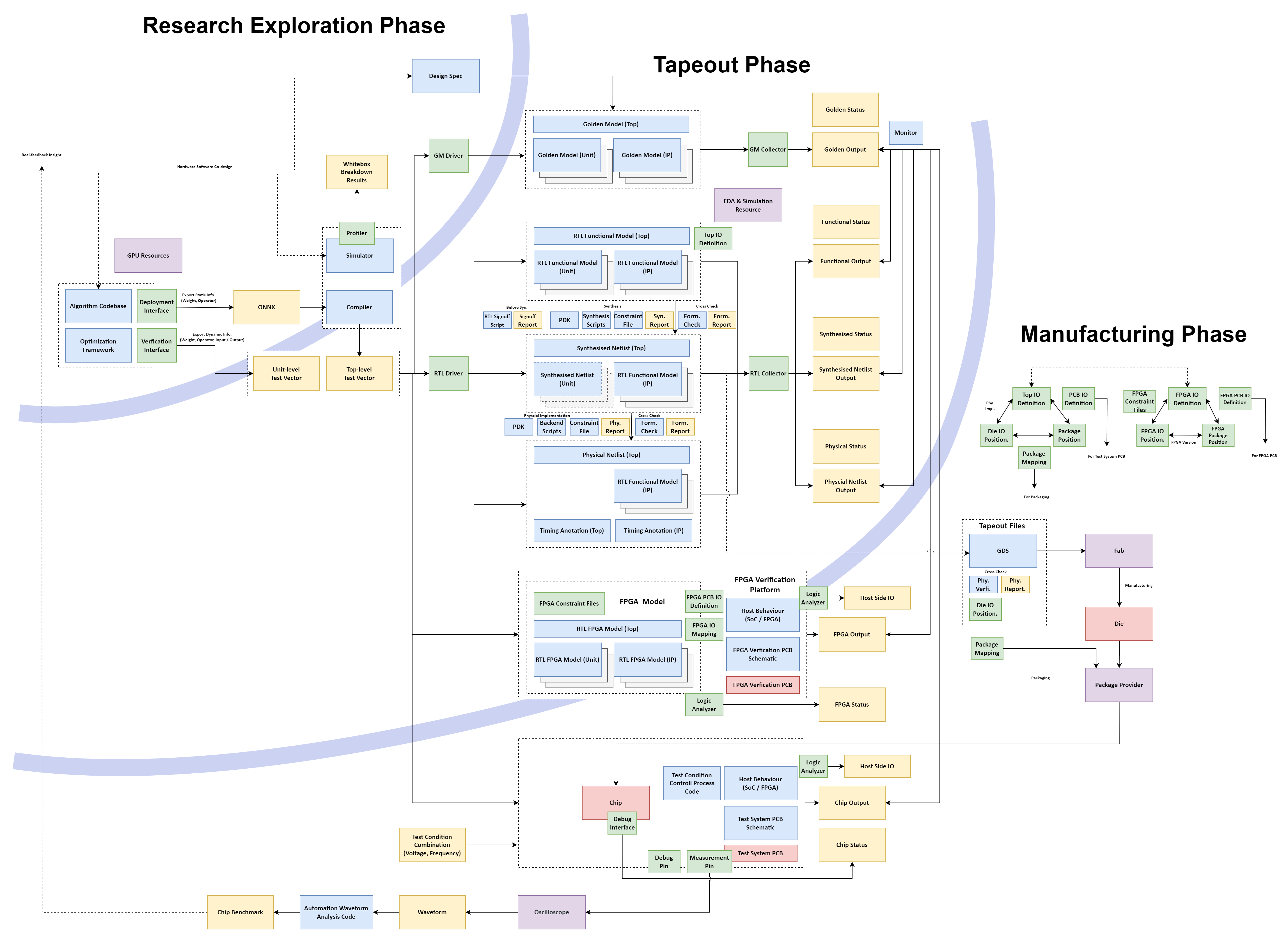
按大致时间走向,整个设计流程分为“Research Exploration Phase”, “Tapeout Phase”, “Manufacturing Phase”,第一阶段主要是研究型探索,验证抉择功能指标设计;当设计方案基本固定后,第二阶段实现设计方案;第二阶段和第三阶段以 Tapeout 为分界线,第三阶段则能看得到实物,测试芯片。总体设计流程呈现层层分工并且主要劳动力集中在第二/第三的工程阶段。再次回顾先前 blog 总结学术流片特点[1],流片并不符合学术小而美探索的成本出发点,且在工程资源相对匮乏的学界更加考验核心掌舵人的技术、管理能力。
将千万逻辑门束缚在指尖的代价
一个事物的成本来自于迭代次数以及事务复杂度,即:
此图直观展示芯片设计流程复杂度高,本质在于芯片在设计一个“极其复杂的硅、铜、铝混合的物理实体”[2]。
当然,我们也可以认为整个信息时代都是基于全球化的分层分工演进出来的(某种视角来看,OTT 是基于 4 G/5 G 通信网络的套壳产品,是全球通信网络建设的红利收割者)。但芯片设计行业因为某些特殊性,一直没有建立高效的抽象和分工,OTT 的数字设计就是最终产品本身,而芯片设计的数字化部分只是中间产物,最终的产品是一个极其复杂的硅、铜、铝混合的物理实体。
迭代次数:经验、直觉、抉择
芯片产品极高的复杂度加剧了迭代的代价,一次流片就是白白几亿的银子。先前 blog 总结 “RTL 是设计的最终手段”、“行动前评估实现复杂度”都是说这一点,即大部分时候我们无法承受抉择失误的代价。探索阶段在整体周期劳力占比少却至关重要,后续阶段劳力占比大但只是探索结果的忠实实现。用孙子兵法的话说,因为“兵者,国之大事,死生之地,存亡之道”,所以要庙算,“未战而先胜”,抉择至关重要。
然而系统中存在无法预测的复杂度,迭代次数来自于两方面,团队经验不足(踩坑)以及启发式探索。前者经过足够的人力和物力投入总能慢慢把坑踩得七七八八,最难办则在于启发式探索,即抉择阶段必须通过实践才能获取必要的信息反馈,但是实践的迭代次数又依赖于抉择的方向,形成因果的循环依赖。举个例子就好比处理器中的分支预测,分支执行依赖于深层流水线的执行结果,但等到结果结果则会让流水线空转数个周期,因此只能使用 Speculative 方法提前预测结果,一旦预测失误,则之前执行结果全部退回资源浪费。因此我判断芯片产品竞争力一个重要指标是看是否多次流片迭代产品,我认为产品迭代过程中的 insight 是公司的核心宝贵财富。
对于启发式迭代成本,其定义就决定了无法在不通过实践的方法获取信息,应当方法在于先判断出缺失的抉择信息,然后反推需要的实践方式,并依据实践方式性质具体决策:
- Speculative,依靠掌舵者全局意识+直觉推演方向;
- 提高探索阶段在整体流程中的投入比例,做更加详细充分的模拟器实验,这本质是在多条实践路线中选择成本更低的路线加大投入;
- 若抉择信息在系统之外,则扩大系统涵盖领域,加大投入跨领域耦合,比如 Software-Hardware Co-design。
复杂度:管理和自动化
大致来说,项目在越前期抉择的空间越大,而后期则主要管理“复杂度”问题。走完一遍,再问我流片难在哪里,我很难说出具体某一个环节有多难,前端、验证、测试系统设计、PCB 设计、芯片测试(后端这次外包出去了,不熟),每一个虽然不简单,但深度也不没有那么夸张,倒是事情很多很琐碎。我认为真正的难点在于以上各个环节的组合超高管理复杂度。
比如想象一个场景,tapeout 前几周团队猛猛加班,迭代了 N 个网表,给后端做出来了 N 个版图,其中一两个成员体力不支模模糊糊搞错了几个细节,和你汇报后修改相应错误并重新迭代生成了几个版本,最后终于功能正确、时序收敛、形式验证通过、物理验证通过,终于 ddl 之前极限把版图交了出去。过了几个月芯片回来,一个功能死活不正常,开始设计、驱动逻辑、测试系统逐级排查,这时你开始怀疑自己记忆,当初这个功能真的通过了吗,他现在的逻辑真的和我脑海中想的一致吗?服务器文件夹五花八门的版本命名重述那段时间 ddl 的紧迫,你只能开始挨个同事询问、翻看邮件和微信聊天记录,拼凑那一晚的记忆…… 这样的草台故事在整个流程中十分常见、反复发生,到了项目后期,我已经无法准确记忆每个成员的进度,只能每次同步再麻烦成员重新叙述一遍。 Linux 内核代码规范说“人的大脑一般可以轻松的同时跟踪 7 个不同的事物”[3],流程中每个步骤可能有 N 个迭代版本,不同的迭代版本之间又存在复杂的复用、耦合逻辑,很显然处理复杂度已远远超过了 7 个。
复杂度由所从事半导体性质决定,“复杂度无法消失只能转移”,转移的对象一般只有两个选项:人或者机器 —— 提高成员管理技能和提高自动化程度。
- (转移到人)建立详细的文档记录以及明确合作规范,将接收者理解的负担转移到输出者的规范记忆、文档攥写负担。此方法必须要谨慎使用,一个规范将全局给所有成员带来负担,一旦规范发生迭代或者要求过于详细,反而使得成员容易混淆或者额外负担过重(想象一下每次迭代工程不仅要更新代码文件,还需要更新文档),要谨慎控制这一部分任务量。
- (转移到机器)每次实验保存可追踪、可复现的文件记录,可追踪即每次实验都隔离记录而非覆盖,可复现即不仅要保存输出结果和报告,还要保留可复现的输入,避免对文件命名的依赖,单独靠阅读文件便能弄清楚语义。将文件管理成本转移到磁盘容量的需求。
- (转移到机器)提高自动化处理程度,将复杂流程、复杂语义,转换为简单流程、简单语义。比如使用自动化脚本耦合各个组件,将调用多个组件的复杂流程转为一键调用脚本的简单流程;自动化分析统计测试指标,将数量多语义低电平数据转换为数量少语义高的统计数据;用 wandb 或者 tensorboard 管理训练记录,将 log 信息转换为直观的损失函数曲线。将复杂度转移到建立 flow 脚本复杂度以及机器运算资源上。 这面临着流水线建设抉择——即建设流水线的成本大于流水线提高的效率。具体来说就是写脚本的时间比我写个文档记一下的时间还多,并且写出一个可维护低耦合的脚本的成本就更高了,当需求发生变动修改的成本可能又高于新建脚本的成本。但好在虽然 AI 无法很好处理硬件开发,但处理脚本流程准确度还是很够用的,大大改变了流水线建设的平衡点。
痛苦又兴奋(?)的流片经历
这次流片经历,大部分时间是痛苦的,纯粹用肝的劳力成本以减轻流片写作经验缺失的影响。特别是项目后期 die 回来后,对接封装、PCB、测试、实验、文章写作画图来回跑,四处救火,这边火灭了那边火又起来分身乏术,走完一躺整个人都燃尽了。
在漫长痛苦的回忆中,最触动的时刻还是 die 回来的时以及芯片回来点亮的时候。裸 die 那么薄,用镊子夹取时鼻息一呼吸都能掀翻。我无法用肉眼观测,只能看到 top metal 规律的反射光泽,也很难用镊子夹取操作,放在指尖更是像一片薄薄的纸片,很难想象就这么薄薄一片上集成了数百万数千万的逻辑管。但当芯片封装回来点亮测试通过的时候,通过示波器波形,通过屏幕上返回的输出数据,我又准确地知道他忠实地按我当初设计的规律运作,作为宏观尺度的人类,我对它是陌生的;作为设计者,又是世界上最了解他的人之一。无数文档设计推演,团队成员日日夜夜赶工,上下游供应商的合作,再加上人类数千年的智慧积累,终于成功将千万逻辑门束缚在指尖不到的小小空间内。这种复杂感觉在各个数字化的验证流程通过时未曾拥有,只有用手触碰到实物时才能体会。
“做硬件和软件做大的区别是,我们建造实物。”——不记得谁说的了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号