数据依赖(三):序列语言下的存储一致性
DeepSeek ISCA 2025 [1] 6.4 小节中提到无论 load/store 语义的 scale-up 网络,还是 message 语义的 scale-out 网络,维护一致性都会明显增加额外的通信开销。期望一种既需要程序员通过 acquire/release 等语义编程保证一致性,硬件上也不会增加太多额外开销的方法。
序列性:编程语言隐式归纳偏置
hart(hardware thread) 含义类似逻辑核,在描述硬件资源时用 hart 而不是 core 更加准确,因为可以通过比如超线程等方法将一个物理 core 掰开成两个逻辑 core
多线程为何需要程序员维护一致性呢?先前乱序执行相关 blog [2][3] 已阐述 hart 的顺序性问题可以依靠编译器解析、硬件调度保证,为什么现在又要程序员来维持顺序性呢?
程序运行的实例叫做进程,而如果程序发掘并行度则是多线程程序,线程之间的调度靠 OS 处理。比如程序 A 有 16 线程,程序 B 有 16 线程,计算机只有 8 个 hart 同时只能运行 8 线程,靠 OS 调度运行哪些线程,既可能是一边运行 4 个 A、4 个 B,也可能是 8个 A 8 个B 时分复用交替执行。由于用户运行时会执行哪些进程非常复杂,且程序之间一般相对独立,所以进程采取简单的内存空间隔离策略;而同一个进程的线程内部往往存在数据局部性关系和耦合关系,(来源同一个进程之间的)多线程则是共用同一个内存空间。
既然多线程程序都是编译器可见的,为什么还需要程序员手动维护,而不能类似单线程程序自动由编译器解析?反过来说,单线程程序不需要显式维护同步依赖关系才奇怪呢,用变量隐式构建依赖关系是天然的“语法福利”。序列性的单线程程序存在先后关系,利用先后关系便可解析出某变量读写的前后关系(数据依赖图)。 维持解析处出来的读写关系不变,便能从一种序列变换成另一种顺序序列。而多线程不存在隐式的先后关系,也就无法利用先后关系指定依赖,这便是 consistency 问题。
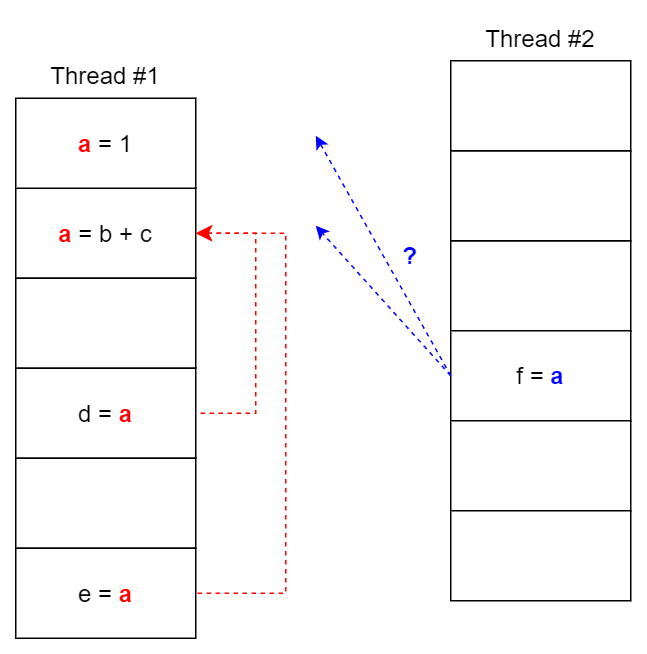
构建单线程程序时程序员也隐式地通过调用同变量代码的先后顺序构建了依赖关系,而多线程程序则需要显式说明,也许是顺序性符合人脑对文本处理习惯所以编程代价感受更低。用一副图说明编程模型和运行的关系:
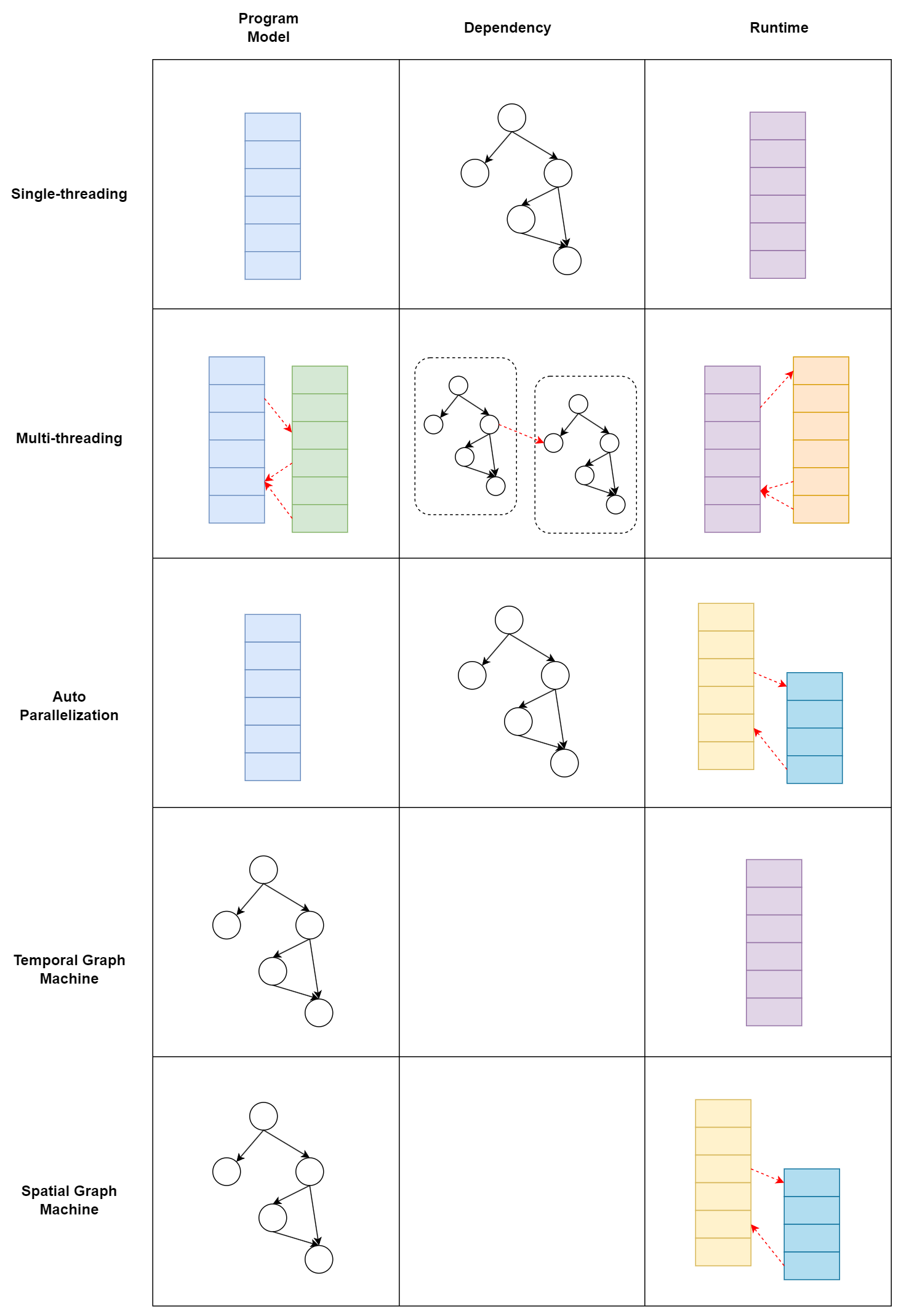
无论用什么编程模型本质都是描述一张数据依赖图。也许因为编译的 NP 问题或者历史路线惯性,将图的部分特性作为偏执归纳到了编程模型从而产生编程模型的差异区分,比如单线程模型比较亲和顺序性强的程序,多线程模型比较亲和大部分并行、小部分依赖的程序(如 SIMT),而如果程序结构十分复杂,则需要一个图亲和的编程模型。同时,任何编程模型都是在表达数据图,理论一张图可以用多种编程模型表示,不一定只有显式调用多线程库才有并行性,比如编译时开启 auto-parallelization 可以将常见的递归、循环等并行结构编译成多线程执行。
多线程编程也可以单 hart 机器时分复用执行,但一般线程数量都要求少于机器 hart 数量。不讨论这种情况。
一致性:同步的代价
了解为什么多线程程序需要手动同步,接下来看看实现同步需要什么原语和代价。
#include <iostream>
#include <thread>
int data = 0;
bool flag = false;
void writer_thread() {
data = 42; // 写操作 1
flag = true; // 写操作 2
}
void reader_thread() {
while(!flag) {}; // 读操作 1
std::cout << "Data: " << data << std::endl; // 读操作 2
}
int main() {
std::thread writer(writer_thread);
std::thread reader(reader_thread);
writer.join();
reader.join();
return 0;
}
reader_thread 依赖于 flag 判断 write_thread data 是否 store,但编程语言 ISA 的粒度不足以让 flag 代表 data store 的状态,两者是分布执行。从单线程顺序性来看, flag 赋值在 data store 之后,flag 赋值是 data store 的充分条件,但跨线程之间的数据依赖关系无法纳入本线程分析,在 write_store 线程看来,data 和 flag 之间没有用数据依赖,因此可能存在交换顺序的情况,破坏了充分条件。
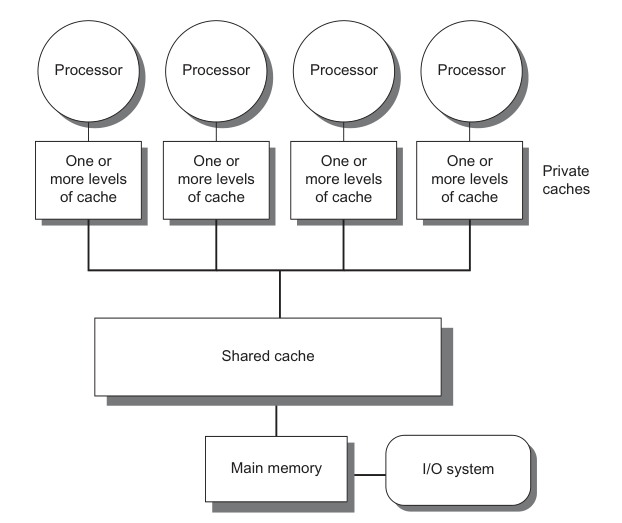
数据依赖关系通过共同变量定义,主流 CPU / GPU 一般是如下图的 SMP (Symmetric multiprocessing)结构,共同变量的访问实际上通过所有 hart 可见的 shared Cache / main memory 实现,hart register 和 main memory 之间交换顺序一般定义为 load /store [4],所以控制代码的顺序和控制变量 load/store 的读写顺序等价,这称作内存序(memory order)。
我们此处关注的顺序并非是流水线概念的顺序执行(in-order),而是不仅当执行到下一个内存操作时,上一个内存操作必须完成,一个指令从发射(issue)到提交(commit)的完整周期。如果两个连续的内存指令,意味着整条流水线的停顿,即对内存指令之间是原子的,而允许内存指令与其他指令并行。
- 第一种策略是让程序严格按照编程顺序执行。这种“宁愿错杀一百,不愿放过一个”方案虽然保证了正确性,但在如今高 ILP 处理器上可能会带来不可忽略的副作用,比如 X86 是强内存一致性模型(Sequential Consitency),每个线程内严格按照编程顺序执行,以上代码直接在 X86 上执行结果仍然正确。对内存模型有非常多种类的实现标准,此处介绍可详见量化体系架构第五章。为了保证多线程间的一致性,反而使得单个线程内的调度空间受限,这个结论非常有意思;
- 第二种策略则是让 data 和 flag 语义相同,flag 赋值成为 data 的充要条件,不存在部分执行的中间状态,用互斥锁将 data 和 flag 的存储锁住,其他 thread 只看到同时没发生和同时发生的两种状态,互斥锁也可以看作一种宏观的原子操作,;
- 第三种策略则是针对性地维护语句顺序,只关注保证正确性的顺序部分。内存序通过设置 memory barrier / fence 限制跨线程的顺序。
横向和纵向一致性
具体什么是 memory barrier [5]? 什么又是 acquire/release 语义?读了 cpp reference [6] 还是迷迷糊糊。调研精力有限,这里给出自己的猜测。
release/acquire 通过保证 release 之前的所有对 read & write 操作都不会在 acquire 之后的 read & write 操作之后。如下图,通过 release-acquire,可以保证 #11 在 #00 之后执行。从图中可见,实现其需要完成两个过程,纵向线程识别 fence 前后语句控制读写一致性;横向同步匹配 release-acquire 的 fence,只有二者同时存在语义有效,这应当通过某种共享变量实现。

纵向:RISCV 中关于屏障指令 FENCE 和 FENCE.I 的介绍很多,而实现分析缺几乎难以找到[7]。调研时间有限这里简单猜测,FENCE 包含两个操作数:前继和后继指令的内存操作类型,每个操作数是 r/w/rw 三者之一。猜测设置该指令后会在decode 阶段设置一个 flag,当同时满足 RS 中还存在前继指令,并且 decode 遇到后继指令时,阻塞流水线。
横向:而关于原子操作在指令上往往提供 Read-Modify 原语。Read modify 原语重要性来自同步变量往往需要经过查询-控制判断-更新状态的流程。读和写在 ISA 中分离,并且主存的访问往往涉及多个周期。从全局的视角共享变量的修改应当是一致的,而每次读都会在 hart 内产生副本,若在 Read-Modify 的期间如果有多个读取同时发生,则会造成不一致的多个副本同时存在。
符合一致性的编程涉及硬件内存模型以及处理的具体问题。还是以上面例子举例,仅仅需要维护 write_thread 线程内 data 和 flag 的纵向顺序,而无需关心全局变量 flag 的原子性。
DeepEP 同步实践分析
GPU 被认为是弱内存模型,需要通过显式同步维护一致性关系。CUDA 层面最常见的便是 __syncthreads() 同步 block 内部的 threads。
以 Deep EP [8] 库举例,库中最常用机器间通信同步是 barrier_device() , 其定义为:
template <int kNumRanks>
__forceinline__ __device__ void
barrier_device(int **task_fifo_ptrs, int head, int rank, int tag = 0) {
auto thread_id = static_cast<int>(threadIdx.x);
EP_DEVICE_ASSERT(kNumRanks <= 32);
if (thread_id < kNumRanks) {
atomicAdd_system(task_fifo_ptrs[rank] + head + thread_id, FINISHED_SUM_TAG);
memory_fence();
atomicSub_system(task_fifo_ptrs[thread_id] + head + rank, FINISHED_SUM_TAG);
}
timeout_check<kNumRanks>(task_fifo_ptrs, head, rank, 0, tag);
}
memory_fence() 的定义为对 PTX 系统级 acquire & release fence 包了一层, 此 fence 同时是 acquire 也是 release:
__device__ __forceinline__ void memory_fence() {
asm volatile("fence.acq_rel.sys;":: : "memory");
}
scale-up 可以通过 NV-Link 处理,scale-out 则需要显示调用 GPU 处理 RDMA 同步。这里通过 thread_id < kNumRanks <= 32 显式指定第一个 wrap SM0 负责处理机器间通信 [9],每个 thread 记录一个其余机器信息。
继续检查 timeout_check() 来理解共享变量的含义:
template <int kNumRanks>
__device__ __forceinline__ bool not_finished(int *task, int expected) {
auto result = false;
auto lane_id = threadIdx.x % 32;
if (lane_id < kNumRanks)
result = ld_volatile_global(task + lane_id) != expected;
return __any_sync(0xffffffff, result);
}
template <int kNumRanks>
__forceinline__ __device__ void
timeout_check(int **task_fifo_ptrs, int head, int rank, int expected, int tag = 0) {
auto start_time = clock64();
while (not_finished<kNumRanks>(task_fifo_ptrs[rank] + head, expected)) {
if (clock64() - start_time > NUM_TIMEOUT_CYCLES and threadIdx.x == 0) {
printf("DeepEP timeout check failed: %d (rank = %d)\n", tag, rank);
trap();
}
}
}
可见,机器 i 上的第 j 个 thread 负责检查 task_fifo_ptrs[i] + j + head 位置的变量,也就是 task_fifo_ptrs[i] 存储的是机器 i 对其余机器的同步信息,反推 fence 之前的系统级原子加法 atomicAdd_system 是先将自己的信息添加,然后 fence 全局同步添加操作,此时得到一个全是 1 的 kNumRanks x kNumRanks 的矩阵,然后依次执行 atomicSub_sytem 再将别人那里对自己的状态减少。相当于每个机器都是平权的,如果有某个机器挂了,其余所有运行良好的机器都应该能够检测出来。
不过如果机器挂了在 fence 阶段是否会出错呢?这个坑留到以后再填吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号