数据依赖(二):现有体系下表达依赖 —— Tomasulo 调度算法
虽然早在 1967 年就已经提出了 Tomasulo 调度算法 [1],但网上仍很少找到关于落到模块粒度的教程文档。从零复现一遍成本太大,因此用画原理图的方式做思想实验,尝试理解 Tomasulo 在电路上如何实现,文章参考《Computer Architecture:A Quantitative Approach》 和 CSE 240A 的课程 Slide [2] [3]。
为什么要引入 Tomasulo 算法?
Out-of-order 问题中 Tomasulo 常常和 scoreboard 进行比较,并且现在的计算机结构中也有 scoreboard 设计存在,比如 GPU 架构 [4],二者并非完全替代关系。在引入 Tomasulo 之前,有必要回顾一下基础背景。
IF-ID-EX-MEM-WB 简单五级流水线中,EX 执行依赖于一个 ALU,ALU 内部是由多种计算单元组成(INT-ADD、INT-MUL、FP-ADD...) 由 Multipliexer 进行选择,这种设计每种类型的计算单元的执行是互斥的,同一时刻只有一个单元可以执行,显然降低了计算利用率;其次为了保证流水线设计简单只是单向往前传数据(forwarding),WB阶段同一时刻只能有一个写入需求,而不同计算单元复杂度延时不同,为了避免同一时刻产生多个写入需求,会将 ALU 延时设置为最长的计算单元延时,当然这一点的影响远远小于前者, throughput 并行度重要性远远大于几个周期的 latency。
为了提高 结构利用率,让多个计算单元并行计算,引入了 scoreboard 算法。所以首先要引入某种存储机制记录每个计算单元的状态管理结构冒险;其次则是多个计算单元并行执行,会产生多个写入需求,读取-执行-写入阶段不能简单解耦。
至于数据冒险问题,无论简单流水线还是 scoreboard 都需要引入 stall 机制避免。而如之前 blog [5]所述,寄存器语言是隐式描述数据依赖关系,而非 Tomasulo 调度还是严格依赖寄存器描述冒险来实现依赖管理机制,其更多是一个实现,而非针对数据依赖发掘潜在的并行空间提高 throughput,这也是为什么要引入 Tomasulo 算法。
处理数据
首先明细几个概念
- 指令(Instruction):包含指令类型(ADD、MUL、LD、ST 等),输入:输入寄存器地址(Src Addr) 或是 立即数,目标寄存器地址(Dst Addr)。
- 当前指令(This Operator)以及先前指令(Operator)。标记指令的字段,可以唯一追踪到程序中的某条指令,一种方法是用在指令缓存中的地址表示。
- 保留站(Reservation Station)的输入:包含五个字段,当前指令、依赖指令1、依赖指令2、数据1、数据2。
寄存器重命名:从寄存器隐式依赖到 Producer-Consumer 依赖关系
再次重申,指令用寄存器表达依赖关系,而寄存器建立的依赖关系并非真正的依赖关系。
比如:
- 指令 1 -> 输出寄存器 A
- 指令 2 -> 输出寄存器 A
- 指令 3 <- 输入寄存器 A
可见指令3实际上依赖的是指令2的值,和指令1输出的值无关,但指令1和指令2输出共用了同一个寄存器,有可能因为伪依赖导致不能乱序执行。指令采用寄存器的方式传递指令间的信息本质时源于这符合物理描述,寄存器很容易映射到物理存储,但违背了逻辑描述。
逻辑上指令间的依赖关系用图表示,图依赖是建立指令之间的依赖(或者数据上的依赖),而非物理映射的存储地址。因此乱序思路是用指令信息表征依赖关系替代寄存器名称,这种方法叫做寄存器重命名。
实现分析
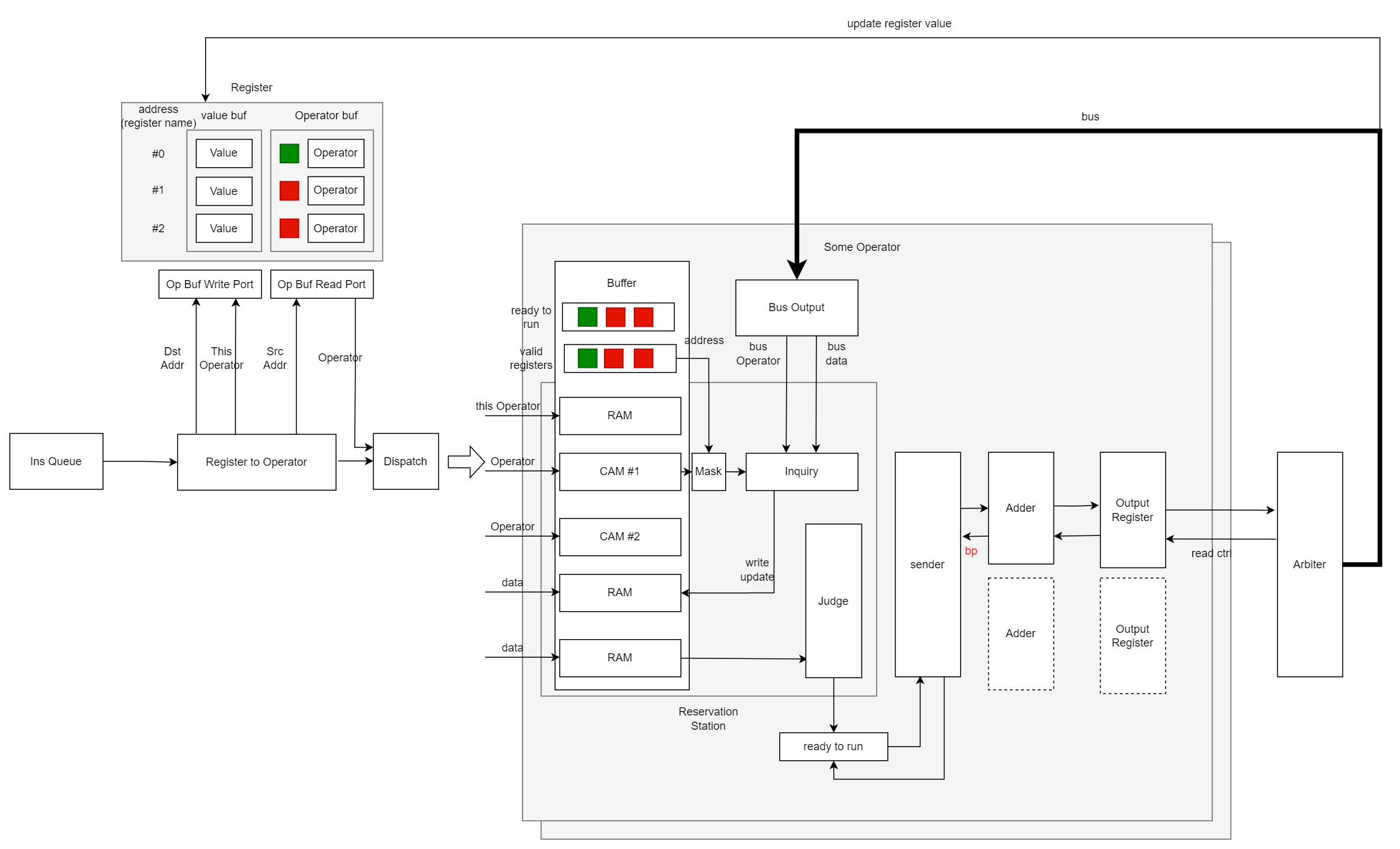
这是不带 Speculative Execution 的 Tomasulo 调度硬件原理图。
Register (寄存器->指令的映射)
寄存器重命名的实现有两个基础:
- 程序正确执行的判据: 乱序执行只需要保证程序执行完的状态量一致(各层 DRAM、Cache 、Register File 内的值),而中间状态变更的过程可以任意调整;
- 指令序列是因果序列: 后端执行的指令通过前端的 Instruction Queue 传入,Queue 表示程序是序列,同时是因果的,任意指令的输入寄存器都是由之前指令的输出寄存器所写入。或者说从依赖图转到序列的过程满足拓扑排序。
只要在从 Instruction Queue 读入指令时,用表示指令的字段替换掉寄存器存下来,而由于指令是因果的,当输入新指令时其的依赖指令一定已经存储下来了。可以说 Register 存储了 寄存器 -> 指令的 映射(地址->指令内容),使用一个额外空间存储追踪这种映射关系。
图中红色绿色表示这个 entry 的值是否有效,实际上只要保证 2 ,新输入的指令所读取的寄存器一定是以及保存过的,这个标志去掉也没问题。
Reservation Station
指令是序列输入的,而依赖是图构成的,序列一定会将一些没有依赖的节点排在前面,为了让不被前面的节点阻塞流水线。需要一个存储记录住还没执行的指令,并时刻检测一但条件满足立刻执行,这便是 Reservation Station。
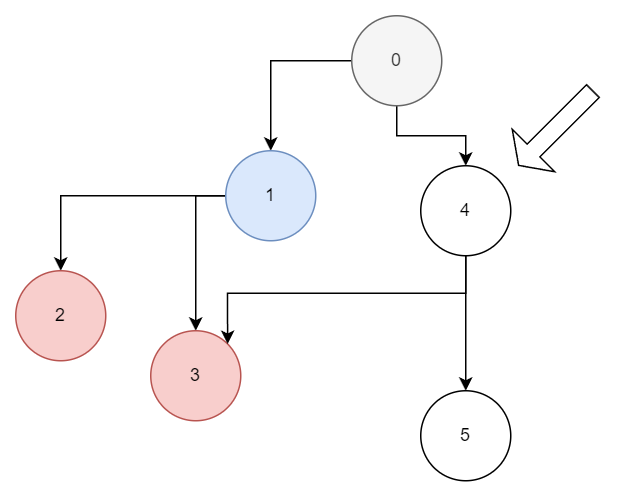
如图是程序依赖关系,每个节点是一条指令,节点的数字代表被塞入 Instruction Queue 的顺序,灰色代表已经执行的指令,蓝色是正在执行,红色是在 RS 里。当前正在时刻 4,此时 2 和 3 号程序在站点里休息等待 1 执行完毕。
从以上分析可知,需要一个物理存储让指令们休息,还需要一个判断机制让指令们离开。通过保存前级 register 映射的指令信息并通过监听数据总线(Common Data Bus)获取当前完成的指令。
另外,由于后继资源可能阻塞(比如多个执行单元对总线资源的占用),即使执行条件就绪也不一定就能立刻执行,因此还需要一个缓存记录可以执行的指令,并通过一个调度策略从中选择指令执行。
Others
执行单元不必多说。系统中同时有多个 RS 用于给不同种类指令休息,每个 RS 中保存的指令不重叠,没有 coherence 问题,但依赖关系应该是广播的,所以通过 CMB 广播消息。同时 CMB 也解耦了输入数据和寄存器堆,类似引入了旁路,但 RS 和寄存器堆内也可能对一个数据重复更新。
思考:Tomasulo 算法中软硬件的分工
Tomasulo 算法想要在现有寄存器语言描述的程序下,让硬件具有真正按照 producer-consumer 图结构解析执行的能力。要实现这种能力,需要消除两个传统编程体系中的问题,
- 解析出真正的数据依赖关系:通过各种信息形式的转换,寄存器 --(Register)--> 指令 --(Reservation Station)--> 数据 -- (执行单元) --> 数据。
- 将序列转换成图结构:通过 RS 同时监控多个节点上的指令,将满足条件的指令发射出去提高单元利用率,防止因为伪依赖卡住
进一步思考,为什么需要硬件实现这两个过程,这两个是否可以由软件完成呢?
去除寄存器
是否可以将这一个阶段放在编译器去实现呢?编译中不是也有个中间过程会将控制流展现为图的形式吗?如果在编译器阶段实现寄存器重命名,最多将伪依赖的寄存器分配一个可用另一个寄存器以避免依赖,但寄存器资源总是有限的,如果没有可用寄存器又还是卡顿。但编译器只能看到寄存器,RS 对编译器是透明的,而取决于 RS 的容量,只要使用带有寄存器的指令便是无法在现有指令上描述出来这种关系的。
寄存器描述特点是和物理实现一致,这个概念或许来自冯诺依曼体系“存储器”的大框架。因为寄存器符合物理实现与乱序的逻辑依赖相违背,只要使用寄存器表示就会遇到这个问题,
一种方法是指令集设计放弃使用寄存器建立指令间的依赖关系,而是直接用指令来描述,输入天然是一个图描述,或者添加额外的比特描述依赖关系。这种方法会对整个软件栈引发较大的变更;
另一种方法是增大寄存器数量,去除 RS,让编译器仅知道寄存器就可以管理数据依赖问题,但通用寄存器代价是非常高的,因为有相当多的结构会与其产生交互,这可能带来过大的硬件成本;
还有一种方法是将类似 RS 这种和计算单元相关的存储结构暴露给编译器,既提高了存储资源可以满足数据调度,RS 并非通用存储添加的边缘成本也相对更低,但此时转移到软件栈的也就只有调度模块了,而存储成本还是在硬件之上,这是否能够真正减少硬件开销需要细细分析。
去除序列
乱序执行是通过 RS 同时监控多个指令,将指令序列改成图的状态解析,从而实现乱序执行。序列性质反映在可以获取的上下文的数量上,比如队列只能获取看到一个指令,又或者 RAM 同一时刻只能获取一个地址,这都是序列性质,而 RS 监控到一个输出数据,会同时和内部保留的所有指令进行比较,上下文是一个窗口。那为什么指令是以序列的形式存在呢?
这本质还是来自处理器的资源,从大来说处理器是有限的空间流过无限的数据,也就是电路永远只能看到上下文的一小部分,而不是全貌,那么就要决定给处理器塞入指令的先后顺序;从小来说,接口、RAM 为了便于控制,其操作的基础粒度一般就是指令,而他们都是序列性质的硬件机制(此处可以对比 VLIW,理论上同一时刻粒度是多个指令)。只要是序列,就一定不能充分表达图的依赖关系,那么一定需要一个机制让硬件看到一个上下文窗口跳过序列 才能乱序执行。
由次可推,单纯靠乱序硬件也是无法彻底发掘图执行的最大效率,更大尺度的排序超出了硬件的窗口大小,仍需要编译器参与,但底层更大的 RS 容量可以分担部分编译器的压力。
只要使用寄存器描述指令集,最低控制粒度是指令level,那么寄存器重命名和乱序执行就得依靠硬件机制实现。在越来越强调 hardware-software co-design 的今天提供了一个非常好的例子,硬件并没有和软件争夺任务,而只是完成必须要硬件实现的本分,实现功能将更多的优化潜力暴露给软件。这是非常好的例子,硬件如果越界完成了本可以在软件层面完成的功能,虽然效能可能提升但会降低通用性也损失软件栈的可能,以眼前的性能牺牲了潜在的发展。如何划分软硬件的边界基础是透过表象仔细思考分析第一性原理。
思考:Tomasulo 所在的历史方位
各种硬件机制,目的都是为了提高算法性能,但就如 Amdahl's Law,不同的硬件针对的是不同 workload 特性,架构是一门 trade-off 的艺术,仅有当收益大于成本时引入机制才足够划算。此外任何一种形态的硬件都是完备的,比如 GPU 虽然提高并行计算,但也可以执行串行控制问题,传统流水线通过 stall 处理数据依赖,而 Tomasulo 通过解析更本质的数据依赖表达处理数据依赖。或者说,问题是不变的,在任何一个硬件形态上都能找到问题的解决方法,细细将所有硬件机制对不同问题的解决方案比较,才更好看清其引入的额外成本。
冒险是同时执行违反了相关性,所以冒险隐含了并行的含义。有结构冒险、数据依赖冒险、控制冒险,自然地将对应的并行机制定义为结构并行、数据依赖并行以及控制并行。
| 硬件机制 | 结构并行 | 数据依赖并行 |
|---|---|---|
| 简单流水线 | 无,计算单元执行互斥 | 无,冒险停滞流水线 |
| scoreboard | 引入额外针对计算单元的存储信息管理(scoreboard) | 无,冒险停止指令发射/写回 |
| Tomasulo | 引入额外针对计算单元的存储信息管理(RS) | 引入针对指令之间关系而非寄存器之间关系的信息管理(寄存器重命名) |
此外三者都没有针对控制冒险/并行问题改进,具体而言结合 BPU + Tomasulo 如果考虑 Speculative Execution,则需要一个额外的存储保存现场,一旦预测错误可以及时撤销,即将现在的寄存器堆用 Reorder Buffer 替代,在 Reorder Buffer 和寄存器间添加提交和撤销的机制。
针对不同的问题引入了不同的机制,换句话说,如果处理的该问题并不存在,那么该机制引入毫无意义。是否存在某种方法能够量化问题的影响程度呢?首先,遇到的问题之间并不一定是互斥的,一段指令可能既存在数据冒险也存在结构冒险,Amdahl's 将程序分为并行-串行两种实际是一种互斥的特例。实际问题的边界应该是类似集合的结构,可用韦恩图(Venn Diagram)。
假设存在问题 \(Q_0, Q_1, Q_2, ...\),某段程序 \(c\) 可能属于以上任意数量的问题 \(p\in \cap_{i} Q_{i}\),同时某段程序在整个程序中存在一个比例,该比例由不引入任何问题改进机制的 baseline 硬件执行开销所定义,将 baseline 硬件执行的结果用某个函数映射表示 \(p=P(c), p\in (0,1]\)。同时某种硬件针对不同的问题有对应的提升效率 \(\{Q_0, Q_1, Q_2, ...\} \rightarrow \{S_0, S_1, S_2, ...\}\),这一段程序的执行时间即:
程序总执行时间为:
也许日后可以用此类方法分析聚类某几类 workload 的问题特点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号