并行计算时代下的 Cache
熟悉的 AI 加速器领域 on-chip buffer 往往使用 scratchpad memory,对传统 cache 结构接触不多。但 cache 可谓是传统 CPU 架构中最最基础和重要的一个组件,从 cache 的设计思想上或许可以借鉴学习 AI 的访存问题。
SRAM + 映射 = Cache
基础结构
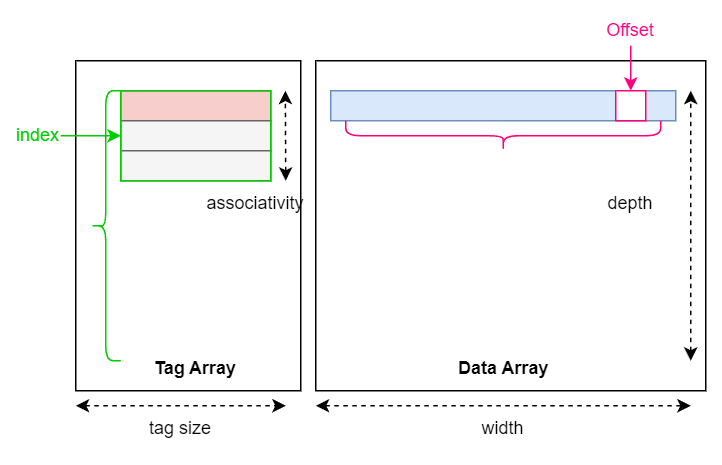
SRAM 容量小于 DRAM,故主存地址到 SRAM 地址是一个多射,Cache 则是在原本 SRAM (data array)的基础上,额外开辟了一个空间存储映射关系(tag array)。
当主存的访问地址传来,Cache 会将地址划分为三个部分:{tag, index, offset}。 Cache 对访问发出者 CPU 是透明的,即 CPU 看来只是发出了一个访问主存的地址,而没有所谓 tag/index/offset 的划分,Cache 的结构可以解耦于 CPU,更改 Cache 内部映射方式而不影响其他组件的控制逻辑。
Cache 中时间上最低粒度访问数据结构是 line,主存地址编码基础单位是 byte,找到一个 line 后根据 offset 再次选择到字节粒度。
每次对 cache 访问,首先查找 tag array 判断数据是否在 cache 中,如果命中(cache hit)就从 data array 中获取数据,否则(cache miss)就依照缓存协议进一步查询可能数据存放的位置,比如其他核的缓存或者主存。
映射复杂度
假设主存地址宽度为 \(a_{m}\) bit,一共有 \(A_{m}=2^{a_{m}}\) 个地址,可编码的主存容量为 \(2^{a_{m}}\) Byte;Data array 的数据宽度为 \(W_{d}\) Byte ,深度为 \(D_{d}\),容量为 \(DW\)。每一个 Cache 的 bit 平均面临着 \(\frac{2^{a_m}}{DW}\) 种可能的映射关系。请留意 \(X_m\) 和 \(X_d\) 的定义,我们后面还要反复提及。
主存访存粒度(Byte)和 Cache 访存粒度(Line)并不相同,但为方便分析,不妨将二者视作同粒度,毕竟本身主存 DDR 的数据宽度也不是单个 byte,byte 粒度更多是逻辑上。访存 data array 的地址是 \(X_{d}\) ,访存主存的地址是 \(X_{m}\)。对于某个 \(X_d\),有可能有多个 \(X_m\) 的映射是它,即 \(X_{m} \rightarrow X_{d}\) 是一个多射;而对于某个 \(X_m\) ,根据其对应的 \(X_d\) 数量可以划分为:Direct-Mapped、Set Associative、Fully Associative。
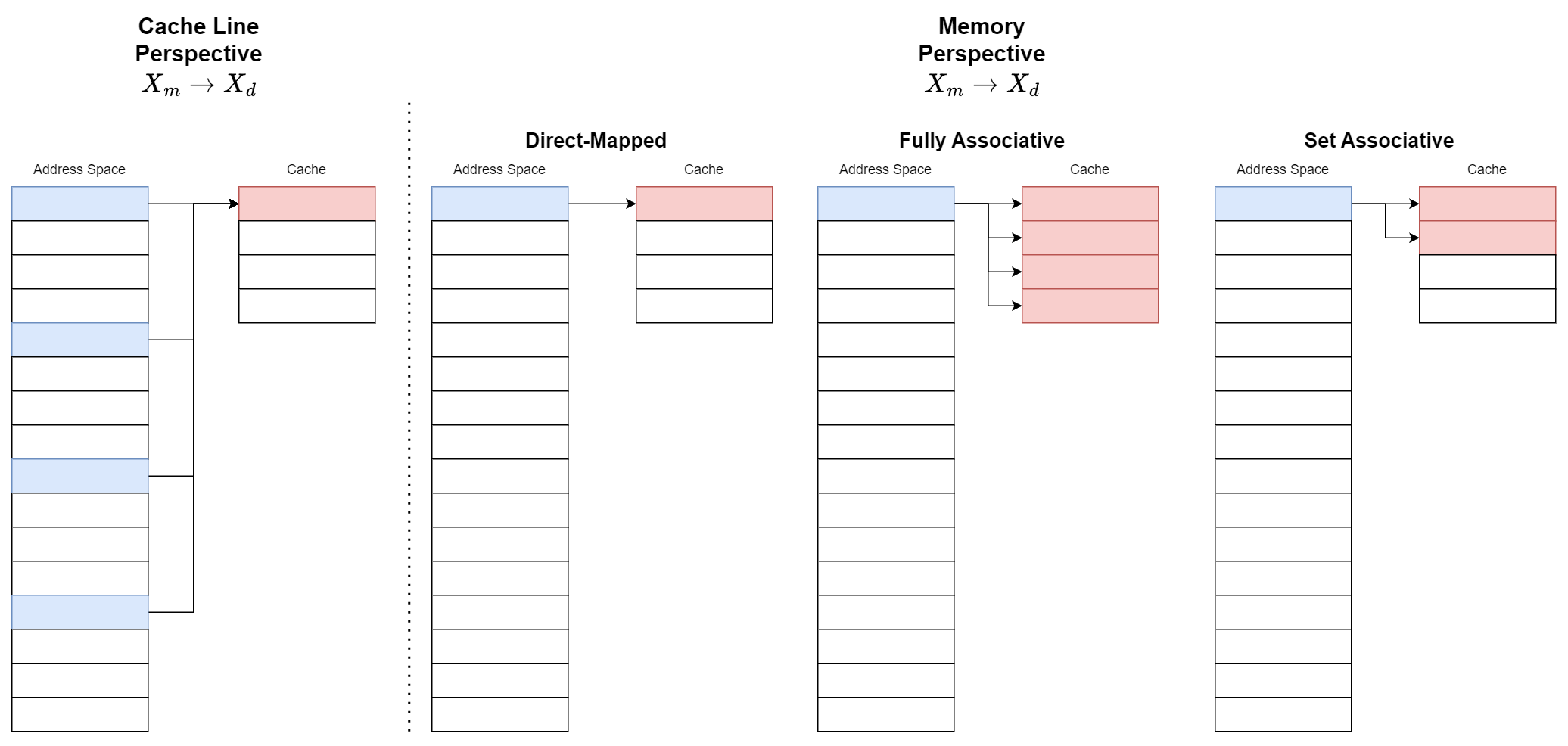
定义符号, \(N_S\) 为 associative,cache hit 的概率是 \(P(N_S)\), 比较 tag 的开销是 \(E_T\), 而 cache miss 的开销是 \(E_M\)。
为了限制查找的复杂度,一个 \(X_m\) 对应的 \(X_d\) 要有数量限制,将某个 \(X_m\) 可能对应所有的 \(X_d\) 的集合叫做一个 set,而 associative 为每个 set 中 line 的数量 。 每次查找 tag 的开销是读取出 \(N_S\) 数量的 tag 进行比较,这个复杂度是 \(O(N_S)\)。提高 associative,可以提高命中率,但同时每个 set 越大,每次要比较的数目也就越多。根据 associative 的值可称 N-way cache。
访问一次数据的期望是:
Cache 映射策略 trade-off 是在映射复杂度(cache 的成本)和 cache miss 代价(cache miss 概率,以及失效后果)之间抉择。最难地方根据 workload 对 \(P\) 命中率率进行建模。Cache miss 策略如果是访问主存,那么只需要提取 DDR 访问参数作为代价,但如果是要先通过缓存协议访问其他 cache,又会使得问题更加复杂。
Cache 的物理代价
为了直观体现 cache 带来的额外电路开销,选用 CACTI [1] 实验对比 cache 和 SRAM 的平均单次动态读写能耗以及面积。
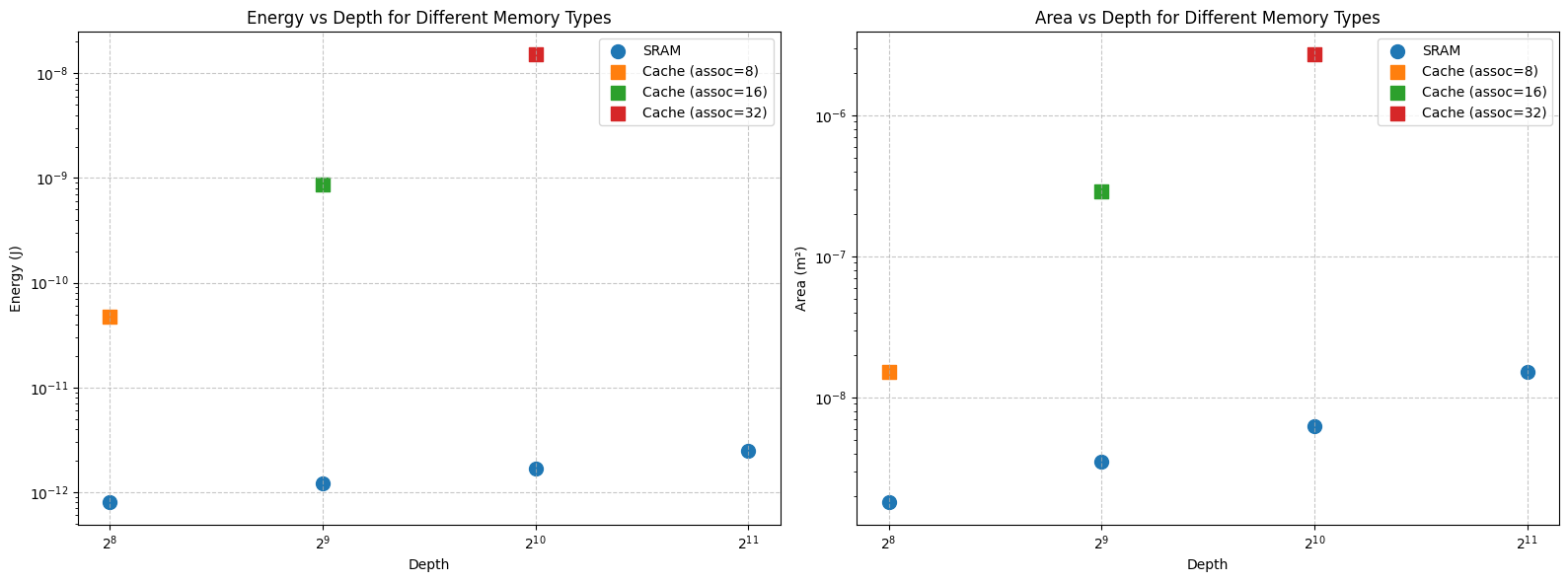
CACTI 的工艺结果比实际更加乐观,可能是因为 CACTI 工艺数据参考 ITRS-Roadmap。
控制变量工艺节点为 22nm,数据宽度为 64 bit,itrs-lstp 工艺类型,single port SRAM 类型,假设主存地址宽度为 32bit,tag 的宽度为 \(32-\log_2(64)-\log_2(\frac{D_d}{N_S})\) bit。Cache 和 SRAM 的开销有数个数量级之差。对 CACTI 不是很熟悉,不知是否实验过程有纰漏。根据先前分析的数据 [2],DRAM 取 64 bit 的能耗开销在 nJ 级别,图中 16-way cache 的访问能耗已和 DRAM 持平。
Why Cache
现在我们知道了如果要做 cache,是比较映射复杂度和 cache miss 的代价,可还没有分析清楚为什么要做 cache,换句话说,我们是否可以通过软件栈实现低容量到高容量存储的映射关系呢?什么情况下要用 scratchpad ,什么情况下要用 cache?
假设硬件中只有 scratchpad memory,软件不仅需要管理主存地址,还需要额外管理低层次 memory 的映射关系,这些映射关系终究还是存储在通用寄存器或是 buffer 之中,这样会增加访存指令数量,将 cache 的匹配查找机制显式转换成指令,增加指令数量。直观感受是不如硬化为硬件的,这部分就需要考古 cache 刚出来时候的文章了。
建立一个额外机制存储映射的需求来自映射的动态性或者不规律性,就好比基于查找表的函数和基于解析式的函数,如果访存的规律可以用某种解析式表达,只需要用极少数量的超参就可以动态生成访存地址。而 AI 计算模型尺寸是固定的,intra-kernel 的计算大都可用规律相对固定甚至 affine inner loop 表示,而想要引入不规律的映射特性可以从图的复杂度出发,做复杂的 inter-kernel 优化。此时 cache 的立意便是 intra-kernel 和 inter-kernel 之间的 trade-off , 这种 trade-off 是否能够站住脚呢?GPU 架构延续 CPU,从 cache 结构出发,并且很早就引入了统一 L1 Cache 和 Shared Memory,可在 SM 内部动态重构二者比例, 近期 Hopper 架构添加了 Distrbuted Shared Memory 支持 [3],进一步将 SM-SM 之间的访存通信暴露给软件端;而 AI 加速器自 DianNao 以来使用 scratchpad memory 优化 intra-kernel,近期逐渐将视角转向各种 inter-kernel fusion 机制 [4][5]。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号