量化存储墙 (二):数据流架构优化的瓶颈
先前 blog [1] 从能耗角度量化了现在计算问题本质是访存问题,同时提到由于算法和工艺的限制优化应当存在一个上限。这篇 blog 将结合具体 AI workload 探讨这个边界。
访存优化归类
各种加速工作优化核心在于将更多的操作放在底层低密度、低代价的 on-chip memory ,以避开高层 off-chip 高额延时、能耗访存代价。各类算法可用数据依赖图表示,图的问题是一个非常复杂的 NP 问题,所以这方面一直不能很好地用通用编译器自动化。计算图元素有 Opeartor 和 Operand,复杂的拓扑连接构成计算图。其中 Operator 必须映射到底层的执行单元计算,常常用 FLOPS 衡量;而 Operand 的交互访存映射在多层体系,展现并不直观。我对访存优化大致归为以下几种分类:
- 不修改 Operator,计算图的 Operator 直接映射到硬件,每个计算执行一次
- 修改 Operator
- Recompute:不修改执行的计算类型,但会增加计算的执行次数以优化访存
- 等价变换:通过数学的等价变换维持算法等价,但实际计算类型发生变化。经典工作比如 Flash Attention 引入额外的乘除法将 Attention 分块,某些无损压缩算法也应当归为这类。
先说说修改 Operator 的优化策略。Recomputation 当在内存中维持某个变量的代价太大,便重复计算动态生成,省去了在该变量生存周期之间的存储空间,但可能会带来维持生成该变量的依赖变量(有点绕)的额外存储代价,其立意的空间太特殊,尚没有看见很通用的分析工作;而等价变换涉及更多算法层面的 co-optimize,就更加依赖具体问题。本篇想要在切入得到一个较为通用的结论,因此这两种策略不纳入本篇讨论范围。
reuse 属于 intra-kernel,而 fusion 属于 inter-kernel。
reuse 涉及单个计算 kernel,优化空间相对较小,优化策略探讨非常详尽,毕竟深度学习就那么几个常用 kernel 算子,其中存在大量复用优化空间的也基本上就是矩阵乘法算子了;而 fusion 涉及复杂的图操作,见过的编译器算法还是将整个计算图取一个子图求解局部优化[4],更多工作还是靠人力优化,比如容易 fusion 的 element-wise 操作基本都默认写进各个加速框架的 kernel 库中了,而 kernel 种类有限,但 kernel 的组合是无穷的,新网络层出不穷,现在很大部分 accelerator 针对都是各种定制化网络算子的 fusion 或者说图的数据流优化。
Fusion 的适用空间
具体 fusion 和处理计算图以及硬件资源有很大关系,大致来说问题要满足以下两个条件:
- Producer-Consumer 角度: Fusion 的是相邻的 operator ,在底层的存储消耗压断变量生存周期消耗掉它,因此数据要满足在底层产生、底层消耗,实际上在深度学习语义中,这就是限定 activation 而非 weight;
- 保存成本低: 理想情况 Fusion 的变量是产生后立即消耗,非理想情况变量仍需要在底层的存储中存在一段时间,换句话说不是所有问题都能 mapping 到 spatial,temporal 映射不可避免,这段时间要为其分配额外的存储空间,额外的存储空间占用也会影响其余算子的优化空间。保存的代价可以用数据量和生存周期的乘积大致量化,这部分可见 MANIC [5] 中 forward buffer 和 kill distance 的设计。
神经网络中 weight 指代训练产生的固定权重,并非推理中由底层计算单元产生,并不满足第一点底层产生底层消耗,其数据内容来自整个训练数据集而非和推理时的具体情景;而 activatin 则指代推理动态产生的数据,其数据内容来自推理时的具体场景输入,比如摄像头的图片。然而,并非所有 activation 都可以 fusion 优化,有些 activation 由于数据量大且变量生存周期长,保存代价太大,必须写回高层高密度大容量存储释放底层空间,让底层 fusion 成本太高或者根本容量不够无法 fusion,比如 LLM 中的 KV Cache 部署的性质和 weight 更为接近。
接下来结合具体例子探讨 fusion 到底能够带来多大的优化。首先考虑最简单的模型,由 N 层恒等变换投影组成的 MLP,即只包括基础的 Linear 和 Activation 激活操作,恒等映射指 Linear 层输入和输出的维度一致,这样所有层 activation 和 weight 大小一致方便分析,比如传统 Attention 的 Q、K、V 投影。假设硬件存在物理资源可以在 spatial 上 mapping 中间的激活操作,activation 并不会引起额外的 kernel 调用,只 focus 在多个 linear 层的调度。
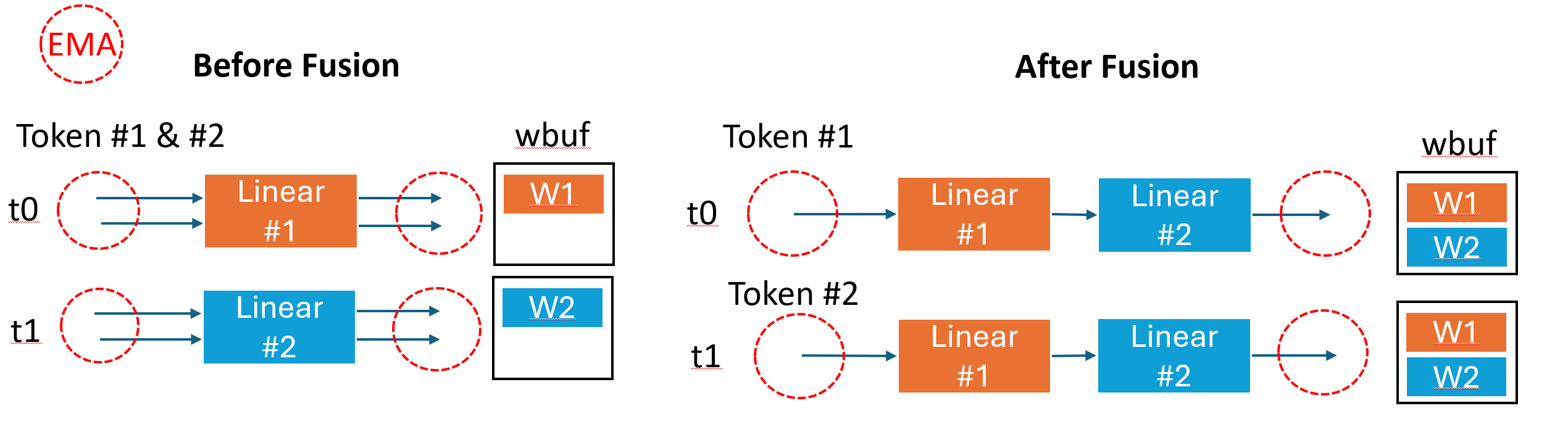
如上图两层 Linear Fusion 的前后对比,Fusion 后减少了 Linear1 和 Linear2 之间的 activation 读写,但代价是调度时存储中要保持所有权重数据,假设权重大小是 \(W\),那么两种情形权重部分所占据的存储容量是:
因为无论 Before Fusion 还是 After Fusion ,activation 调度上可以消耗掉。我们只考虑 weight 容量对存储的消耗。带有 weight 的算子 Fusion 是以牺牲存储空间为代价减少了激活值的访存,很显然是一个 Weight-Activation 数据量的比较。
假设单层 Activation 的容量大小是 \(A\) ,Before Fusion 计算 N 层读写 2N 次 A 大小的 activation,读取 N 次 W 大小的 weight,其对高层访存总量是:
After Fusion 后,计算 N 层读写 2 次 A 大小的 activaion,读取 N x M 次 W 大小的 weight,其 EMA 是:
在某些场景下(比如 vision 中的 depth predication、semantic segmentation 这些 dense predication 任务)activation 数据量很大,即使 fusion 后需要的 weight 的容量超出了片上 buffer,引来对 weight 的重复读取,但整体立意是否有可能还立得住呢。如果每次推理的 activation 并行度太小,每推理一次 activation 就要引发额外的 weight 读取,总共对 weight 读取会带来极大的存储访问,此时就不能单独考虑 weight 对存储空间的占用,还要考虑 feature 对存储的占用。
因此,考虑片上容量为 \(C\),假设一次 fusion 推理时处理的 activation 占据总量百分比为 \(\alpha\) ,比如一共 10000 个 batch,一次推理 100 个 batch, \(\alpha = 0.01\)。每 fusion 推理一次,需要读取 weight 次数 M 是:
其总 EMA 是
\(\Delta EMA =EMA_{before}-EMA_{after}\) 反映 fusion 优化的 EMA ,仅当其大于 0 时引入 fusion 才是有意义的。考虑要不要 Fusion 可以看作变化 N,N=1 即没有 Fusion,那么 Fusion 没有意义的数学命题是:在算法 {W,A} 、硬件资源 \(C\) 参数下,对于任意 \(\alpha \in (0, 1]\) 在 \(N=1\) 总有 \(\frac{\partial \Delta EMA}{\partial N} < 0\) 恒成立。
取整操作并不连续求导结果会传播成 0 或者没意义,用 STE [6] 方法将去掉取整符号后的表达式看作导数。那么有:
考虑 \(C-\alpha A\) 是剩余给 weight 的权重大小,其应当满足大于0,那么变换可得:
其中
所以该命题的一个充分条件是,当 \(C\) 小于 \(C_{thr}\) 时,Fusion 没有提升:
推导结论:EMA-Capacity 曲线
刚刚的推导只是讨论要使得 Fusion 能够优化 EMA 所需要的临界 buffer 容量,提升 1% 也是提升,但没有必要。优化的访存数量至少能够和原有访存总量在一个数量级,因此修改假设
\(\lambda \in [0,1]\),表示优化访存占原有访存的比例,能得出此时的 \(C\) 满足:
若假设取临界 \(C=\frac{1}{1 - \lambda}C_{thr}\) 有(这事实上将之前的必要条件近似为了充要条件):
该方程表示当 Fusion 有效时系统的访存,即 \(C > C_{thr}\),当 \(C < C_{thr}\) 时,Fusion 没有提升,此时 EMA 仍等于 \(EMA_{before}\)。
因此
这便是 EMA-Capacity 曲线:
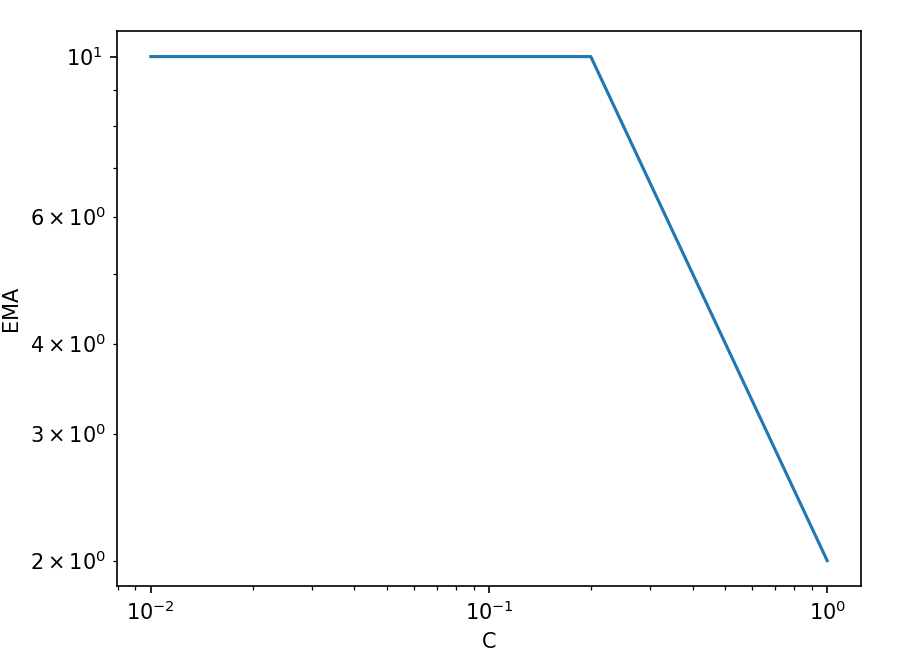
显然随着片上存储容量增大,访存并不会无限趋近于 0,系统应当有一个 lower bound,lower bound 的预测失误或许来自近似条件不合理。优化访存的部分呈现反比关系,即存储容量每扩大 10 倍,EMA 变为原来的 1/10。反比关系曲线应当是优化空间较大时成立,在 fusion 语义下既是此时 activation 占据主要总访存比例,可以类似 bode 图给出一个经验的右端点修正这条经验曲线。
值得一提的是,去年 NVIDIA [7] 也给出了一个 Buffer Size 和访存次数的曲线,不过他们是适用遍历方法得出的,而且考虑的加速技巧也不完全一致(既有 intra-kernel mapping 也有 inter-kernel fusion),但 EMA 和访存的曲线关系似乎符合相同的曲线关系,长着像一个转置的 Roofline 模型。
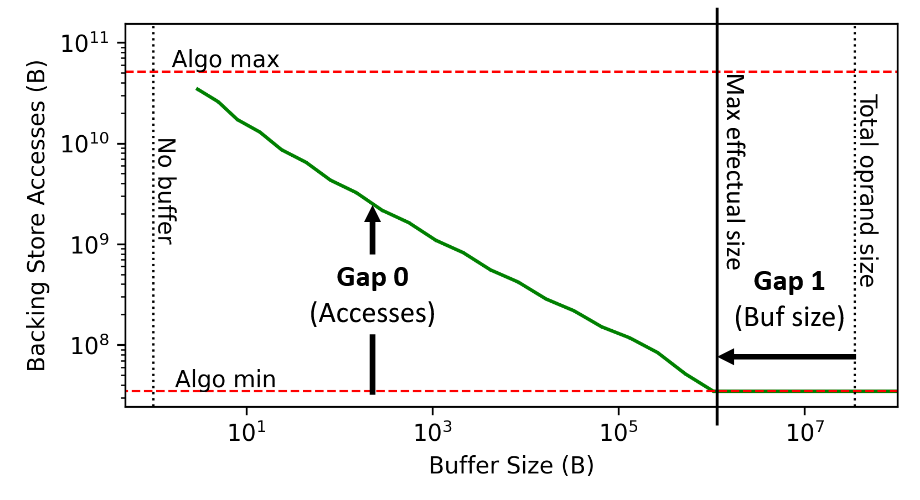
on-chip 架构优化的边界
当存储容量小于 \(C_{thr}\) 时,Fusion 反而会带来存储读写损失。这个阈值和具体的任务高度相关。
举例加速器常见的图像视觉任务和 NLP 任务,
- 模型大小:视觉一直没有复现 NLP 领域上自回归训练产生的大模型,常用模型尺寸较小,像 CLIP 、DINO 这类标准 tokenizer 已经算大也就 100M 的数量级,而 NLP 任务往往模型较大,主流模型至少要 7B 性能才刚刚够看,常用尺寸主要还是 32B ~ 百B 量级。更大的模型往往扩张 embedded dimension,单层权重更大
- 推理范式:视觉任务天生输入就有并行的依赖偏置,可以并行处理,一次推理激活值并行度较高,且金字塔结构浅层的权重容量小、激活容量大,非常适用 fusion 处理;而 NLP 任务源自语音先后因果顺序的依赖偏执,往往采用自回归范式推理,在 decode 阶段不考虑服务器端多用户请求扩大 batch,边缘端激活值并行度较低。
取两个领域经典模型维度分析,假设 Activation 和 Weight 都用 8bit 量化。视觉 CLIP [8] 采用 ViT-base 架构,embedded dimension 为 512 ,patch size 是 32,假设浅层的 Linear 层输入图像尺寸是 512x512 ;NLP 采用 7B/32B 的 DeepSeek-R1 [9] [10],假设 activation 取 hidden size 作为 embedd dimension = 3584/5120 (若取 intermediate size 更加夸张),模拟 decode 阶段由于自回归一次只能推理一个 token。实际上两个模型都没有直接对应理论分析的理想多层恒等映射结构,这里也没必要分析太过细致,取数量级感性分析即可。
| Model | Activation Dimension | Weight Dimension | Activation Size(Byte) | Weight Size(Byte) | Thershold(Byte) |
|---|---|---|---|---|---|
| CLIP 86M | [(512/32)**2, 512] |
[512,512] |
128K | 256K | 256 K |
| DeepSeek-R1 7B | [1, 3584] |
[3584,3584] |
3.5K | 12544K | 24.49 M |
| DeepSeek-R1 32B | [1, 5120] |
[5120,5120] |
5K | 25600K | 50 M |
86M 的 CLIP 在视觉推理加速器中已经算一个不小的参数量了,感性估计也只需要 ~200KB 量级的片上存储就有 fusion 优化的空间,而 7B 模型在 NLP 中只能算小块头了,却需要 ~20MB 片上存储才有优化空间,要知道 H100 这种量级也才片上 50MB L2 Cache,且这个阈值只是充分条件下的刚刚能有优化空间,实际容量还得再高于这个值才能保证有价值优化,考虑 NLP 主流模型容量和片上硬件资源,在主流 LLM 自回归推理的的范式下,架构数据流优化空间有限,主要还是卡在最大容量的片外带宽 [11]。
对于多层存储体系而言,只有当系统的短板不在片外访存时,做片内架构优化才有意义,而在自回归的 LLM 领域大部分开销来自于片外的 weight 访存,可优化空间并不多。投入再多的架构设计,也许不如直接购买更高级的 DDR/HBM 接口 IP 对总体 TCO 更为有益。
展望未来
前文在现有算法和工艺参数的约束下推导出 on-chip 架构优化空间有限,那么这个前提是否有可能变化呢?现在的 on-chip memory 密度不够很难达到算法规定的优化门槛,但是最近一直有各种大芯片 [12] 工作,大力出奇迹在空间上叠高容量 buffer,是否未来有可能放得下呢?
首先是模型参数角度,假设 scaling law 成立,那么片上存储和算法容量的竞争实际上是片上存储和 DDR HBM 等高容量存储的竞争,模型也是训练出来的,模型的容量实际上反映了最大的计算集群的容量,而计算集群的容量取决于高容量存储,从这个角度 on-chip 存储发展速率要超过 off-chip 存储,但这是不可能的,因为本身就是 on-chip 和 off-chip 的物理约束导致了存储介质发展路线的不同,如果 on-chip 存储能在维持带宽能耗优势仍在的情况下密度超过 off-chip,产业就不会有 off-chip 存储这个东西。不过 scaling law 最近在 LLM 上边缘收益不断递减,GPT 4.5 就是最好的证明,另一层面模型的知识密度也在不断提高,容量不变模型性能也在不断增强,这都是好的趋势。
另一层面是 on-chip 存储容量是否会继续增长?各种 memory 粗糙的调研数据如下:
| Memory Type | Year | Density (bit/mm2) | Bandwidth(GB/s) | Power(pj/bit) |
|---|---|---|---|---|
| NAND Flash[13] | 2022 | 8.5 G | ~5.8 | |
| HBM2 [14] [15] | 2016 | 11.13M / Cores | ~1000-2000 | 3.9 |
| GDDR5 [15:1] | 2015 | 0.1 G | ~500 | 14 |
| DDR4 [16][17] | 2020 | 0.102 G | ~10-30 | ~20-70 |
| SRAM-T7[18] | 2018 | 0.037 G | ~10000 | ~0.1 |
存储性能受具体设计变化极大,特别是 DDR 密度依赖堆叠层数,数据只用以感性理解数量级的差距。HBM 可以认为只是 DDR 改进了封装,因此只提升了带宽性能,cell 存储密度应与 DDR 接近
数据上反映 SRAM 的密度只与 DRAM 密度相差 3x,实际上倍数远远超过这个值(衡量外围电路、DDR 的层数等等),WSE-3 [19] 这种 46000 mm2 的大家伙大概有 40GB 的片上存储,而 32 GB 的 DDR die size 在 100 mm2 的量级,实际应该是 10x 这个数量级的差距。由于本身 off-chip 工艺更加成熟, WSE-3 通过横向扩展增大片上存储额外的良率、封装、软件栈等成本是否能够在 TCO 上立住不好说,毕竟有多少公司能够做出 wafer 级别的芯片呢?那么另一个方向就是增大存储的密度,本身数字工艺发展收敛已是事实,而 SRAM 工艺改进还慢于逻辑改进 [20](可能是由于 SRAM 内部的模拟部分导致无法维持数字相同速率 scaling ),2D SRAM 很难再继续 scaling 了,剩下唯一的路子,就是往 3D 方向堆叠。去年诞生了地表最强游戏U 9800X3D ,十分期待未来还能整出什么活。
前面所有角度都是假设架构设计只能影响 on-chip memory,考虑传统的 "off-chip" 也有集成 3D chip 的趋势,将计算和存储在同一个水平坐标上集成,也就是 DRAM-level 的存算。但无论是 "on-chip" 3D 堆叠,还是 "off-chip" PIM 存算,可能遇到的问题都是相似的,待日后再调研学习了。
https://docs.sambanova.ai/developer/latest/compiler-overview.html ↩︎
https://huggingface.co/openai/clip-vit-base-patch32/blob/main/config.json ↩︎
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B ↩︎
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B ↩︎
https://www.techpowerup.com/ssd-specs/zhitai-tiplus7100-1-tb.d1250 ↩︎
https://www.anandtech.com/show/9969/jedec-publishes-hbm2-specification#:~:text=HBM2 memory stacks are not ,cooling%20for%20high%20bandwidth%20memory ↩︎
https://www.techinsights.com/products/mdp-2006-801#:~:text=module. The CXMT CXDQ3A8AM ,102%20Gb%2Fmm2 ↩︎
https://fuse.wikichip.org/news/2408/tsmc-7nm-hd-and-hp-cells-2nd-gen-7nm-and-the-snapdragon-855-dtco/#:~:text=SRAM ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号