冰山之下:ICAC 2.5D/3D 互联课程记录
去 ICAC 蹭完饭有一阵了,懒癌发作拖到现在才做心得总结。ICAC 印象最深刻的是复旦陈迟晓老师带来的 《2.5D/3D/3.5D Integration: Fabrication and Chiplet Partition》 演讲。因为先前纯数字架构接触更多一些,对 chiplet 更多是门外汉,本篇也抱着不求甚解的态度记录一下。
互联层次
与存储层次结构类似,互联层级越往高层带宽越小,呈现一种多层层次化同质化结构。说同质是指它们功能相同,根据应用场景具体需求(和资金)可 trade-off 选择 mapping 到不同实现。按照互联密度由高至低依次排序如下:
- die 内互联:die 内走线通过 metal layer 当走线实现的最高密度互联,此互联上限受限于良率公式规定的 die size;
- die 与 die 互联:包括 2.5D 集成的 bridge 以及 3D 集成的 TSV 或者 face-to-back 互联;
- IO 到封装:从 IO 引到封装管脚,比如 wire bonding 或者是 flip-chip;
- PCB 互联:受限于 PCB 制造工艺走铜宽度、信号完整性
各种互联的呈现关系和实际生产的设计、制造高度耦合,比如以各个层次的 bump size 举例子:
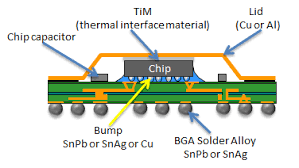
上图是 flip chip 封装简图,图中就出现了两种尺寸的 bump,黄色所指从芯片引出来的 bump 以及从封装引出来到 PCB 的 BGA bump。
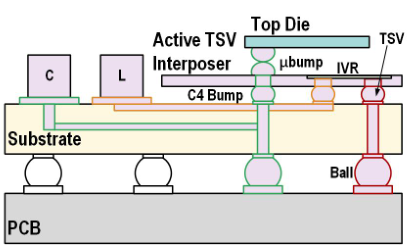
引用陈老师组 2025 ISSCC SHINSAI [1] 的图片,包含了三种尺寸的 bump:
| 名称 | 层级 | 尺寸 |
|---|---|---|
| ubump | die-interposer | 40um |
| C4 Bump | interposer-substrate | 100 um |
| BGA Ball | substrate-PCB | 200~600 um |
数据比较抽象,举个例子,SHINSAI 在 28nm 下流片,28nm 常见厂 IO pad 尺寸在 20um 左右,ubump 尺寸对应 IO pad 的制造层级;而 BGA Ball 的数量级大致在 0.5mm,焊板子常见的 0402 中 02 指的就是 0.02inch = 0.5mm。
作为一名门外汉,我最好奇的还是新颖的 N-D 互联能够提升多少带宽呢?以下通过简化模型对比 2D、2.5D、3D 三种方式,互联的带宽 \(b\) 可以用互联密度 \(\lambda\) 乘以空间尺寸 \(x\) 即 \(b=\lambda x\)。2D 空间尺寸是die的周长,2.5D 空间尺寸是芯片面积,因为两个芯片投影面积不重叠还要除以 2,而 3D 芯片则是等于芯片面积,并且 3D 芯片还可以随着层数增加。
流片良率限制有个面积上限,不妨假设流片面积 \(A\) 在 100mm2,采用先前的 20um IO pad 的数据,互联线密度为 \(1\text{bit}/20\text{um}\),互联面密度为 \(1\text{bit}/(20\text{um})^2\)。2D 芯片周长大致看作正方形 \(4\sqrt{A}\),3D 芯片层数为 \(L\),计算一个偏高的数据:
| 集成方式 | 密度公式 | 互联位宽(bit) |
|---|---|---|
| 2D | \(4\lambda\sqrt{A}\) | 2k |
| 2.5D | \(\lambda^2A/2\) | 125k |
| 3D | \(\lambda^2A (L-1)\) | 250k(L=2) |
从实际生产出发
这场 workshop 最惊喜莫过在于硬知识之外的小故事。前文也提到各种互联和实际设计、制造高度耦合相关,本身就已经牵扯到 fab 厂和封装厂两个阶段配合,考虑设计变量还会牵扯多种节点工艺、多种互联工艺同时集成在一个芯片之上。陈老师分享了 AMD / Intel 服务器领域的一个故事:

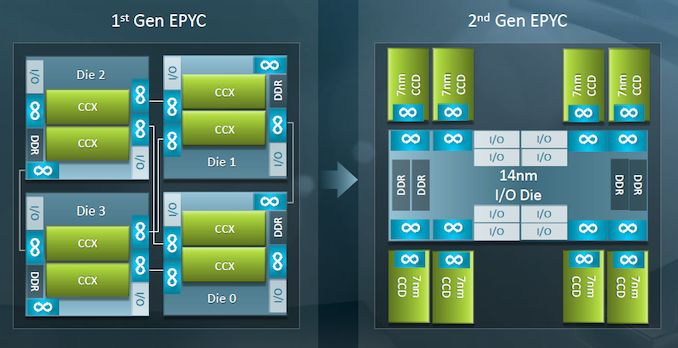
上图分别是 Intel Sapphire Rapids 和 AMD EPYC 这 die shot 也太帅了。Intel Sapphire 每个 core 采用相同的同构设计,而 AMD EPYC 到了二代则将通信和 logic die 分离在不同节点流片的异构设计。AMD 异构的使用可以从几个方向解读:
- 历史原因的影响: Global Foundries 是从 AMD 制造部分离出去的,AMD 在 GF 有营业额规定要流多少产额,但 GF 技术力受限(现在 GF 已退出 7nm 以下先进节点竞争)先进节点并不成熟,所以将设计划分为 14 nm 和 7 nm 两种 die 在不同的 fab 分别流片;
- 成本的选择: 随着晶体管逐渐逼近物理极限,晶体管加工难度越来越大,在先进节点上每个晶体管成本逐渐上升,并不是越先进越好,根据选择一个性能-成本平衡的节点商业潜力更大。陈老师这里还举了一个 Intel 异构的例子,fab 会根据市场选择下一代节点技术路线,Intel 在 22nm 和 10nm 之间没有一个成熟的工艺,吃不下这部分节点对应的市场,所以采用 22nm + 10nm 的异构设计取一个 trade-off;
- 上层应用的特性: 通信功能较为成熟,而且对工艺节点需求较低;而逻辑功能对工艺节点敏感。
每个决策背后都是复杂因素综合结果,实际情况究竟是哪一种很难得知。但这些决策大致归结于两个主要因素:商业和技术限制。比如 Silicon Interposer 相比 RDL Interposer 互联密度高,但物理结构脆弱难以 scaling 并且造价昂贵,所以现在演进了整体使用 RDL Interposer ,局部用 Silicon Bridge 提供高带宽的“胶水”路线。整体路线的决策受商业成本、材料特性多种影响。
提及这点是想给自己近期做 AI 加速器方向提一个醒,这个方向虽然是硬件领域,但实际上很多定制加速器第一性是来自于软件,出一个新模型提一个新架构。传统培养数字设计和后端解耦专注于逻辑功能,但随着工艺逐渐达到晶体管极限,逻辑、工艺后端、互联、封装上下游似乎在逐渐加强耦合探索更多优化空间。本身半导体底层是受制于器件材料工艺,本身发展相对软件较为缓慢,以软件为第一性方向,本身软硬件从业人数对比就不平衡,可以提供肩膀的“巨人”就更少,而底层不断在变动,概念也来不及充分研究甚至会和软件抢风头,工作积累的连续性也很有挑战。到底从哪个角度立足来做硬件值得未来长期思考。
冰山之下
陈老师有提到复旦 2020 年起步做这个方向,当时各个工艺还不成熟,TSV 的 keep-out zone 甚至没有 design rule。扎根于硬件的研究其中具体而深刻的问题很多都是要接触才能得知,可全国又有多少实验室能流片,能流片的实验室里又有多少可以和厂商高度合作生产先进技术?SHINSAI 一作在知乎介绍了流片的心路历程 [2],其中各种工程管理问题在 tapeout 中倍感现实,在敬佩之余,又不禁感慨其成功难以复刻。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号