随笔分类 - 深度学习
与MindSpore相关或者与深度学习相关的一系列算法,会统一放到该分类下
摘要: 在往期关于DeepSeek的模型部署、KTransformer的安装与使用、PageAssist和OpenClaw的相关应用部署的基础之上,本文我们再讲述一个新版的KTransformer部署最新的BF16精度的Qwen3-Coder-Next模型的一些技术方案和操作指引。
阅读全文
在往期关于DeepSeek的模型部署、KTransformer的安装与使用、PageAssist和OpenClaw的相关应用部署的基础之上,本文我们再讲述一个新版的KTransformer部署最新的BF16精度的Qwen3-Coder-Next模型的一些技术方案和操作指引。
阅读全文
在往期关于DeepSeek的模型部署、KTransformer的安装与使用、PageAssist和OpenClaw的相关应用部署的基础之上,本文我们再讲述一个新版的KTransformer部署最新的BF16精度的Qwen3-Coder-Next模型的一些技术方案和操作指引。
阅读全文
摘要: 本文重点介绍了一下如何在PyTorch中去计算一个高维tensor的大小,也就是元素的总数。在其他框架中我们需要使用size函数来获取,而在PyTorch框架中这个接口被调整为numel,本文给出了两个具体代码示例。
阅读全文
本文重点介绍了一下如何在PyTorch中去计算一个高维tensor的大小,也就是元素的总数。在其他框架中我们需要使用size函数来获取,而在PyTorch框架中这个接口被调整为numel,本文给出了两个具体代码示例。
阅读全文
本文重点介绍了一下如何在PyTorch中去计算一个高维tensor的大小,也就是元素的总数。在其他框架中我们需要使用size函数来获取,而在PyTorch框架中这个接口被调整为numel,本文给出了两个具体代码示例。
阅读全文
摘要: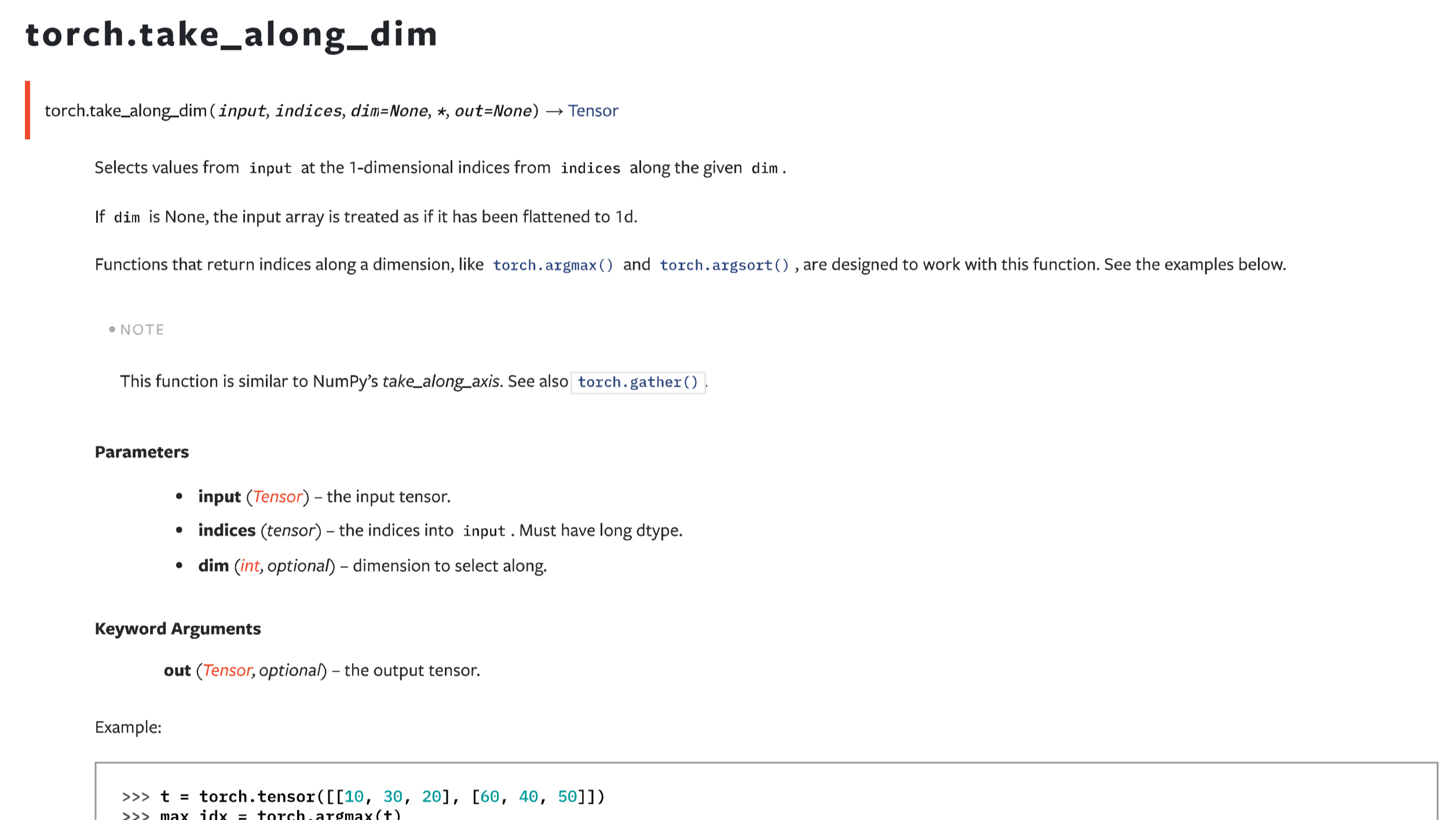 接前面一篇take_along_axis的文章,本文主要介绍在PyTorch框架下,功能基本一样的函数take_along_dim。二者除了命名和一些关键词参数不一致之外,用法是一样的。需要注意的是,两者都要求输入的数组和索引数组维度数量一致。在特定场景下,需要手动进行扩维。
阅读全文
接前面一篇take_along_axis的文章,本文主要介绍在PyTorch框架下,功能基本一样的函数take_along_dim。二者除了命名和一些关键词参数不一致之外,用法是一样的。需要注意的是,两者都要求输入的数组和索引数组维度数量一致。在特定场景下,需要手动进行扩维。
阅读全文
接前面一篇take_along_axis的文章,本文主要介绍在PyTorch框架下,功能基本一样的函数take_along_dim。二者除了命名和一些关键词参数不一致之外,用法是一样的。需要注意的是,两者都要求输入的数组和索引数组维度数量一致。在特定场景下,需要手动进行扩维。
阅读全文
摘要: 本文简单的介绍了一个在Pytorch中对张量进行逆序操作的方法相比于其他的框架,例如numpy和mindspore等的区别。在其他框架中我们可以直接使用slice的方法对一个张量做逆序,但是在Pytorch中,可能需要使用到一个flip函数。
阅读全文
本文简单的介绍了一个在Pytorch中对张量进行逆序操作的方法相比于其他的框架,例如numpy和mindspore等的区别。在其他框架中我们可以直接使用slice的方法对一个张量做逆序,但是在Pytorch中,可能需要使用到一个flip函数。
阅读全文
本文简单的介绍了一个在Pytorch中对张量进行逆序操作的方法相比于其他的框架,例如numpy和mindspore等的区别。在其他框架中我们可以直接使用slice的方法对一个张量做逆序,但是在Pytorch中,可能需要使用到一个flip函数。
阅读全文
摘要: 本文介绍了在PyTorch中直接使用幂次函数计算有可能导致的计算结果异常的问题。由于PyTorch中并未像Numpy和MindSpore一样直接支持cbrt开立方函数,因此这里也提供了一个在PyTorch中计算开立方的函数。
阅读全文
本文介绍了在PyTorch中直接使用幂次函数计算有可能导致的计算结果异常的问题。由于PyTorch中并未像Numpy和MindSpore一样直接支持cbrt开立方函数,因此这里也提供了一个在PyTorch中计算开立方的函数。
阅读全文
本文介绍了在PyTorch中直接使用幂次函数计算有可能导致的计算结果异常的问题。由于PyTorch中并未像Numpy和MindSpore一样直接支持cbrt开立方函数,因此这里也提供了一个在PyTorch中计算开立方的函数。
阅读全文
摘要: 本文介绍了MindSpore中的tensor_scatter_add算子的用法,可以对一个多维的tensor在指定的index上面进行加和操作。在PyTorch中虽然也有一个叫scatter_add的算子,但是本质上来说两者是完全不一样的操作。
阅读全文
本文介绍了MindSpore中的tensor_scatter_add算子的用法,可以对一个多维的tensor在指定的index上面进行加和操作。在PyTorch中虽然也有一个叫scatter_add的算子,但是本质上来说两者是完全不一样的操作。
阅读全文
本文介绍了MindSpore中的tensor_scatter_add算子的用法,可以对一个多维的tensor在指定的index上面进行加和操作。在PyTorch中虽然也有一个叫scatter_add的算子,但是本质上来说两者是完全不一样的操作。
阅读全文
摘要: 本文通过2个实际的案例,演示了一下gather算子在MindSpore框架下PyTorch框架下的异同点。两者的输入都是tensor-axis-index,一个是输入顺序上略有区别,另一个是对于输入的张量索引维度的要求。在PyTorch中,如果我们要实现类似于MindSpore中的gather功能,需要手动对输入索引的维度操作一下。
阅读全文
本文通过2个实际的案例,演示了一下gather算子在MindSpore框架下PyTorch框架下的异同点。两者的输入都是tensor-axis-index,一个是输入顺序上略有区别,另一个是对于输入的张量索引维度的要求。在PyTorch中,如果我们要实现类似于MindSpore中的gather功能,需要手动对输入索引的维度操作一下。
阅读全文
本文通过2个实际的案例,演示了一下gather算子在MindSpore框架下PyTorch框架下的异同点。两者的输入都是tensor-axis-index,一个是输入顺序上略有区别,另一个是对于输入的张量索引维度的要求。在PyTorch中,如果我们要实现类似于MindSpore中的gather功能,需要手动对输入索引的维度操作一下。
阅读全文
摘要: 本文介绍了在pytorch和mindspore中两种计算张量最大值的算子,如果直接使用max算子,两者的输出都是最大值元素和最大值索引。但是mindspore中额外的支持了ReduceMax算子,可以允许我们只输出最大值而不输出最大值索引。
阅读全文
本文介绍了在pytorch和mindspore中两种计算张量最大值的算子,如果直接使用max算子,两者的输出都是最大值元素和最大值索引。但是mindspore中额外的支持了ReduceMax算子,可以允许我们只输出最大值而不输出最大值索引。
阅读全文
本文介绍了在pytorch和mindspore中两种计算张量最大值的算子,如果直接使用max算子,两者的输出都是最大值元素和最大值索引。但是mindspore中额外的支持了ReduceMax算子,可以允许我们只输出最大值而不输出最大值索引。
阅读全文
摘要: 本文通过几个示例,介绍了在Python、Numpy和PyTorch三个不同的框架下,对于求余数函数的定义。比较特殊的是pytorch中的fmod函数,并不符合数学上的求余数方法,而是需要使用remainder函数。
阅读全文
本文通过几个示例,介绍了在Python、Numpy和PyTorch三个不同的框架下,对于求余数函数的定义。比较特殊的是pytorch中的fmod函数,并不符合数学上的求余数方法,而是需要使用remainder函数。
阅读全文
本文通过几个示例,介绍了在Python、Numpy和PyTorch三个不同的框架下,对于求余数函数的定义。比较特殊的是pytorch中的fmod函数,并不符合数学上的求余数方法,而是需要使用remainder函数。
阅读全文
摘要: 接上一篇对于MindSpore-2.4-gpu版本的安装介绍,本文主要介绍一些MindSpore-2.4版本中的新特性,例如使用hal对设备和流进行管理,进而支持Stream流计算。另外还有类似于Jax中的fori_loop方法,MindSpore最新版本中也支持了ForiLoop循环体,使得循环的执行更加高效,也是端到端自动微分的强大利器之一。
阅读全文
接上一篇对于MindSpore-2.4-gpu版本的安装介绍,本文主要介绍一些MindSpore-2.4版本中的新特性,例如使用hal对设备和流进行管理,进而支持Stream流计算。另外还有类似于Jax中的fori_loop方法,MindSpore最新版本中也支持了ForiLoop循环体,使得循环的执行更加高效,也是端到端自动微分的强大利器之一。
阅读全文
接上一篇对于MindSpore-2.4-gpu版本的安装介绍,本文主要介绍一些MindSpore-2.4版本中的新特性,例如使用hal对设备和流进行管理,进而支持Stream流计算。另外还有类似于Jax中的fori_loop方法,MindSpore最新版本中也支持了ForiLoop循环体,使得循环的执行更加高效,也是端到端自动微分的强大利器之一。
阅读全文
摘要: 本文介绍了在Ubuntu-20.04系统下安装最新的MindSpore-2.4-for-GPU版本的方法,以及安装过程中有可能出现的一些问题。虽然在MindSpore的正式版本中已经不再支持GPU硬件后端,但是开发版本目前还是持续在支持的,并且其中包含了2.3和2.4版本的新特性,只是算子层面没有更新和优化。对于GPU后端的MindSpore用户来说,也算是一个好消息。
阅读全文
本文介绍了在Ubuntu-20.04系统下安装最新的MindSpore-2.4-for-GPU版本的方法,以及安装过程中有可能出现的一些问题。虽然在MindSpore的正式版本中已经不再支持GPU硬件后端,但是开发版本目前还是持续在支持的,并且其中包含了2.3和2.4版本的新特性,只是算子层面没有更新和优化。对于GPU后端的MindSpore用户来说,也算是一个好消息。
阅读全文
本文介绍了在Ubuntu-20.04系统下安装最新的MindSpore-2.4-for-GPU版本的方法,以及安装过程中有可能出现的一些问题。虽然在MindSpore的正式版本中已经不再支持GPU硬件后端,但是开发版本目前还是持续在支持的,并且其中包含了2.3和2.4版本的新特性,只是算子层面没有更新和优化。对于GPU后端的MindSpore用户来说,也算是一个好消息。
阅读全文
摘要: 这篇文章主要介绍了mindspore深度学习框架中基于InsertGradientOf算子的进阶梯度操作。InsertGradientOf算子的功能跟此前介绍过的bprop功能有些类似,也是自定义梯度,但bprop更倾向于计算梯度,而InsertGradientOf算子更倾向于修改梯度,这里介绍了一些比较详细的测试案例。
阅读全文
这篇文章主要介绍了mindspore深度学习框架中基于InsertGradientOf算子的进阶梯度操作。InsertGradientOf算子的功能跟此前介绍过的bprop功能有些类似,也是自定义梯度,但bprop更倾向于计算梯度,而InsertGradientOf算子更倾向于修改梯度,这里介绍了一些比较详细的测试案例。
阅读全文
这篇文章主要介绍了mindspore深度学习框架中基于InsertGradientOf算子的进阶梯度操作。InsertGradientOf算子的功能跟此前介绍过的bprop功能有些类似,也是自定义梯度,但bprop更倾向于计算梯度,而InsertGradientOf算子更倾向于修改梯度,这里介绍了一些比较详细的测试案例。
阅读全文
摘要: 继上一篇文章从Torch的两个Issue中找到一些类似的问题之后,可以发现深度学习框架对于自定义反向传播函数中的传参还是比较依赖于必备参数,而不是关键字参数,MindSpore深度学习框架也是如此。但是我们可以使用一些临时的解决方案,对此问题进行一定程度上的规避,只要能够自定义的传参顺序传入关键字参数即可。
阅读全文
继上一篇文章从Torch的两个Issue中找到一些类似的问题之后,可以发现深度学习框架对于自定义反向传播函数中的传参还是比较依赖于必备参数,而不是关键字参数,MindSpore深度学习框架也是如此。但是我们可以使用一些临时的解决方案,对此问题进行一定程度上的规避,只要能够自定义的传参顺序传入关键字参数即可。
阅读全文
继上一篇文章从Torch的两个Issue中找到一些类似的问题之后,可以发现深度学习框架对于自定义反向传播函数中的传参还是比较依赖于必备参数,而不是关键字参数,MindSpore深度学习框架也是如此。但是我们可以使用一些临时的解决方案,对此问题进行一定程度上的规避,只要能够自定义的传参顺序传入关键字参数即可。
阅读全文
摘要: 本文介绍了热门AI框架PyTorch的conda安装方案,与简单的自动微分示例。并顺带讲解了一下PyTorch开源Github仓库中的两个Issue内容,分别是自动微分的关键词参数输入问题与自动微分参数数量不匹配时的参数返回问题,并包含了这两个Issue的解决方案。
阅读全文
本文介绍了热门AI框架PyTorch的conda安装方案,与简单的自动微分示例。并顺带讲解了一下PyTorch开源Github仓库中的两个Issue内容,分别是自动微分的关键词参数输入问题与自动微分参数数量不匹配时的参数返回问题,并包含了这两个Issue的解决方案。
阅读全文
本文介绍了热门AI框架PyTorch的conda安装方案,与简单的自动微分示例。并顺带讲解了一下PyTorch开源Github仓库中的两个Issue内容,分别是自动微分的关键词参数输入问题与自动微分参数数量不匹配时的参数返回问题,并包含了这两个Issue的解决方案。
阅读全文
摘要: 本文主要介绍了一个关于MindSpore运行报错RuntimeError的解决方案。这个报错的内容提示信息说的是安装完成MindSpore之后,找不到GPU的CUDA环境,只能使用CPU运行环境。出现这个报错是因为手动编译安装MindSpore之后,需要配置一些环境变量。而如果是使用pip或者conda安装mindspore的话,会自动的识别到CUDA环境并添加到环境变量中去。因此,解决这个报错,我们只需要把相关的CUDA环境路径添加到环境变量中即可。
阅读全文
本文主要介绍了一个关于MindSpore运行报错RuntimeError的解决方案。这个报错的内容提示信息说的是安装完成MindSpore之后,找不到GPU的CUDA环境,只能使用CPU运行环境。出现这个报错是因为手动编译安装MindSpore之后,需要配置一些环境变量。而如果是使用pip或者conda安装mindspore的话,会自动的识别到CUDA环境并添加到环境变量中去。因此,解决这个报错,我们只需要把相关的CUDA环境路径添加到环境变量中即可。
阅读全文
本文主要介绍了一个关于MindSpore运行报错RuntimeError的解决方案。这个报错的内容提示信息说的是安装完成MindSpore之后,找不到GPU的CUDA环境,只能使用CPU运行环境。出现这个报错是因为手动编译安装MindSpore之后,需要配置一些环境变量。而如果是使用pip或者conda安装mindspore的话,会自动的识别到CUDA环境并添加到环境变量中去。因此,解决这个报错,我们只需要把相关的CUDA环境路径添加到环境变量中即可。
阅读全文
摘要: 在MindSpore编译计算图的过程中,会把从编译构建好的whl包中引入的模块视为第三方库,也就没有办法在即时编译的阶段入图。普通的math和numpy等第三方库不入图也不会影响计算。但如果是基于MindSpore本身开发的一些函数,如果用到了Jit、Grad和Vmap,那么有可能出现无法入图的问题,就会出现RuntimeError报错。解决方法就是设置一个跟即时编译有关的环境变量,把相关的第三方包引用修改为内部引用。
阅读全文
在MindSpore编译计算图的过程中,会把从编译构建好的whl包中引入的模块视为第三方库,也就没有办法在即时编译的阶段入图。普通的math和numpy等第三方库不入图也不会影响计算。但如果是基于MindSpore本身开发的一些函数,如果用到了Jit、Grad和Vmap,那么有可能出现无法入图的问题,就会出现RuntimeError报错。解决方法就是设置一个跟即时编译有关的环境变量,把相关的第三方包引用修改为内部引用。
阅读全文
在MindSpore编译计算图的过程中,会把从编译构建好的whl包中引入的模块视为第三方库,也就没有办法在即时编译的阶段入图。普通的math和numpy等第三方库不入图也不会影响计算。但如果是基于MindSpore本身开发的一些函数,如果用到了Jit、Grad和Vmap,那么有可能出现无法入图的问题,就会出现RuntimeError报错。解决方法就是设置一个跟即时编译有关的环境变量,把相关的第三方包引用修改为内部引用。
阅读全文
摘要: 不同于符号微分和手动微分,基于链式法则的自动微分不仅有极高的速度,还不需要去手动推导微分,在深度学习领域有非常广泛的应用。本文主要通过几个案例,分别介绍了一下在MindSpore深度学习框架中,如何使用grad函数和GradOperation类,分别对函数和类进行自动微分计算。
阅读全文
不同于符号微分和手动微分,基于链式法则的自动微分不仅有极高的速度,还不需要去手动推导微分,在深度学习领域有非常广泛的应用。本文主要通过几个案例,分别介绍了一下在MindSpore深度学习框架中,如何使用grad函数和GradOperation类,分别对函数和类进行自动微分计算。
阅读全文
不同于符号微分和手动微分,基于链式法则的自动微分不仅有极高的速度,还不需要去手动推导微分,在深度学习领域有非常广泛的应用。本文主要通过几个案例,分别介绍了一下在MindSpore深度学习框架中,如何使用grad函数和GradOperation类,分别对函数和类进行自动微分计算。
阅读全文
摘要:![MindSpore报错处理:TypeError: For 'set_context', the parameter device_id can not be set repeatedly, origin value [0] has been in effect.](https://img2024.cnblogs.com/blog/2277440/202403/2277440-20240322101240483-1657865203.png) 本文主要介绍了一个在使用MindSpore框架进行编程的时候遇到的一个小问题--重复设定运算设备的编号。之所以会出现这个问题,是因为在调用的包里面有对MindSpore的引用,里面还包含了一些基于MindSpore的运算和即时编译,因此如果不给定设备编号的话,MindSpore内部会默认分配一个设备编号。而如果我们在自己的测试案例中又希望指定一个设备编号,那么就要把这个set_context句柄放在引用的最前面。
阅读全文
本文主要介绍了一个在使用MindSpore框架进行编程的时候遇到的一个小问题--重复设定运算设备的编号。之所以会出现这个问题,是因为在调用的包里面有对MindSpore的引用,里面还包含了一些基于MindSpore的运算和即时编译,因此如果不给定设备编号的话,MindSpore内部会默认分配一个设备编号。而如果我们在自己的测试案例中又希望指定一个设备编号,那么就要把这个set_context句柄放在引用的最前面。
阅读全文
本文主要介绍了一个在使用MindSpore框架进行编程的时候遇到的一个小问题--重复设定运算设备的编号。之所以会出现这个问题,是因为在调用的包里面有对MindSpore的引用,里面还包含了一些基于MindSpore的运算和即时编译,因此如果不给定设备编号的话,MindSpore内部会默认分配一个设备编号。而如果我们在自己的测试案例中又希望指定一个设备编号,那么就要把这个set_context句柄放在引用的最前面。
阅读全文
摘要: 在Linux运行程序时,正确输出和错误输出会分成两条路线分别输出到不同的位置,默认输出是将两者按照顺序分别输出到屏幕上,而我们也可以通过设定将二者按照顺序输出到一个指定的log文件中。同时为了避免受到窗口交互的影响,我们可以使用Linux挂起的方式来运行一个程序,这样我们既不用担心任务被中断,也可以同时不断的通过log文件内容来查看任务的运行情况,还可以通过ps指令来查看任务进程运行的时长等信息。
阅读全文
在Linux运行程序时,正确输出和错误输出会分成两条路线分别输出到不同的位置,默认输出是将两者按照顺序分别输出到屏幕上,而我们也可以通过设定将二者按照顺序输出到一个指定的log文件中。同时为了避免受到窗口交互的影响,我们可以使用Linux挂起的方式来运行一个程序,这样我们既不用担心任务被中断,也可以同时不断的通过log文件内容来查看任务的运行情况,还可以通过ps指令来查看任务进程运行的时长等信息。
阅读全文
在Linux运行程序时,正确输出和错误输出会分成两条路线分别输出到不同的位置,默认输出是将两者按照顺序分别输出到屏幕上,而我们也可以通过设定将二者按照顺序输出到一个指定的log文件中。同时为了避免受到窗口交互的影响,我们可以使用Linux挂起的方式来运行一个程序,这样我们既不用担心任务被中断,也可以同时不断的通过log文件内容来查看任务的运行情况,还可以通过ps指令来查看任务进程运行的时长等信息。
阅读全文
摘要: 本文介绍了在MindSpore标准格式下进行CUDA算子开发的方法和流程,可以让开发者在现有的AI框架下仍然可以调用基于CUDA实现的高性能的算子。并且,除了常规的数值计算之外,在MindSpore框架下,我们还可以通过实现一个bprop函数,使得我们手写的这个CUDA算子也可以使用MindSpore框架本身自带的自动微分-端到端微分技术。
阅读全文
本文介绍了在MindSpore标准格式下进行CUDA算子开发的方法和流程,可以让开发者在现有的AI框架下仍然可以调用基于CUDA实现的高性能的算子。并且,除了常规的数值计算之外,在MindSpore框架下,我们还可以通过实现一个bprop函数,使得我们手写的这个CUDA算子也可以使用MindSpore框架本身自带的自动微分-端到端微分技术。
阅读全文
本文介绍了在MindSpore标准格式下进行CUDA算子开发的方法和流程,可以让开发者在现有的AI框架下仍然可以调用基于CUDA实现的高性能的算子。并且,除了常规的数值计算之外,在MindSpore框架下,我们还可以通过实现一个bprop函数,使得我们手写的这个CUDA算子也可以使用MindSpore框架本身自带的自动微分-端到端微分技术。
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号