
数据结构篇——字典树(trie树)
引入
现在有这样一个问题, 给出\(n\)个单词和\(m\)个询问,每次询问一个单词,回答这个单词是否在单词表中出现过。
好像还行,用 map<string,bool> ,几行就完事了。
那如果n的范围是 \(10^5\) 呢?再用 \(map\) 妥妥的超时,说不定还会超内存。
这时候就需要一种强大的数据结构——字典树
基本性质
字典树,又叫Trie树、前缀树,用于统计,排序和保存大量的字符串,经常被搜索引擎系统用于文本词频统计。
基本思想: 利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较。
假设所有单词都只由小写字母构成,由(abd,abcd,b,bcd,efg,hil)构成的字典树如下。(百科的图最后少了一个字母,姑且认为它是'l'吧)
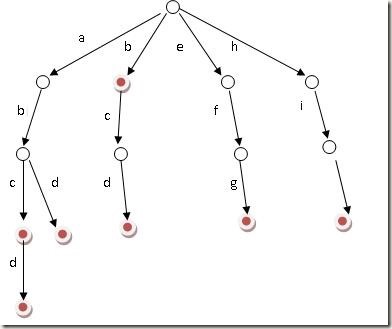
可以看出字典树具有以下特点:
-
用边表示字母
-
具有相同前缀的单词共用前缀节点
-
每个节点最多有26个子节点(在单词只包含小写字母的情况下)
-
树的根节点是空的
基本操作
数据结构定义
用pass记录有多少字符串经过该节点,就是多少单词以根结点到该结点的边组成的字符串为前缀。
用end记录有多少字符串以该节点结尾,就是多少单词是以根结点到该结点的边组成的字符串。
typedef struct node{
int pass;//有多少单词经过该结点
int end;//有多少单词以该结点结尾
struct node* next[26];
}*trieTree;
插入
向字典树中插入字符串 \(S\)
void insert(trieTree T,string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
node *t = new node();
T->next[index] = t;
}
T = T->next[index];
T->pass++;
}
T->end++;
}
查找
查找文章中有多少单词以字符串 \(S\) 为前缀。
如果要查找字符串 \(s\) 在文章中出现了多少次,则返回值改成 T->end 。
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
return NULL;
}
T = T->next[index];
}
return T->pass;
}
完整实现
#include <iostream>
#include <string>
using namespace std;
typedef struct node{
int pass;
int end;
struct node* next[26];
}*trieTree;
void insert(trieTree T,string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
node *t = new node();
T->next[index] = t;
}
T = T->next[index];
T->pass++;
}
T->end++;
}
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
int index = s[i] - 'a';
if (T->next[index] == NULL) {
return NULL;
}
T = T->next[index];
}
return T->pass;
}
map实现
用 node* next[26] 会浪费很多空间,因为不可能每个结点都用掉 26 个 next
#include <iostream>
#include <map>
#include <string>
using namespace std;
typedef struct node{
public:
int pass;
int end;
map<char,struct node *>m;
}* trieTree;
void insert(trieTree T,string s) {
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
node *t = new node();
T->m.insert(make_pair(s[i], t));
}
T = T->m[s[i]];
T->pass++;
}
T->end++;
}
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
return NULL;
}
T = T->m[s[i]];
}
return T->pass;
}
适用例题
前缀匹配、 字符串检索 、词频统计,这些差不多都是一类题目,具体实现有一点点不同。
比如前缀匹配,我们只需要pass就行了,用不到end;词频统计的话,我们又只用得到end了;如果只是字符串检索的话,那更方便了,end定义成bool变量就行了。具体用啥,怎么用要变通。
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=1251
这题有点小坑,用 node* next[26] 交G++会超内存,交C++就不会。但确实用数组会浪费很多空间,推荐使用map实现。
#include <iostream>
#include <map>
#include <string>
using namespace std;
typedef struct node{
int pass;
map<char,struct node *>m;
}*trieTree;
void insert(trieTree T,string s) {
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
node *t = new node();
T->m.insert(make_pair(s[i], t));
}
T = T->m[s[i]];
T->pass++;
}
}
int find(trieTree T, string s) {
node *n = T;
for (int i = 0; i < s.length(); i++) {
if (T->m.find(s[i]) == T->m.end()) {
return NULL;
}
T = T->m[s[i]];
}
return T->pass;
}
int main() {
trieTree T = new node();
string s;
while (getline(cin,s)) {
if (s.empty()) break;
insert(T, s);
}
while (getline(cin,s)) {
cout << find(T, s) << endl;
}
return 0;
}
此外,还适用于字符串排序,字典树是一棵多叉树,只要先序遍历整棵树,输出相应的字符串便是按字典序排序的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号