


NLP自然语言处理原理及名词介绍
1. 自然语言概念
自然语言,即我们人类日常所使用的语言,是人类交际的重要方式,也是人类区别其他动物的本质特征。
但是我们只能通过自然语言与人交流,无法与计算机进行交流。
2. 自然语言处理
自然语言处理,是人工智能的一部分,实现了人与计算机之间的有效通信。自然语言处理属于计算机科学领域与人工智能领域,其研究使用计算机编程来处理和理解人类的语言。
3. 应用场景
- 情感分析(从一段文本中提取该文本的感情色彩,是褒义、中性还是贬义)
- 机器翻译
- 文本相似度匹配(从多段文本中,分析两段文本内容的相似度)
- 智能客服(就是聊天机器人)
4. 自然语言处理通用技术
(1) 分词
概念:将连续的文本,分割成语义合理的若干词汇序列。
例如:阿里云自然语言处理,通过分词器,转变为 阿里云/自然/语言/处理
(2) 停用词过滤
概念:在文本中大量存在,但对语义分析没有帮助的词。
例如:呢、啊、吗。。。
(3) 词干提取
概念:对单词去掉后缀,还原词本身。词干提取主要用在英文等西方语言中。
例如:being —> be
(4) 词形还原
概念:对同一单词不同形式的识别,将单词还原为标准形式。主要用在英文等西方语言中。
例如:is, am, are —> be
比较:词干提取与词形还原
相同点:都是对同一单词的不同格式进行处理
不同点:词干提取是去掉单词的后缀;词形还原是以词元为依据,根据语义进行分析,获取单词的标准形式。
例如:ate =>at(词干提取)
ate =>eat(词形还原)
(5) 词袋模型
概念:是用来将文本转换成特征向量的表示形式。将每个文档构建一个特征向量,其中包含每个单词在文档中出现次数。
缺点:
- 忽略了大众词(在文档中也经常出现)
- 特征向量特别多
(6) TF-IDF
概念:指词频-逆文档频率。针对词语重要性的一种加权统计方式。全称:Term Frequency-Inverse Document Frequency。
场合:常用在信息检索、文本挖掘等技术中,作为加权因子。
TF-IDF的核心思想为词条的重要性随着该词条在当前文档中出现的次数成正比增加,但同时会随着它在语料库(所有文档)中出现的频率成反比下降。
公式:TF-IDF = TF(词频) * IDF(逆文档频率)
含义解释:
TF:词频统计,对文章中词语出现的频率进行计数统计
TF = (当前的文档单词出现的次数)/(当前的文档中包含的单词总数)
IDF:逆文档频率,指语料库中文档总数与语料库中包含该词的文档数,二者比值的对数。
IDF = log((语料库中文档总数)/(语料库中包含该词的文档数+1))
例子:
昨夜星辰昨夜风
我们一起学习自然语言处理
昨夜下了一场大雨
星期二是晴天
计算第一个文档"昨夜"的TF-IDF值?
TF(昨夜) = 2/4
IDF(昨夜) = log(4/(2+1))
TF-IDF = TF * IDF = 1/2*log(4/3)
(7) Word2Vec
概念:是google2013年提出的一个开源算法,使用神经网络技术,可以将词表转换成向量表示。确切的说,将词映射成n维空间向量,特征纬度n视具体情况与需求而定。
核心思想:通过将词条转换成向量,从而根据余弦相似度来计算文本之间的相似度。
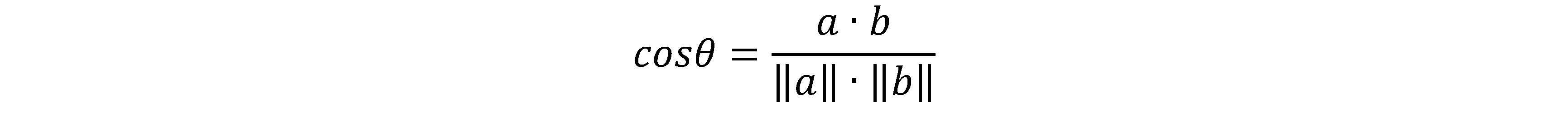

 浙公网安备 33010602011771号
浙公网安备 33010602011771号