Phoenix 索引笔记2
Phoenix 索引2
-- 建表
CREATE TABLE "FN1"."CHATDOC" (
ID UNSIGNED_LONG NOT NULL PRIMARY KEY,
PARENTID UNSIGNED_LONG ,
TITLE VARCHAR(2000),
LINKURL VARCHAR(2000),
DOCCREATOR VARCHAR(100)
);
-- 创建的二级索引
CREATE INDEX IDX_CHATDOC_INCLUD ON FN1.CHATDOC(PARENTID) INCLUDE(TITLE,LINKURL,DOCCREATOR) COMPRESSION = 'GZ', SALT_BUCKETS = 2;
https://blog.csdn.net/HiBoyljw/article/details/111340469
Phoenix 的一次删除索引,删除表的惨痛经历
--查看元数据
select * from SYSTEM."CATALOG" where TABLE_NAME='CHATDOC' AND TABLE_SCHEM ='FN1';
--删除元数据字段
DELETE from SYSTEM."CATALOG" where TABLE_NAME='CHATDOC' AND TABLE_SCHEM ='FN1' AND COLUMN_FAMILY ='IDX_CHATDOC_INCLUD';
https://blog.csdn.net/czmacd/article/details/53958488
//创建盐表,就是预分区表的一种
create table ns1.testsalt
(id integer primary key,
name varchar,
age integer,
address varchar)
salt_buckets = 6;
//添加数据
upsert into ns1.testsalt (id,name,age,address) values(1,'zhangshan',18,'chongqing');
upsert into ns1.testsalt (id,name,age,address) values(2,'lishi',16,'wuhan');
//创建索引
CREATE INDEX testsalt_idx ON ns1.testsalt(name,age);
CREATE INDEX testsalt_idx_2 ON ns1.testsalt(name,age) include(address);
//删除索引
DROP INDEX testsalt_idx ON ns1.testsalt;
//phoenix中查询表和索引表的数据
select * from ns1.testsalt;
select * from ns1.testsalt_idx;
select * from ns1.testsalt_idx_2;
//explain查看sql运行情况
explain select address from ns1.testsalt where age=17;
//强制走索引
explain select /*+ INDEX(ns1.testsalt testsalt_idx) */ address from ns1.testsalt where age=17;
//hbase中查询表和索引表的数据
scan 'NS1:TESTSALT'
scan 'NS1:TESTSALT_IDX'
scan 'NS1:TESTSALT_IDX_2'
//创建表
create table ns1.testlocal
(id integer primary key,
name varchar,
age integer,
address varchar);
//添加数据
upsert into ns1.testlocal (id,name,age,address) values(1,'wangwu',21,'shandong');
upsert into ns1.testlocal (id,name,age,address) values(2,'chenmazi',26,'xinjiang');
//创建索引,注意关键词 local
CREATE local INDEX testlocal_idx ON ns1.testlocal(name,age);
CREATE local INDEX testlocal_idx_2 ON ns1.testlocal(name,age) include(address);
//删除索引
DROP INDEX testlocal_idx ON ns1.testlocal;
//phoenix中查询表和索引表的数据
select * from ns1.testlocal;
select * from ns1.testlocal_idx;
select * from ns1.testlocal_idx_2;
//explain查看sql运行的情况
explain select address from ns1.testlocal where age=17;
//强制走索引
explain select /*+ INDEX(ns1.testlocal testlocal_idx) */ address from ns1.testlocal where age=17;
//hbase中查询表
scan 'NS1:TESTLOCAL'
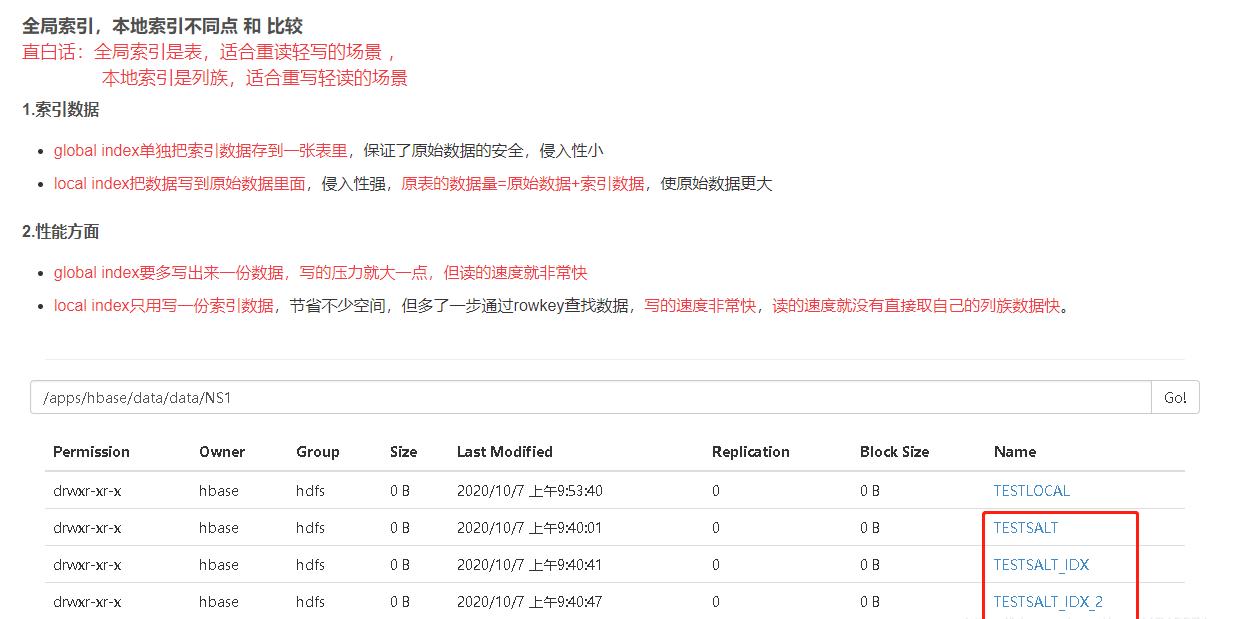
不管是全局索引 ,还是本地索引,从phoenix查询,索引也是一张表
- 对象存储:我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
- 时序数据:HBase之上有OpenTSDB模块,可以满足时序类场景的需求
- 推荐画像:特别是用户的画像,是一个比较大的稀疏矩阵,蚂蚁的风控就是构建在HBase之上
- 时空数据:主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
- CubeDB OLAP:Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
- 消息/订单:在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
- Feeds流:典型的应用就是xx朋友圈类似的应用
- NewSQL:之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
动态列
CREATE TABLE EventLog (
eventId BIGINT NOT NULL,
eventTime TIME NOT NULL,
eventType CHAR(3)
CONSTRAINT pk PRIMARY KEY (eventId, eventTime)) COLUMN_ENCODED_BYTES=0
UPSERT INTO EventLog (eventId, eventTime, eventType, lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) VALUES(1, CURRENT_TIME(), 'abc', CURRENT_TIME(), 512, 1024);
SELECT eventId, eventTime, lastGCTime, usedMemory, maxMemory FROM EventLog(lastGCTime TIME, usedMemory BIGINT, maxMemory BIGINT) where eventId=1
CREATE TABLE table (key VARCHAR PRIMARY KEY, col VARCHAR) SALT_BUCKETS = 8;
CREATE SEQUENCE my_sequence;-- 创建一个自增序列,初始值为1,自增间隔为1,将有100个自增值缓存在客户端。
CREATE SEQUENCE my_sequence START WITH -1000
CREATE SEQUENCE my_sequence INCREMENT BY 10
CREATE SEQUENCE my_cycling_sequence MINVALUE 1 MAXVALUE 100 CYCLE;
CREATE SEQUENCE my_schema.my_sequence START 0 CACHE 10
DROP SEQUENCE [IF EXISTS] SCHEMA.SEQUENCE_NAME
DROP SEQUENCE my_sequence
DROP SEQUENCE IF EXISTS my_schema.my_sequence
create table books(
id integer not null primary key,
name varchar,
author varchar
)SALT_BUCKETS = 8;
CREATE SEQUENCE book_sequence START WITH 10000 INCREMENT BY 1 CACHE 1000;
UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'DATA SCIENCE', 'JHONE');
UPSERT INTO books(id, name, author) VALUES( NEXT VALUE FOR book_sequence,'Effective JAVA','Joshua Bloch');
//例表如下(为了能够容易通过HBASE SHELL对照表内容,我们对属性值COLUMN_ENCODED_BYTES设置为0,不对column family进行编码):
CREATE TABLE TEST (
ID VARCHAR NOT NULL PRIMARY KEY,
COL1 VARCHAR,
COL2 VARCHAR
) COLUMN_ENCODED_BYTES=0;
upsert into TEST values('1', '2', '3');
CREATE INDEX IDX_COL1 ON TEST(COL1)
create local index LOCAL_IDX_COL1 ON TEST(COL1);
create index IDX_COL1_COVER_COL2 on TEST(COL1) include(COL2);
//创建函数索引
CREATE INDEX CONCATE_IDX ON TEST (UPPER(COL1||COL2))
//查询函数索引
SELECT * FROM TEST WHERE UPPER(COL1||COL2)='23'
CREATE INDEX IDX_COL1 ON TEST(COL1);
select * from TEST where COL1='2';
select * from TEST where id='1' and COL1='2'
//创建异步索引
CREATE INDEX ASYNC_IDX ON DB.TEST (COL1) ASYNC
//build 索引数据
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool --schema DB --data-table TEST --index-table ASYNC_IDX --output-path ASYNC_IDX_HFILES
//在客户端配置文件hbase-site.xml中,把超时参数设置大一些,足够build索引数据的时间。
<property>
<name>hbase.rpc.timeout</name>
<value>60000000</value>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>60000000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>60000000</value>
</property>
SELECT * FROM TEST LIMIT 1000;
SELECT * FROM TEST LIMIT 1000 OFFSET 100;
SELECT full_name FROM SALES_PERSON WHERE ranking >= 5.0
UNION ALL SELECT reviewer_name FROM
CUSTOMER_REVIEW WHERE score >= 8.0
UPSERT INTO TEST VALUES('foo','bar',3);
UPSERT INTO TEST(NAME,ID) VALUES('foo',123);
UPSERT INTO TEST(ID, COUNTER) VALUES(123, 0) ON DUPLICATE KEY UPDATE COUNTER = COUNTER + 1;
UPSERT INTO TEST(ID, MY_COL) VALUES(123, 0) ON DUPLICATE KEY IGNORE;
UPSERT INTO test.targetTable(col1, col2) SELECT col3, col4 FROM test.sourceTable WHERE col5 < 100
UPSERT INTO foo SELECT * FROM bar;
DELETE FROM TABLENAME;
DELETE FROM TABLENAME WHERE PK=123;
DELETE FROM TABLENAME WHERE NAME LIKE '%';
CREATE TABLE IF NOT EXISTS us_population (
state CHAR(2) NOT NULL,
city VARCHAR NOT NULL,
population BIGINT
CONSTRAINT my_pk PRIMARY KEY (state, city));
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
<property>
<name>phoenix.force.index</name>
<value>false</value>
</property>
参考
https://www.cnblogs.com/hbase-community/p/8655347.html
https://www.cnblogs.com/hbase-community/p/9000895.html
https://www.cnblogs.com/hbase-community/p/8879848.html
https://www.cnblogs.com/hbase-community/p/8629222.html
https://www.cnblogs.com/hbase-community/p/8853577.html
https://www.cnblogs.com/hbase-community/p/8759177.html
https://www.cnblogs.com/wqy1027/p/16705791.html
https://blog.51cto.com/u_16213299/7060952

 浙公网安备 33010602011771号
浙公网安备 33010602011771号