【转载】最全的正则表达式教程
一、正则基础概述
1、什么是正则表达式?
2、基础语法图表
2.1 - 基础语法表格
首先先给出最最基础部分的匹配规则,这个是肯定要会的
| single char (单字符) | quantifiers(数量) | position(位置) |
|---|---|---|
| \d 匹配数字 | * 0个或者更多 | ^一行的开头 |
| \w 匹配word(数字、字母) | + 1个或更多,至少1个 | $一行的结尾 |
| \W 匹配非word(数字、字母) | ? 0个或1个,一个Optional | \b 单词"结界"(word bounds) |
| \s 匹配white space(包括空格、tab等) | {min,max}出现次数在一个范围内 | |
| \S 匹配非white space(包括空格、tab等) | {n}匹配出现n次的 | |
| . 匹配任何,任何的字符 |
2.2-修饰符(三个 g 、i、m)
修饰符与其他语法特殊,字面量方法声名的时候放到//后,构造函数声明的时候,作为第二个参数传入。整个正则表达式可以理解为正则表达式规则字符串+修饰符
- g:global 执行一个全局匹配
- i:ignore case执行一个不区分大小写的匹配
- m: multiple lines多行匹配
修饰符可以一起用
/\bis\b/gim
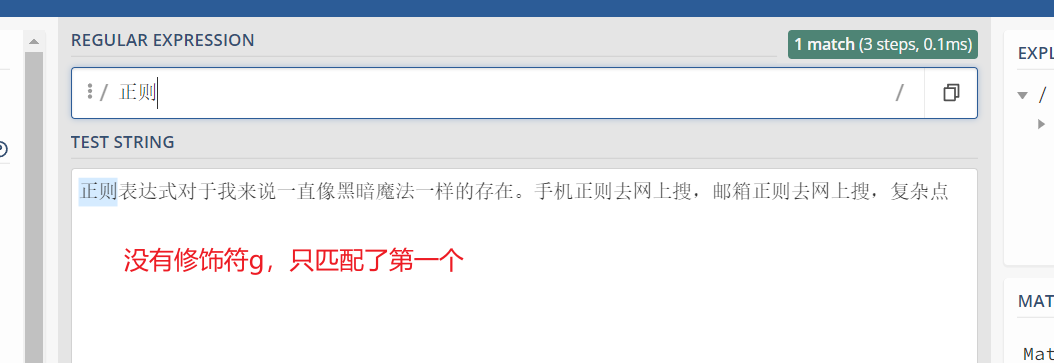
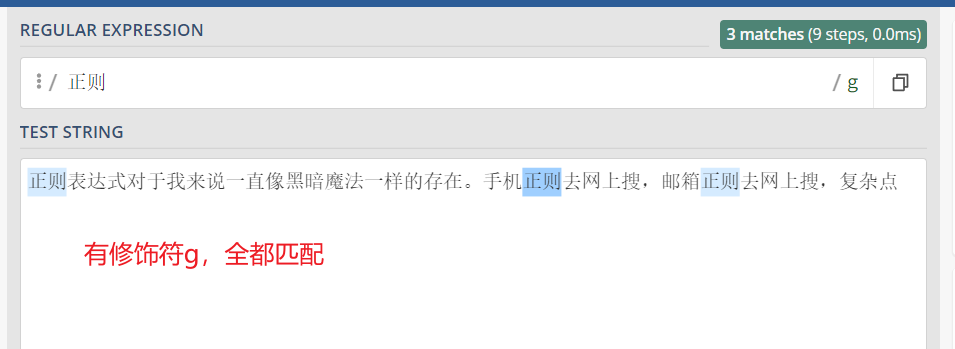
修饰符:g
没有g只替换了第一个,有g 所有的都换了
无修饰符g
有修饰符g
修饰符:i
有i忽略大小写,没有i严格区分大小写
修饰符:m
2.3-常用语法示例图解析
此处暂时看不懂没关系,后面会进行详细的语法介绍,此处只是让我们对正则表达式更有概念,感觉不好理解可以跳过,学完再回来看
此示例图解析部分主要摘录自 comer的60分钟正则从入门到深入(https://segmentfault.com/a/1190000013075245?sort=votes)。
本人觉得其图画的挺好的,且确实刚开始可以稍微看下正则具体应用,方便后续理解,便摘录下来。
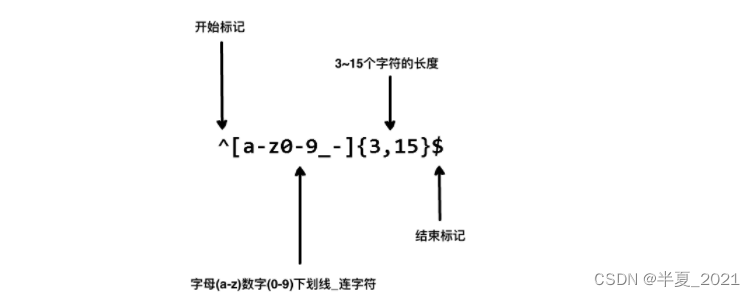
a) 通用正则表达式
b) 手机号正则
/^1[34578][0-9]{9}$/
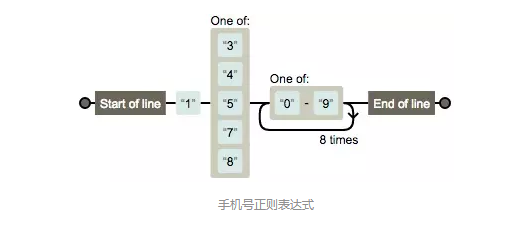
tips:以1开头,第二位为3 4 5 7 9 其中一个,以9位(本身1次加重复8次)0-9数字结尾
c) 单词边界
/\bis\b/
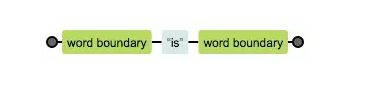
tips: is前后都是单词的边界,比较晦涩难懂?感受下两者的区别,b 会放到语法部分讲解
d) URL分组
/http:(\/\/.+\.jpg)/

正则表达式中括号用来分组
e) 日期匹配
/^\d{4}[/-]d{1,2}[/-]\d{1,2}$/
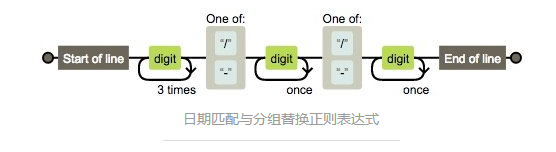
这个正则比较复杂,画符念咒的地方太多了,一一分析:
- Start of line 是由^生效的表示以此开头
- 对应结尾End of line 由$生效表示以此结尾
- 接着看digit 由 d 生效表示数字
- 3times 由{4} 生效表示重复4次,开始的时候有疑问,为什么不是 4times 。后来明白作者的用意,正则表达式是一个规则,用这个规则去从字符串开始匹配到结束(注意计算机读字符串可是不会分行的,都是一个串,我们看到的多行,人家会认为是个 t )这里设计好像小火车的轨道一直开到末尾。digit 传过一次,3times表示再来三次循环,共4次,后面的once同理。 自己被自己啰嗦到了。
- 接下来,是 one of 在手机正则里面已经出现了。表示什么都行。只要符合这两个都让通过。
f) 日期分组匹配
/^(\d{4})[/-](\d{1,2})[/-](\d{1,2})$/

3、基本匹配
正则表达式其实就是在执行搜索时的格式,它由一些字母(也可以是汉字)和数字组合而成。
例如:一个正则表达式 学习的汪 H,它表示一个规则:由'学'开始,接着是'习',…最后'H'。它是逐个字符与输入的正则表达式作比较,同时大小写敏感
二、元字符
正则表达式主要依赖于元字符。 元字符不代表他们本身的字面意思,他们都有特殊的含义。一些元字符写在方括号中的时候有一些特殊的意思。
2.1、元字符列举
| 元字符 | 描述 |
|---|---|
| . | 句号匹配任意单个字符除了换行符。 |
| [ ] | 字符种类。匹配方括号内的任意字符。 |
| [^ ] | 否定的字符种类。匹配除了方括号里的任意字符 |
| * | 匹配>=0个重复的在*号之前的字符。 |
| + | 匹配>=1个重复的+号前的字符。 |
| ? | 标记?之前的字符为可选. |
| {n,m} | 匹配num个大括号之前的字符或字符集 (n <= num <= m). |
| (xyz) | 字符集,匹配与 xyz 完全相等的字符串. |
| | | 或运算符,匹配符号前或后的字符. |
| \ | 转义字符,用于匹配一些保留的字符 `[ ] ( ) { } . * + ? ^ $ \ |
| ^ | 从开始行开始匹配. |
| $ | 从末端开始匹配. |
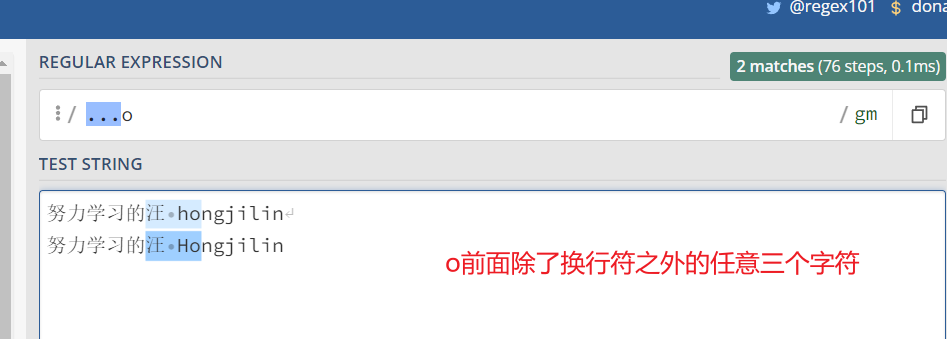
2.2、点运算符 --> .
.是元字符中最简单的例子。 .匹配任意单个字符,但不匹配换行符。 例如,表达式 [...o ] 匹配3个(几个点就几位)任意字符后面跟着是 [ o ] 的字符串
2.3、字符集
字符集也叫做字符类。 方括号用来指定一个字符集。 在方括号中使用连字符来指定字符集的范围。 在方括号中的字符集不关心顺序。
例如,表达式 [ 学习的汪 [Hh] ] 匹配 [ 学习的汪 h ] 和 [ 学习的汪 H ]

2.4、字符集中匹配句号. -->> [.]
前面我们说过点运算符,那同学们是否会有个疑惑, . 被用来匹配任意字符,那么作为字符串中的句号.,又该用什么匹配呢?
方括号的句号就表示句号。 表达式 lin[.] 匹配 lin.字符串
点代表任意字符
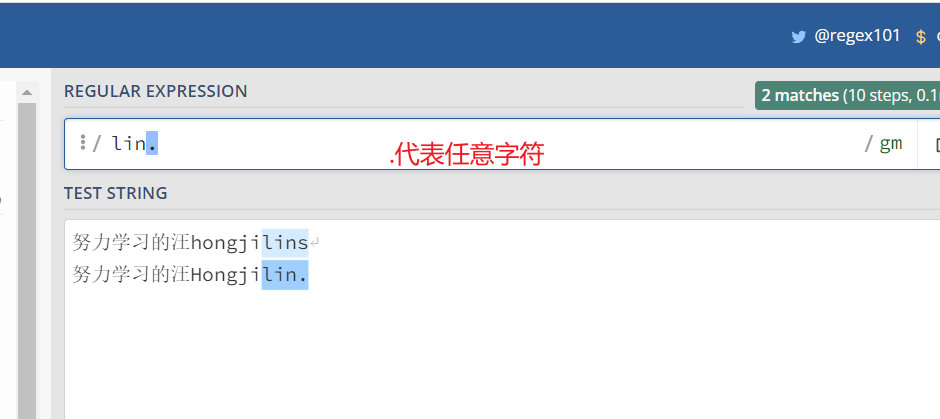
点代表句号
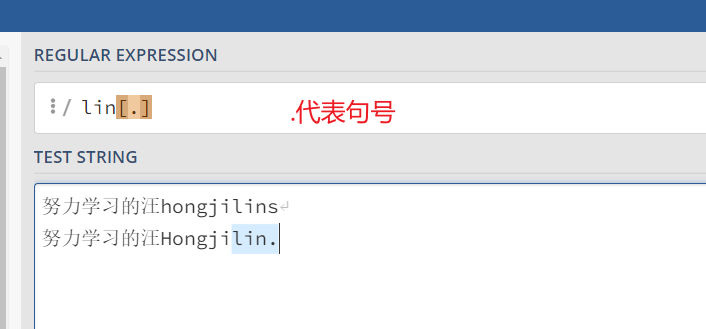
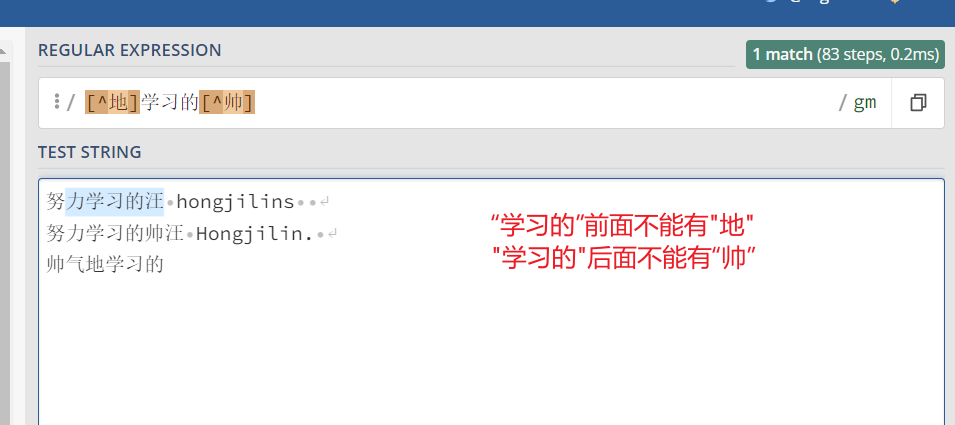
2.5、否定字符集 -->> [^]
一般来说 ^ 表示一个字符串的开头,但它用在一个方括号的开头的时候,它表示这个字符集是否定的。 例如,表达式[^地]学习的[^帅] 匹配一个字符串为 [ 学习的 ]的, 同时前面一位字符串不能为地,后面一位字符串不能为帅
2.6、点(.)的特殊用法
正则表达式中,点(.)是一个特殊字符,代表任意的单个字符,但是有两个例外。一个是四个字节的 UTF-16 字符,这个可以用u修饰符解决;另一个是"行终止符"(line terminator character)。
所谓"行终止符",就是该字符表示一行的终结。以下四个字符属于“行终止符”。
U+000A 换行符(\n)
U+000D 回车符(\r)
U+2028 行分隔符(line separator)
U+2029 段分隔符(paragraph separator)
示例 1:
/foo.bar/.test('foo\nbar') // false
上面代码中,因为.不匹配\n,所以正则表达式返回false。
但是,很多时候我们希望匹配的是任意单个字符,这时有一种变通的写法。
/foo[^]bar/.test('foo\nbar') // true
当然,这种解决方案毕竟不太符合直觉, ES2018 引入s修饰符,使得.可以匹配任意单个字符。
/foo.bar/s.test('foo\nbar') // true
2.7、重复次数 -->> *、+、?
后面跟着元字符 +,* or ? 的,用来指定匹配子模式的次数。 这些元字符在不同的情况下有着不同的意思。
a) * 号
*号匹配 在*之前的字符出现大于等于0次。 例如,表达式 a* 匹配0或更多个以a开头的字符。表达式[a-z]* 匹配一个行中所有以小写字母开头的字符串。
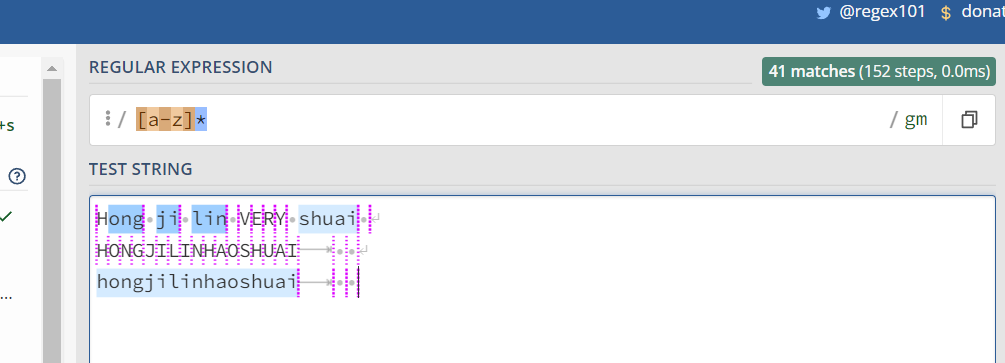
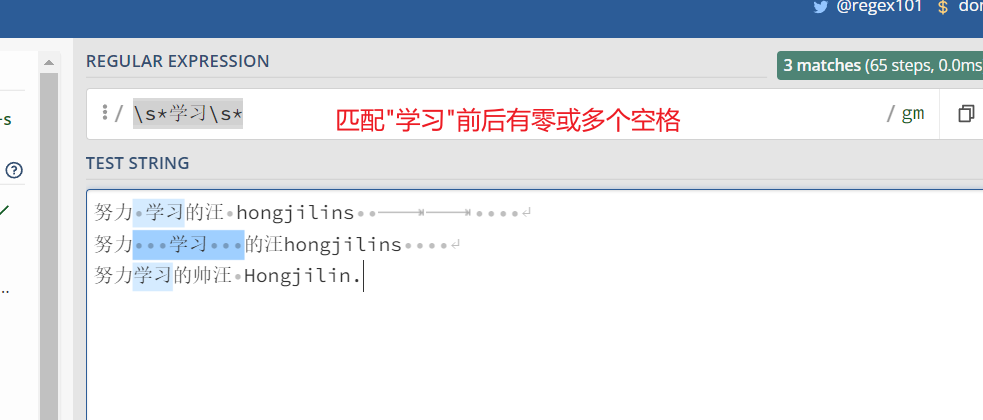
*号搭配 .号。
*字符和.字符搭配可以匹配所有的字符.*。 *和表示匹配空格的符号\s连起来用,如表达式\s*学习\s*匹配0或更多个空格开头和0或更多个空格结尾的cat字符串。
//[学习]前一个空格,后面无空格 努力 学习的汪 hongjilins //[学习]前后多个空格 努力 学习 的汪hongjilins 努力学习的帅汪 Hongjilin.
b) +号
+号匹配+号之前的字符出现 >=1 次。 例如表达式学习.+汪 匹配以中文学习开头以 [汪] 结尾,中间跟着至少一个字符的字符串。
"学习.+汪" => 努力学习的汪 hongjilins 努力学习的帅汪 Hongjilin. 努力学习 66 汪 Hongjilin. 努力的学习汪 //此行无匹配结果
c) ? 号
在正则表达式中元字符 ? 标记在符号前面的字符为可选,即出现 0 或 1 次。 例如,表达式 学习的[帅]?汪 匹配字符串 学习的汪 和 学习的帅汪。
"学习的[帅]?汪" => 努力学习的汪 hongjilins 努力学习的帅汪 Hongjilin. 努力的学习汪 //无匹配结果 努力学习的帅气汪 Hongjilin. //无匹配结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号