scrapy获取当当网多页的获取
结合上节,网多页的获取只需要修改
dang.py
import scrapy
from scrapy_dangdang.items import ScrapyDangdang095Item
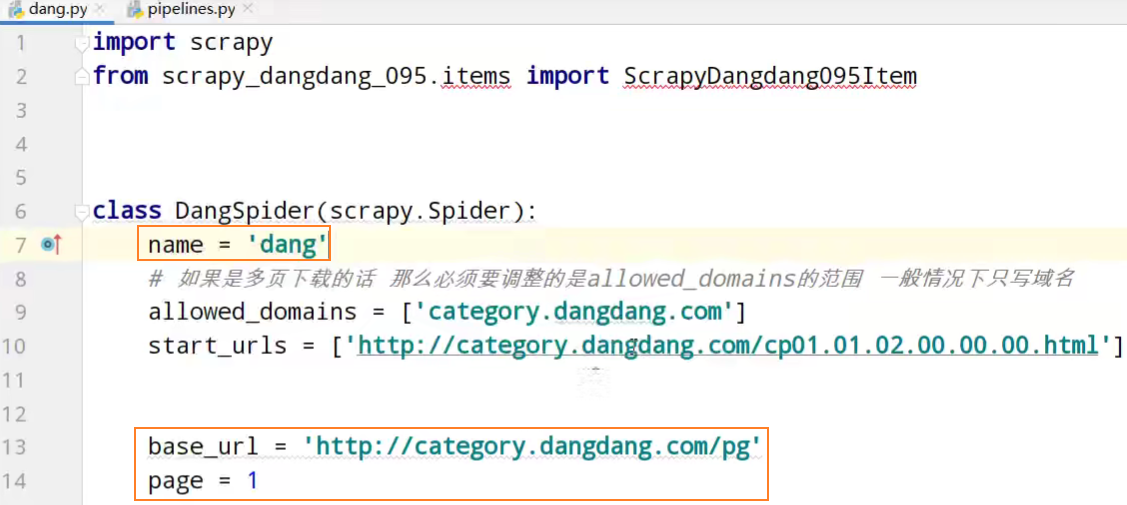
class DangSpider(scrapy.Spider):
name = 'dang'
# 如果是多页下载的话 那么必须要调整的是allowed_domains的范围 一般情况下只写域名
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# pipelines 下载数据
# items 定义数据结构的
# src = //ul[@id="component_59"]/li//img/@src
# alt = //ul[@id="component_59"]/li//img/@alt
# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
# 所有的seletor的对象 都可以再次调用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 第一张图片和其他的图片的标签的属性是不一样的
# 第一张图片的src是可以使用的 其他的图片的地址是data-original
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdang095Item(src=src,name=name,price=price)
# 获取一个book就将book交给pipelines
yield book
# 每一页的爬取的业务逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法就可以了
# http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg4-cp01.01.02.00.00.00.html
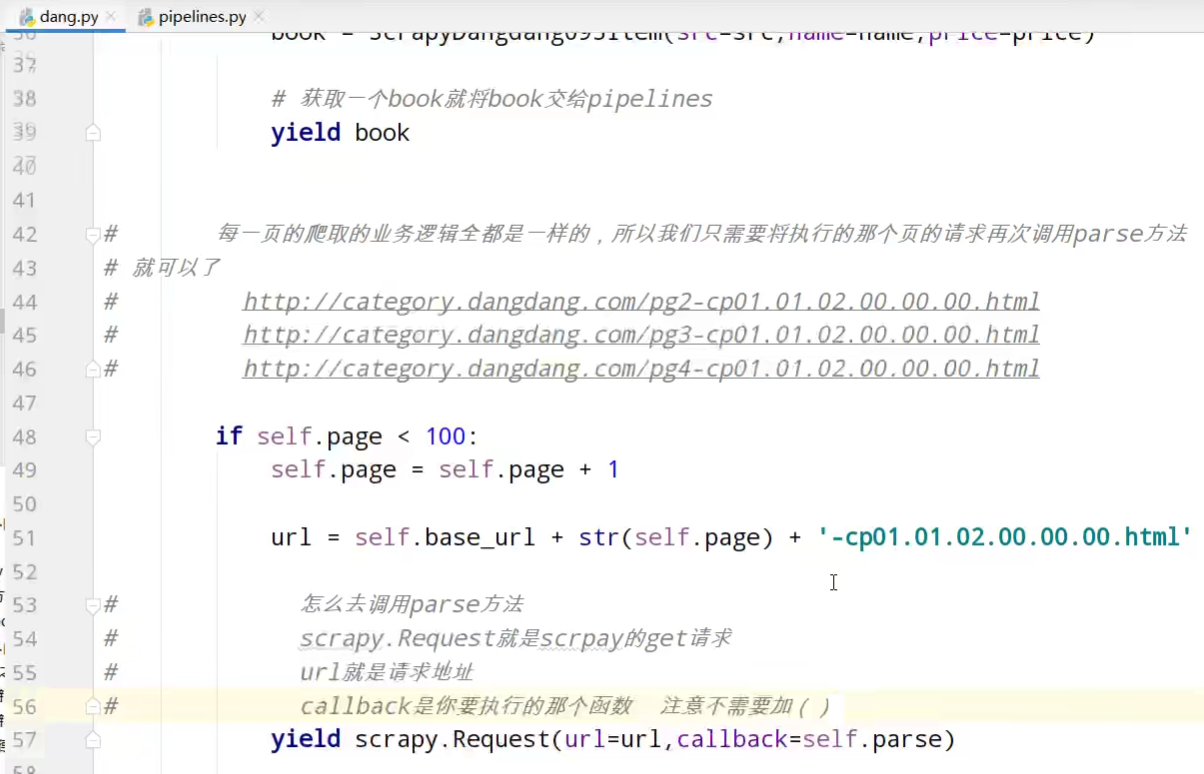
if self.page < 100:
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# 怎么去调用parse方法
# scrapy.Request就是scrpay的get请求
# url就是请求地址
# callback是你要执行的那个函数 注意不需要加()
yield scrapy.Request(url=url,callback=self.parse)
运行


Ctrl+z暂定
多页下载完毕


 浙公网安备 33010602011771号
浙公网安备 33010602011771号