
REST API设计指导——译自Microsoft REST API Guidelines(四)
前言
前面我们说了,如果API的设计更规范更合理,在很大程度上能够提高联调的效率,降低沟通成本。那么什么是好的API设计?这里我们不得不提到REST API。
关于REST API的书籍很多,但是完整完善实践丰富的设计指导并不多见,我们有幸看到了微软团队的作品——Microsoft REST API Guidelines,因此才有了此篇内容。
由于公众号文章内容字数有限,因此我们将翻译稿拆分并分享出来,并且给出英文对照。翻译的不对之处,请多多指教。
上篇内容:
REST API设计指导——译自Microsoft REST API Guidelines(三)
6 Client guidance 客户指导
To ensure the best possible experience for clients talking to a REST service, clients SHOULD adhere to the following best practices:
为了保证与 REST API 服务进行对接的客户端有更佳的体验,客户端应该遵循以下最佳实践:
6.1 Ignore rule 忽略规则
For loosely coupled clients where the exact shape of the data is not known before the call, if the server returns something the client wasn't expecting, the client MUST safely ignore it.
对于松散耦合的客户端调用,在调用之前不知道数据的确切定义和格式,如果服务器没用返回客户端预期的内容,客户端必须安全地忽略它。
Some services MAY add fields to responses without changing versions numbers.
Services that do so MUST make this clear in their documentation and clients MUST ignore unknown fields.
有的服务(接口)可以在响应中增加字段而不修改接口版本号。
如果有这种情况,接口文档中必须进行清晰明确地说明,并且客户端必须忽略掉这些未知的字段。
PS:一个已发布的在线接口服务,如果不修改版本而增加字段,那么一定不能影响已有的客户端调用。
6.2 Variable order rule 变量排序规则
Clients MUST NOT rely on the order in which data appears in JSON service responses.
客户端处理响应数据时一定不能依赖服务端JSON 响应数据字段的顺序。
PS:不要硬编码,JSON反序列化了解一下。
For example, clients SHOULD be resilient to the reordering of fields within a JSON object.
例如,当服务器返回的 JSON 对象中的字段顺序变了,客户端应当能够正确进行解析处理。
When supported by the service, clients MAY request that data be returned in a specific order.
当服务端支持时,客户端可以请求有特定顺序的数据。
PS:ODATA了解下,不仅能排序,还能指定字段顺序。
For example, services MAY support the use of the $orderBy querystring parameter to specify the order of elements within a JSON array.
例如,服务器可以支持使用查询参数 orderBy 来使服务器返回有序的 JSON 数组。
Services MAY also explicitly specify the ordering of some elements as part of the service contract.
服务端也可以在协议中明确指定某些元素按特定方式进行排序。
PS:比如评论按点赞数倒序排序。
For example, a service MAY always return a JSON object's "type" information as the first field in an object to simplify response parsing on the client.
例如,服务端可以每次返回 JSON 对象时都把 JSON 对象的类型信息作为第一个字段返回,进而简化客户端解析返回数据格式的难度。
Clients MAY rely on ordering behavior explicitly identified by the service.
客户端处理数据时可以依赖于服务端明确指定了的排序行为。
6.3 Silent fail rule 无声失效规则
Clients requesting OPTIONAL server functionality (such as optional headers) MUST be resilient to the server ignoring that particular functionality.
当客户端请求带可选功能参数的服务时(例如带可选的头部信息),必须对服务端的返回格式有一定兼容性,可以忽略某些特定功能。
PS:例如分页数、排序等自定义参数的支持和返回格式的兼容。
7 Consistency fundamentals 基础原则
7.1 URL structure URL 结构
Humans SHOULD be able to easily read and construct URLs.
用户应该能够轻松读懂和理解URL的结构。
PS:API URL路径结构应该是友好的易于理解的。甚至用户无需通过阅读API文档能够猜出相关结构和路径。
This facilitates discovery and eases adoption on platforms without a well-supported client library.
这有助于用户发现并简化接口的调用,即使平台没有良好的客户端SDK支持。
PS:为啥微信SDK那么多,API不友好是很大的一个原因。
An example of a well-structured URL is:
结构良好的 URL Demo:
https://api.contoso.com/v1.0/people/jdoe@contoso.com/inbox
PS:通过以上URL我们可以获知API的版本、people资源、用户标识(邮箱)、收件箱,而且很容易获知——这是jdoe的收件箱的API。
An example URL that is not friendly is:
格式不友好的 URL Demo:
https://api.contoso.com/EWS/OData/Users('jdoe@microsoft.com')/Folders('AAMkADdiYzI1MjUzLTk4MjQtNDQ1Yy05YjJkLWNlMzMzYmIzNTY0MwAuAAAAAACzMsPHYH6HQoSwfdpDx-2bAQCXhUk6PC1dS7AERFluCgBfAAABo58UAAA=')
PS:这是ODATA的API,不过目录标识不易于理解,没什么意义。
A frequent pattern that comes up is the use of URLs as values.
Services MAY use URLs as values.
For example, the following is acceptable:
一个常见的模式是使用 URL 作为值(参数)。
服务可以使用 URL 作为值。
PS:国内使用这种设计模式的比较少见,更倾向于是一些更通用的API使用这种模式。
例如下例(URL中,url参数传递了花式的鞋子这个资源):
https://api.contoso.com/v1.0/items?url=https://resources.contoso.com/shoes/fancy
7.2 URL length 长度
The HTTP 1.1 message format, defined in RFC 7230, in section [3.1.1][rfc-7230-3-1-1], defines no length limit on the Request Line, which includes the target URL.
在 RFC 7230 [3.1.1] [rfc-7230-3-1-1] 章节中定义的 HTTP 1.1 消息格式,定义 请求(包括 URL)没有长度限制。
From the RFC:
HTTP does not place a predefined limit on the length of a request-line. [...] A server that receives a request-target longer than any URI it wishes to parse MUST respond with a 414 (URI Too Long) status code.
HTTP不会对请求行的长度设置预定义的限制。 接收请求的目标服务如果发现当前URL长度超过预期解析的URI长度,必须响应414(URI 太长)HTTP状态码。
Services that can generate URLs longer than 2,083 characters MUST make accommodations for the clients they wish to support.
当 服务提供的 URL 长度超过 2083 个字符时必须考虑如何兼容所有将支持的客户端。
Here are some sources for determining what target clients support:
不同客户端支持的最长 URL 长度参见以下资料:
-
http://stackoverflow.com/a/417184
-
https://blogs.msdn.microsoft.com/ieinternals/2014/08/13/url-length-limits/
Also note that some technology stacks have hard and adjustable url limits, so keep this in mind as you design your services.
另请注意,某些技术栈对 url 限制有强制规定,因此请在设计服务时牢记这点。
7.3 Canonical identifier 规范的标识符
In addition to friendly URLs, resources that can be moved or be renamed SHOULD expose a URL that contains a unique stable identifier.
除了友好的 URL 之外,可以移动或重命名的资源也应该暴露一个包含唯一固定标识符的 URL。
PS:一般是暴露主键字段,也可以是其他唯一的易于理解的字段,比如姓名、标题、邮箱等等。
It MAY be necessary to interact with the service to obtain a stable URL from the friendly name for the resource, as in the case of the "/my" shortcut used by some services.
在与 服务 进行交互时可能需要通过友好的名称来获取资源固定的 URL,例如某些 服务使用的“/my”快捷方式。
PS:相比/my,我更喜欢/me。
The stable identifier is not required to be a GUID.
固定标识符不一定必需得是 GUID。
PS:GUID太长而且不易于理解和阅读,如果不是必须,尽量少用此字段。
An example of a URL containing a canonical identifier is:
包含规范标识符的 URL 示例(标识符比较友好):
https://api.contoso.com/v1.0/people/7011042402/inbox
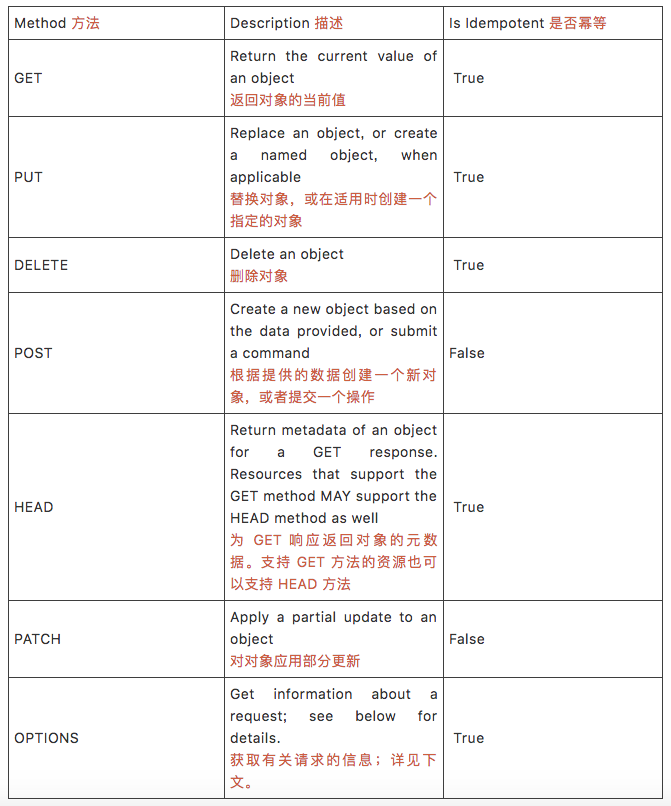
7.4 Supported methods 支持的方法
Operations MUST use the proper HTTP methods whenever possible, and operation idempotency MUST be respected.
HTTP methods are frequently referred to as the HTTP verbs.
操作必须尽可能使用正确的 HTTP 方法,且必须遵守操作幂等。
HTTP 方法又通常被称为 HTTP 动词。
PS:
幂等(idempotent、idempotence)是一个数学或计算机学概念,常见于抽象代数中。
幂等有一下几种定义:
对于单目运算,如果一个运算对于在范围内的所有的一个数多次进行该运算所得的结果和进行一次该运算所得的结果是一样的,那么我们就称该运算是幂等的。比如绝对值运算就是一个例子,在实数集中,有abs(a)=abs(abs(a))。
对于双目运算,则要求当参与运算的两个值是等值的情况下,如果满足运算结果与参与运算的两个值相等,则称该运算幂等,如求两个数的最大值的函数,有在在实数集中幂等,即max(x,x) = x。
相信你也没看懂,其实简单的来说,幂等的意味着对同一URL的多个请求应该返回同样的结果。
另外,GET用于信息获取,POST表示新增,PUT表示修改,DELETE表示删除。
The terms are synonymous in this context, however the HTTP specification uses the term method.
这些术语在此上下文下是同义词,但 HTTP 规范了如何使用这些术语的方法。
Below is a list of methods that Microsoft REST services SHOULD support.
下面是 Microsoft REST Service 应该支持的方法列表。
Not all resources will support all methods, but all resources using the methods below MUST conform to their usage.
并非所有资源都支持所有方法,但使用下面方法的所有资源必须遵从下面的用法。
7.4.1 POST
POST operations SHOULD support the Location response header to specify the location of any created resource that was not explicitly named, via the Location header.
POST 操作应该支持响应头部信息输出位置URL,通过响应头部信息中的Location信息明确已创建资源的URL位置。
PS:大概意思是,创建一个资源时,响应头部信息应输出新资源的路径URL。
As an example, imagine a service that allows creation of hosted servers, which will be named by the service:
例如,一个服务允许创建并命名托管服务器:
POST http://api.contoso.com/account1/servers
The response would be something like:
响应将会是这个样子:
-
201 Created
-
Location:http://api.contoso.com/account1/servers/server321
Where "server321" is the service-allocated server name.
“server321” 是服务创建的托管服务器的名称。
Services MAY also return the full metadata for the created item in the response.
服务也可以在响应中返回创建项的完整元数据。
7.4.2 PATCH
PATCH has been standardized by IETF as the method to be used for updating an existing object incrementally (see [RFC 5789][rfc-5789]).
PATCH 已经被 IETF 标准化,用来对已存在对象(已知资源)进行局部更新。(参考 [RFC 5789][rfc-5789])。
PS:PATCH方法是对PUT的补充,用来对已知资源进行局部更新。
Microsoft REST API Guidelines compliant APIs SHOULD support PATCH.
符合 Microsoft REST API 指南的 API 应该支持 PATCH 方法。
7.4.3 Creating resources via PATCH (UPSERT semantics) 通过 PATCH 创建资源(UPSERT 定义)
Services that allow callers to specify key values on create SHOULD support UPSERT semantics, and those that do MUST support creating resources using PATCH.
允许调用者在创建资源时指定 key 的服务应该支持 UPSERT ,支持此方法的服务也必须支持通过 PATCH 创建资源。
PS:UPSERT即更新插入,通过PATCH方法,允许指定Key来创建资源,例如通过PATCH方法创建UserId为88的用户。
Demo:
curl https://yourInstance.salesforce.com/services/data/v20.0/sobjects/Account/customExtIdField__c/11999 -H "Authorization: Bearer token" -H "Content-Type: application/json" -d @newrecord.json -X PATCH
{
"Name" : "California Wheat Corporation",
"Type" : "New Customer"
}
成功响应:
{
"id" : "00190000001pPvHAAU",
"errors" : [ ],
"success" : true
}
错误响应:
{
"message" : "The requested resource does not exist",
"errorCode" : "NOT_FOUND"
}
Because PUT is defined as a complete replacement of the content, it is dangerous for clients to use PUT to modify data.
因为 PUT 被定义为完全替换原数据,所以客户端直接使用 PUT方法修改数据是非常危险的。
PS:警告:请不要暴露UpdateTime、UpdateBy等字段。。。
Clients that do not understand (and hence ignore) properties on a resource are not likely to provide them on a PUT when trying to update a resource, hence such properties could be inadvertently removed.
当对资源属性不了解的客户端试图通过 PUT 更新数据时,由于对属性不了解,很可能忽略了某些属性,进而导致这些属性被无意删除。
PS:比如常见的,客户端某些字段就是不填导致的业务流程Game Over。
Services MAY optionally support PUT to update existing resources, but if they do they MUST use replacement semantics (that is, after the PUT, the resource's properties MUST match what was provided in the request, including deleting any server properties that were not provided).
服务可以支持 PUT 更新现有资源,但必须是完整替换(也就是说,在 PUT 后,资源的所有属性必须与请求中提供的内容相匹配,包括删除所有未提供的服务端属性)。
Under UPSERT semantics, a PATCH call to a nonexistent resource is handled by the server as a "create," and a PATCH call to an existing resource is handled as an "update." To ensure that an update request is not treated as a create or vice-versa, the client MAY specify precondition HTTP headers in the request.
在使用 UPSERT 的情况下,对不存在资源 使用PATCH 方法时,服务端应进行创建,已存在时,服务端应进行更新处理。为了确保更新请求不被视为创建(反之亦然),客户端可以在请求中指定预先定义的 HTTP 请求头。
The service MUST NOT treat a PATCH request as an insert if it contains an If-Match header and MUST NOT treat a PATCH request as an update if it contains an If-None-Match header with a value of "*".
如果一个 PATCH 请求包含一个 If-Match 请求头,那么服务端绝不能把这个 PATCH 请求当做插入(新增)处理,并且如果它包含一个值为“*”的 If-None-Match 请求头,则不能将该 PATCH 请求当做更新处理。
If a service does not support UPSERT, then a PATCH call against a resource that does not exist MUST result in an HTTP "409 Conflict" error.
如果服务不支持 UPSERT,那么对不存在资源的 PATCH 调用必须返回HTTP状态码为 "409 Conflict"的错误。
7.4.4 Options and link headers
OPTIONS allows a client to retrieve information about a resource, at a minimum by returning the Allow header denoting the valid methods for this resource.
OPTIONS 允许客户端检索有关资源的信息,至少可以返回表示该资源的有效方法的允许的头部信息。
PS:当发起跨域请求时,浏览器会自动发起OPTIONS请求进行检查。
In addition, services SHOULD include a Link header (see [RFC 5988][rfc-5988]) to point to documentation for the resource in question:
此外, 服务应该包括 Link header (参考 [RFC 5988][rfc-5988]) 以指向有关的文档资源:
Link: <{help}>; rel="help"
Where {help} is the URL to a documentation resource.
其中 {help} 是文档资源的 URL.
PS:例如分页时,返回下一步、上一步链接信息。这方面,大家可以参阅Github的API,如下所示:
Link: <https://api.github.com/user/repos?page=3&per_page=100>; rel="next",
<https://api.github.com/user/repos?page=50&per_page=100>; rel="last"
For examples on use of OPTIONS, see [preflighting CORS cross-domain calls][cors-preflight].
有关使用 OPTIONS 的示例,请参考 [preflighting CORS cross-domain calls][cors-preflight]。
7.5. Standard request headers 标准请求头
The table of request headers below SHOULD be used by Microsoft REST API Guidelines services. Using these headers is not mandated, but if used they MUST be used consistently.
表的请求头应该遵循微软REST API服务规范。使用这些标头不是必须的,但是如果用到,那么它们必须使用一致。
All header values MUST follow the syntax rules set forth in the specification where the header field is defined. Many HTTP headers are defined in RFC7231, however a complete list of approved headers can be found in the IANA Header Registry."
所有头部值必须遵循在定义头部字段的规范中所阐述的语法规则(syntax rules )。在HTC721中定义了许多HTTP报头,但是在IANA报头注册表中可以找到完整的批准报头列表。
Header| Type |Description
头部 | 类型 | 描述
Authorization| String |Authorization header for the request
授权 | 字符 | 授权头部
Date |Date |Timestamp of the request, based on the client's clock, in RFC 5322 date and time format. The server SHOULD NOT make any assumptions about the accuracy of the client's clock. This header MAY be included in the request, but MUST be in this format when supplied. Greenwich Mean Time (GMT) MUST be used as the time zone reference for this header when it is provided. For example: Wed, 24 Aug 2016 18:41:30 GMT. Note that GMT is exactly equal to UTC (Coordinated Universal Time) for this purpose.
日期 | 日期类型 | 请求时间戳,在RFC 5322日期和时间格式中。服务器不应该信任客户端时间。该报头可以包含在请求中,但在提供时必须以这种格式。当提供该报头时,必须使用格林尼治平均时间(GMT)作为时区参考。例如:星期三,2016年8月24日18:41:30 GMT注意到GMT完全等于UTC(协调的通用时间)。
Accept| Content type |The requested content type for the response such as:
接收 | 内容类型 | 请求响应的请求内容类型,例如application/xml 、text/xml 、application/json 、text/javascript (for JSONP)
Per the HTTP guidelines, this is just a hint and responses MAY have a different content type, such as a blob fetch where a successful response will just be the blob stream as the payload. For services following OData, the preference order specified in OData SHOULD be followed.
根据HTTP指南,这只是一个提示,并且响应可能有不同的内容类型,例如获取一个对象,只有返回了对象流才算是成功的返回。如果服务是OData协议,应该遵循ODATA中指定的优先要求和顺序。
Accept-Encoding | Gzip, deflate | REST endpoints SHOULD support GZIP and DEFLATE encoding, when applicable. For very large resources, services MAY ignore and return uncompressed data.
Accept-Encoding | Gzip, deflate | 在适用时,REST API应支持GZIP和deflate 。对于非常大的资源,服务可以忽略和返回未压缩的数据。
PS:Gzip, deflate 是常用的HTPP压缩方式,对于REST API,也是可以支持HTTP动态压缩的。不过如果数据量比较大,压缩会比较消耗CPU资源。所以对于大数据,请慎重。
Accept-Language | "en", "es", etc. |Specifies the preferred language for the response. Services are not required to support this, but if a service supports localization it MUST do so through the Accept-Language header.
Accept-Language | en,es,etc | 指定响应的首选语言。服务不要求必须支持,但是如果服务支持本地化,它必须通过Accept-Language来指定语言。
Accept-Charset| Charset type like "UTF-8"| Default is UTF-8, but services SHOULD be able to handle ISO-8859-1.
Accept-Charset | 字符类型例如UTF-8 | 默认是UTF-8,但是服务应该能处理ISO-8859-1
Content-Type| Content type |Mime type of request body (PUT/POST/PATCH)
Content-Type | 内容类型 | 根据MIME类型的请求对应的主体(put/post/patch)
PS:常见的,我们通过内容类型application/json 来获取JSON数据,通过“application/xml”来获取XML输出。
Prefer | return=minimal, return=representation | If the return=minimal preference is specified, services SHOULD return an empty body in response to a successful insert or update. If return=representation is specified, services SHOULD return the created or updated resource in the response. Services SHOULD support this header if they have scenarios where clients would sometimes benefit from responses, but sometimes the response would impose too much of a hit on bandwidth.
Prefer | 返回=极小值 ,返回=代表事物 | 如果指定了返回=最小优先级,则服务应响应成功插入或更新返回空主体。如果指定了Reale=表示,服务应该返回响应中创建的或更新的资源。如果客户端通过指定返回内容有实际意义或价值,或者有时响应内容过多会对带宽造成太大的影响,那么服务就应该支持这个头部。
PS:通过将Prefer标头设置可以省略响应正文。如果Prefer标头设置为return-no-content,则服务将使用状态代码204(No Content)和响应标头进行响应。也就是说,创建一个大对象时,客户端如果指定了Prefer为return-no-content,服务端可以返回204而无需返回任何内容,这样能提供请求速度,节约大量带宽。
If-Match, If-None-Match, If-Range |String |Services that support updates to resources using optimistic concurrency control MUST support the If-Match header to do so. Services MAY also use other headers related to ETags as long as they follow the HTTP specification.
If-Match, If-None-Match, If-Range | 字符串| 使用乐观并发控制支持资源更新的服务必须支持IF匹配头这样做。服务也可以使用与ETAG相关的其他头文件,只要它们遵循HTTP规范。
7.6. Standard response headers 标准响应报头
Services SHOULD return the following response headers, except where noted in the "required" column.
服务应返回以下响应标题,除非在“必需”栏中注明。
Response Header | Required | Description
响应报头 | 必填 | 描述
Date | All responses | Timestamp the response was processed, based on the server's clock, in RFC 5322 date and time format. This header MUST be included in the response. Greenwich Mean Time (GMT) MUST be used as the time zone reference for this header. For example: Wed, 24 Aug 2016 18:41:30 GMT. Note that GMT is exactly equal to UTC (Coordinated Universal Time) for this purpose.
日期 | 所有请求| 服务执行时间撮,以RFC 5322的日期和时间格式处理响应。这个头必须包含在响应中。格林尼治平均时间(GMT)必须用作该报头的时区参考。例如:星期三,2016年8月24日18:41:30 GMT注意到GMT完全等于UTC(协调的通用时间)。
Content-Type | All responses | The content type
内容类型 | 所有的请求 | 内容类型
Content-Encoding | All responses GZIP or DEFLATE, as appropriate
Content-Encoding |所有的请求尽可能支持GZIP或DEFLATE,除非特殊情况
Preference-Applied When specified in request Whether a preference indicated in the Prefer request header was applied
Preference-Applied在请求中指定是否应用了Prefer请求标头。
ETag | When the requested resource has an entity tag | The ETag response-header field provides the current value of the entity tag for the requested variant. Used with If-Match, If-None-Match and If-Range to implement optimistic concurrency control.
ETAG | 当请求的资源具有实体标签时| ETAG响应头字段为所请求的变体提供实体标签的当前值。与If-Match, If-None-Match、If-Range来实现乐观并发控制。
7.7. Custom headers 自定义选项
Custom headers MUST NOT be required for the basic operation of a given API.
基本的API操作禁止定义自定义标头。
Some of the guidelines in this document prescribe the use of nonstandard HTTP headers. In addition, some services MAY need to add extra functionality, which is exposed via HTTP headers. The following guidelines help maintain consistency across usage of custom headers.
本文档中的一些准则规定了使用非标准HTTP标头。 此外,某些服务可能需要添加额外的功能,这些功能通过HTTP标头公开。 以下准则有助于保持自定义标头使用的一致性。
Headers that are not standard HTTP headers MUST have one of two formats:
不是标准HTTP标头必须支持以下两种格式之一:
1. A generic format for headers that are registered as "provisional" with IANA (RFC 3864)
用IANA注册为“临时”的标题的通用格式(RFC 3864)
2. A scoped format for headers that are too usage-specific for registration
为注册使用过特定的头文件的范围格式
These two formats are described below.
下面介绍这两种格式。
7.8. Specifying headers as query parameters
将页眉指定为查询参数
Some headers pose challenges for some scenarios such as AJAX clients, especially when making cross-domain calls where adding headers MAY not be supported. As such, some headers MAY be accepted as Query Parameters in addition to headers, with the same naming as the header:
一些标头可能不兼容一些场景(如Ajax客户端),尤其是在跨域调用时,可能不支持添加标头。因此,除了标头之外,可以将一些标头作为查询参数接受,与标头相同的命名:
Not all headers make sense as query parameters, including most standard HTTP headers.
并非所有的标头都是有意义的查询参数,包括大多数标准的HTTP头。
The criteria for considering when to accept headers as parameters are:
考虑何时接受标头作为参数的标准是:
1. Any custom headers MUST be also accepted as parameters.
任何自定义标头也必须作为参数接受。
2. Required standard headers MAY be accepted as parameters.
请求的标准标头也可以作为参数接受。
3. Required headers with security sensitivity (e.g., Authorization header) MIGHT NOT be appropriate as parameters; the service owner SHOULD evaluate these on a case-by-case basis.
具有安全敏感性的必填标头(例如,授权标头)可能不适合作为参数;服务所有者应该根据具体情况具体分析。
The one exception to this rule is the Accept header. It's common practice to use a scheme with simple names instead of the full functionality described in the HTTP specification for Accept.
这个规则的一个例外是Accept标头。通常使用具有简单名称的方案,而不是使用HTTP规范中描述的Accept的完整功能。
7.9. PII parameters PII(个人可识别信息)参数
Consistent with their organization's privacy policy, clients SHOULD NOT transmit personally identifiable information (PII) parameters in the URL (as part of path or query string) because this information can be inadvertently exposed via client, network, and server logs and other mechanisms.
与其组织的隐私策略一致,客户端不应该在URL中发送个人可识别信息(PII)参数(作为路径或查询字符串的一部分),因为可以通过客户端、网络和服务器日志和其他机制不经意地公开该信息。
PS:PII——个人可标识信息。比如家庭地址,身份证信息。
Consequently, a service SHOULD accept PII parameters transmitted as headers.
因此,一个服务应该接受PII参数作为头部参数传输。
However, there are many scenarios where the above recommendations cannot be followed due to client or software limitations. To address these limitations, services SHOULD also accept these PII parameters as part of the URL consistent with the rest of these guidelines.
然而,由于客户端或软件限制,有许多情况下无法遵循上述建议。为了解决这些限制,服务还应该接受这些PII参数作为URL的一部分,并与这些指南的其余部分保持一致。
Services that accept PII parameters -- whether in the URL or as headers -- SHOULD be compliant with privacy policy specified by their organization's engineering leadership. This will typically include recommending that clients prefer headers for transmission and implementations adhere to special precautions to ensure that logs and other service data collection are properly handled.
接受PII参数的服务——无论是在URL中还是作为头部——应该符合由其组织的领导层指定的隐私策略。这通常包括推荐的客户端传输的标头,并且实现遵循特殊的预防措施,以确保正确处理日志和其他服务数据的收集。
7.10. Response formats 响应格式
For organizations to have a successful platform, they must serve data in formats developers are accustomed to using, and in consistent ways that allow developers to handle responses with common code.
一个成功的平台,必须以开发人员习惯使用的格式以及允许开发人员使用公共Http代码处理响应。
Web-based communication, especially when a mobile or other low-bandwidth client is involved, has moved quickly in the direction of JSON for a variety of reasons, including its tendency to be lighter weight and its ease of consumption with JavaScript-based clients.
基于Web的通信,特别是当涉及移动或其他低带宽客户机时,由于各种原因,已经迅速向JSON格式方向发展,主要是由于其更轻量以及易于与JavaScript交互。
JSON property names SHOULD be camelCased.
JSON属性名称应该符合CAMELCASE命名规范。
Services SHOULD provide JSON as the default encoding.
服务应该提供JSON格式作为默认输出格式。
7.10.1. Clients-specified response format
客户端指定响应格式
In HTTP, response format SHOULD be requested by the client using the Accept header. This is a hint, and the server MAY ignore it if it chooses to, even if this isn't typical of well-behaved servers. Clients MAY send multiple Accept headers and the service MAY choose one of them.
在HTTP中,客户端应该使用Accept标头请求响应格式。 服务端可以选择性的忽略,即使这不是典型的良好的服务。 客户端可以发送多个Accept标头,服务可以选择其中一个格式进行返回。
The default response format (no Accept header provided) SHOULD be application/json, and all services MUST support application/json.
默认的响应格式(没有提供Accept报头)应该是application/json,并且所有服务必须支持application/json。
Accept Header | Response type | Notes
接受标头 | 响应类型 | 备注
application/json| Payload SHOULD be returned as JSON | Also accept text/javascript for JSONP cases
application/json | 必须是返回json格式 | 同样接受JSONP请求的text/JavaScript
GET https://api.contoso.com/v1.0/products/user
Accept: application/json
7.10.2. Error condition responses 错误的条件响应
For nonsuccess conditions, developers SHOULD be able to write one piece of code that handles errors consistently across different Microsoft REST API Guidelines services. This allows building of simple and reliable infrastructure to handle exceptions as a separate flow from successful responses. The following is based on the OData v4 JSON spec. However, it is very generic and does not require specific OData constructs. APIs SHOULD use this format even if they are not using other OData constructs.
对于非成功条件,开发人员应该能够编写一段代码进行处理,以在不同的Microsoft REST API准则服务中一致地处理类似错误。 这允许构建简单可靠的基础架构来处理异常,作为成功响应的独立的处理流程。 以下是基于OData v4 JSON规范。 但是,它是非常通用的,不需要指定特定的OData结构。 API应该使用这种格式,即使它们没有使用其他OData结构。
The error response MUST be a single JSON object. This object MUST have a name/value pair named "error." The value MUST be a JSON object.
错误响应必须是单个JSON对象。此对象必须有名为“错误”的键值对,该值必须是JSON对象。
This object MUST contain name/value pairs with the names "code" and "message," and it MAY contain name/value pairs with the names "target," "details" and "innererror."
这个对象必须包含名称为“code”和“message”的键值对,它可能包含名称为“target”、“.”和“innererror”的键值对。
The value for the "code" name/value pair is a language-independent string. Its value is a service-defined error code that SHOULD be human-readable. This code serves as a more specific indicator of the error than the HTTP error code specified in the response. Services SHOULD have a relatively small number (about 20) of possible values for "code," and all clients MUST be capable of handling all of them. Most services will require a much larger number of more specific error codes, which are not interesting to all clients. These error codes SHOULD be exposed in the "innererror" name/value pair as described below. Introducing a new value for "code" that is visible to existing clients is a breaking change and requires a version increase. Services can avoid breaking changes by adding new error codes to "innererror" instead.
“code”的值是与语言无关的字符串。它的值是该服务定义的错误代码,应该是人类可读的易于理解的。与响应中指定的HTTP错误代码相比,此代码用作错误的更具体的指示。服务应该有一个相对小的数量(约20)错误码可能的范围值,“所有客户端必须能够处理所有的错误码。大多数服务将需要更大数量的更具体的错误代码以满足所有的客户端请求。这些错误代码应在“内部错误”中公开,如下所述。为现有客户端可见的“代码”引入新值是一个突破性的改变,需要增加版本。服务可以通过向“内部错误”添加新的错误代码来避免破坏更改。
The value for the "message" name/value pair MUST be a human-readable representation of the error. It is intended as an aid to developers and is not suitable for exposure to end users. Services wanting to expose a suitable message for end users MUST do so through an annotation or custom property. Services SHOULD NOT localize "message" for the end user, because doing so might make the value unreadable to the app developer who may be logging the value, as well as make the value less searchable on the Internet.
“消息”键值对的值必须是错误提示消息,必须是可读且易于理解。它的目的是帮助开发人员,不适合暴露给最终用户。希望为最终用户公开合适消息的服务必须通过注释或自定义属性进行。服务不应该为最终用户本地化“消息”,因为这样做可能使值对于可能正在记录值的应用程序开发人员不可读,并且使值在因特网上可搜索性降低。
The value for the "target" name/value pair is the target of the particular error (e.g., the name of the property in error).
“目标”键值对的值是特定错误的目标(例如,错误的属性名称)。
The value for the "details" name/value pair MUST be an array of JSON objects that MUST contain name/value pairs for "code" and "message," and MAY contain a name/value pair for "target," as described above. The objects in the "details" array usually represent distinct, related errors that occurred during the request. See example below.
“.”名称/值对的值必须是JSON对象的数组,该数组必须包含“code”和“message”的名称/值对,并且允许包含“target”的名称/值对,如上所述。“细节”数组中的对象通常表示在请求期间发生的不同的、相关的错误。见下面的例子。
The value for the "innererror" name/value pair MUST be an object. The contents of this object are service-defined. Services wanting to return more specific errors than the root-level code MUST do so by including a name/value pair for "code" and a nested "innererror." Each nested "innererror" object represents a higher level of detail than its parent. When evaluating errors, clients MUST traverse through all of the nested "innererrors" and choose the deepest one that they understand. This scheme allows services to introduce new error codes anywhere in the hierarchy without breaking backwards compatibility, so long as old error codes still appear. The service MAY return different levels of depth and detail to different callers. For example, in development environments, the deepest "innererror" MAY contain internal information that can help debug the service. To guard against potential security concerns around information disclosure, services SHOULD take care not to expose too much detail unintentionally. Error objects MAY also include custom server-defined name/value pairs that MAY be specific to the code. Error types with custom server-defined properties SHOULD be declared in the service's metadata document. See example below.
“内部错误”名称/值对的值必须是一个对象。这个对象的内容是服务定义的。希望返回比根级代码更具体的错误的服务必须通过包括“code”的名称/值对和嵌套的“innererror”来返回。在评估错误时,客户机必须遍历所有嵌套的“内部错误”,并选择他们理解的最深的一个。该方案允许服务在层次结构中的任何地方引入新的错误代码,而不破坏向后兼容性,只要仍然出现旧的错误代码。服务可以返回不同级别的深度和细节给不同的呼叫者。例如,在开发环境中,最深的“innererror”可能包含可以帮助调试服务的内部信息。为了防止围绕信息公开的潜在安全隐患,服务应该注意不要无意中暴露太多的细节。错误对象还可以包括特定于代码的自定义服务器定义的名称/值对。自定义服务器定义属性的错误类型应该在服务的元数据文档中声明。见下面的例子。
Error responses MAY contain annotations in any of their JSON objects.
错误的请求可能包含他们的json对象的任何注释。
We recommend that for any transient errors that may be retried, services SHOULD include a Retry-After HTTP header indicating the minimum number of seconds that clients SHOULD wait before attempting the operation again.
我们建议,可以重试任何瞬态误差,服务应该包括重试HTTP标头指示秒的最低数量,客户应该在试图再次操作的等待后。
ErrorResponse : Object 错误的请求:对象
Property |Type |Required |Description
特性 |类型 | 必填 | 描述
error |Error | ✔ |The error object.
错误 |错误 | 正确 | 错误的对象
Error : Object 错误的对象
Property | Type |Required |Description
特性 | 类型 | 必填 | 描述
code | String (enumerated) ✔ |One of a server-defined set of error codes.
代码 | 字符(列举)| |服务器定义的错误代码集之一。
message String ✔ A human-readable representation of the error.
消息| 字符| |错误的人类可读表示。
target String The target of the error.
目标 | 字符 | 误差的目标。
details Error[] An array of details about specific errors that led to this reported error.
详情 |错误| 有关导致此报告错误的特定错误的详细信息的数组
innererror InnerError An object containing more specific information than the current object about the error.
内部错误 |内部错误 |一个对象,包含比当前对象更具体的有关错误的信息。
InnerError : Object 内部错误:对象
Property | Type |Required | Description
特性 | 类型 | 必填 | 描述
code |String | A more specific error code than was provided by the containing error.
代码 | 字符 | 一个比包含错误提供的更具体的错误代码。
innererror | InnerError | An object containing more specific information than the current object about the error.
内部错误 | 内部错误 | 包含与当前对象有关错误的更具体信息的对象
Examples 例如
Example of "innererror":
{
"error": {
"code": "BadArgument",
"message": "Previous passwords may not be reused",
"target": "password",
"innererror": {
"code": "PasswordError",
"innererror": {
"code": "PasswordDoesNotMeetPolicy",
"minLength": "6",
"maxLength": "64",
"characterTypes": ["lowerCase","upperCase","number","symbol"],
"minDistinctCharacterTypes": "2",
"innererror": {
"code": "PasswordReuseNotAllowed"
}
}
}
}
}
In this example, the most basic error code is "BadArgument," but for clients that are interested, there are more specific error codes in "innererror." The "PasswordReuseNotAllowed" code may have been added by the service at a later date, having previously only returned "PasswordDoesNotMeetPolicy." Existing clients do not break when the new error code is added, but new clients MAY take advantage of it. The "PasswordDoesNotMeetPolicy" error also includes additional name/value pairs that allow the client to determine the server's configuration, validate the user's input programmatically, or present the server's constraints to the user within the client's own localized messaging.
在这个示例中,最基本的错误代码是“BadArgument”,但对于客户端,在“innererror”中有更多的特定错误代码。服务可能在稍后的日期添加了“PasswordReuseNotAllo.”代码,之前只返回了“PasswordDoesNotMeetPolicy”。现有客户端在添加新错误代码时不会中断,但新客户端可以利用它。“PasswordDoesNotMeetPolicy”错误还包括额外的名称/值对,这些名称/值对允许客户端确定服务器的配置、以编程方式验证用户的输入、或在客户端自己的本地化消息传递中向用户呈现服务器的约束。
Example of "details":
{
"error": {
"code": "BadArgument",
"message": "Multiple errors in ContactInfo data",
"target": "ContactInfo",
"details": [
{
"code": "NullValue",
"target": "PhoneNumber",
"message": "Phone number must not be null"
},
{
"code": "NullValue",
"target": "LastName",
"message": "Last name must not be null"
},
{
"code": "MalformedValue",
"target": "Address",
"message": "Address is not valid"
}
]
}
}
In this example there were multiple problems with the request, with each individual error listed in "details."
在这个示例中,请求存在多个问题,每个细节错误都在“details”中列出。
7.11. HTTP Status Codes 请求状态代码
Standard HTTP Status Codes SHOULD be used; see the HTTP Status Code definitions for more information.
应该使用标准的HTTP状态代码;有关更多信息,请参见HTTP状态代码定义。
7.12. Client library optional 客户端库可选
Developers MUST be able to develop on a wide variety of platforms and languages, such as Windows, macOS, Linux, C#, Python, Node.js, and Ruby.
开发人员必须能够在各种平台和语言上进行开发,比如Windows、macOS、Linux、C#、Python、Node.js和Ruby。
Services SHOULD be able to be accessed from simple HTTP tools such as curl without significant effort.
服务应该能够从简单的HTTP工具(如curl)访问,而不需要付出很大的努力。
Service developer portals SHOULD provide the equivalent of "Get Developer Token" to facilitate experimentation and curl support.
开发者中心应该提供类似“获得开发者令牌”的支持,以便开发者联调和使用CURL测试。
出处:http://www.cnblogs.com/codelove/
如果喜欢作者的文章,请关注【CodeSpirit-码灵】公众号以便第一时间获得最新内容。本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
静听鸟语花香,漫赏云卷云舒。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号