图的遍历/存储
前言:
我来炒冷饭了哈哈哈哈哈哈哈哈哈
图好像炸了,讲究着看
注:标星号为选修
OI-图(\(graph\))的存储
🤮的遍历
预估时间5-20分钟
十分简单
图的应用(后面的内容)
- 连通性问题:判断图的连通性、求连通分量
- 路径问题:最短路径、最长路径、所有简单路径
- 树相关问题:最小生成树、最近公共祖先
- 网络流问题:最大流、最小割
- 匹配问题:二分图匹配、一般图匹配
图 —— 是啥
定义
图(graph)就是一堆点和一堆线做的,就像:
图1.1 图的栗子🌰
严格来看,就是这么说的:
图\(G\)是一个有序二元组\((V,E)\),其中:
- \(V\)是顶点集,包含n个顶点\({v_1, v_2, ..., v_n}\)
- \(E\)是边集,包含m条边\({e_1, e_2, ..., e_m}\),每条边连接V中的两个顶点
分类
- 有向图与无向图:边是否有方向性
- 加权图与无权图:边是否带有权值(边边上是否有数字)
- 稀疏图与稠密图:边数m与完全图边数n(n-1)/2的比值
- 连通图与非连通图:任意两点间是否存在路径,也就是是不是一块的
有向图就是有箭头的图图
就像这个:
图1.2 有向图的栗子🌰
而无向图可以看成两个有向边(就是有箭头的边边)拼起来的,就像这个:

图1.3 无向图的栗子🌰
当然,限于篇幅,其他的就不画图了
邻接矩阵(Adjacency Matrix)
对于 AdjMart[i][j] 表示 i 和 j 是否是有一条边
比如
就是一个典型的无向图,即:
图2.1 栗子🌰
停下来Think一下
思考思考思考:和u卡拉尔吉林省地方好几顿饭v看地方v后即可发现下文的dsv特点!!!
复杂度 & 适用图种
ta的优缺点也很明显:
使用图种:
邻接表(Adjacency List)
邻接表就更直接,直接存储i的所有子节点
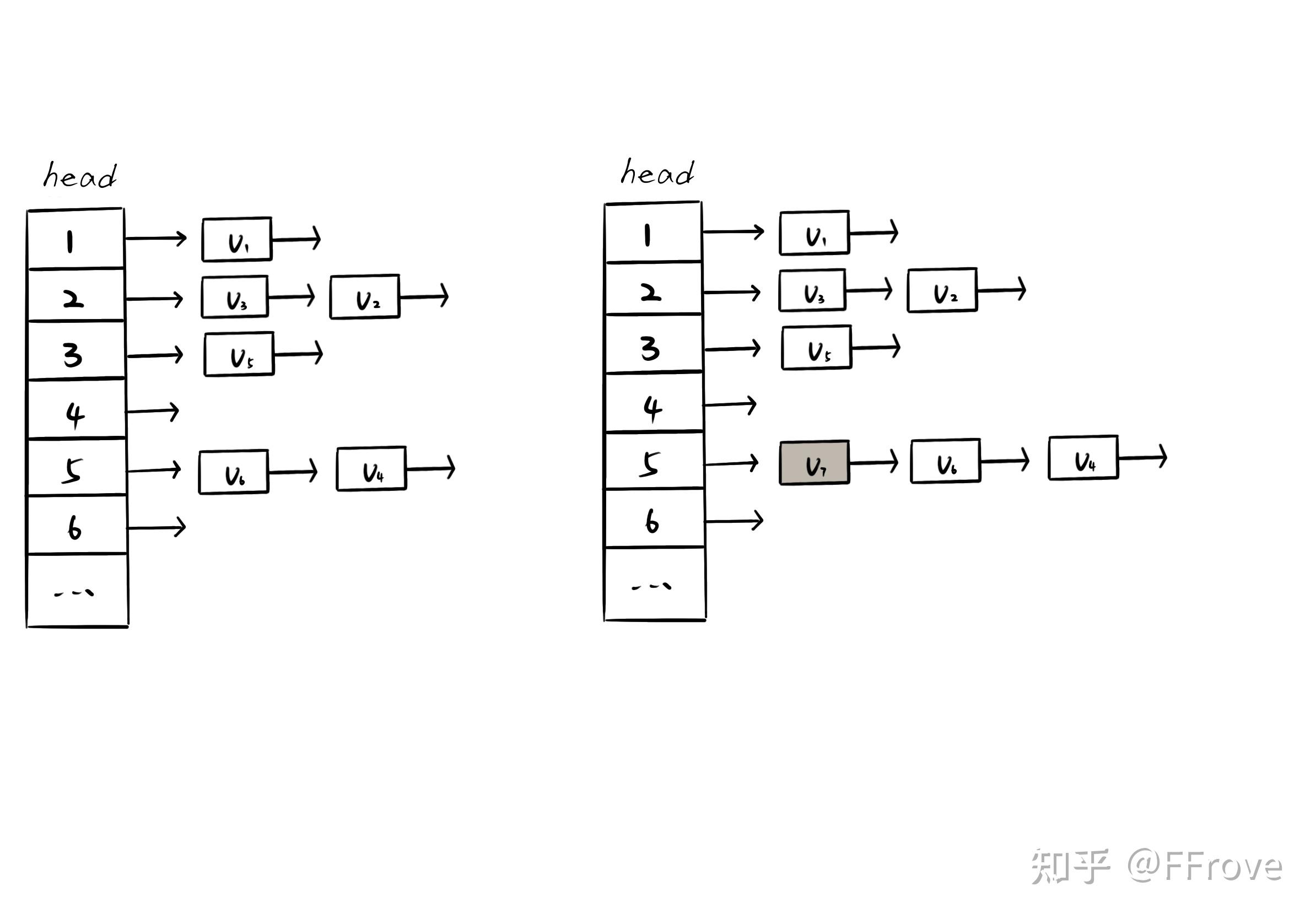
图3.1 邻接表存储方式(网上的图片,自己懒的❀)
比如,插入\((1, 2), (2, 3), (2, 5), (3, 6), (5, 4), (5, 1)\)六条边后,邻接表的信息如下:
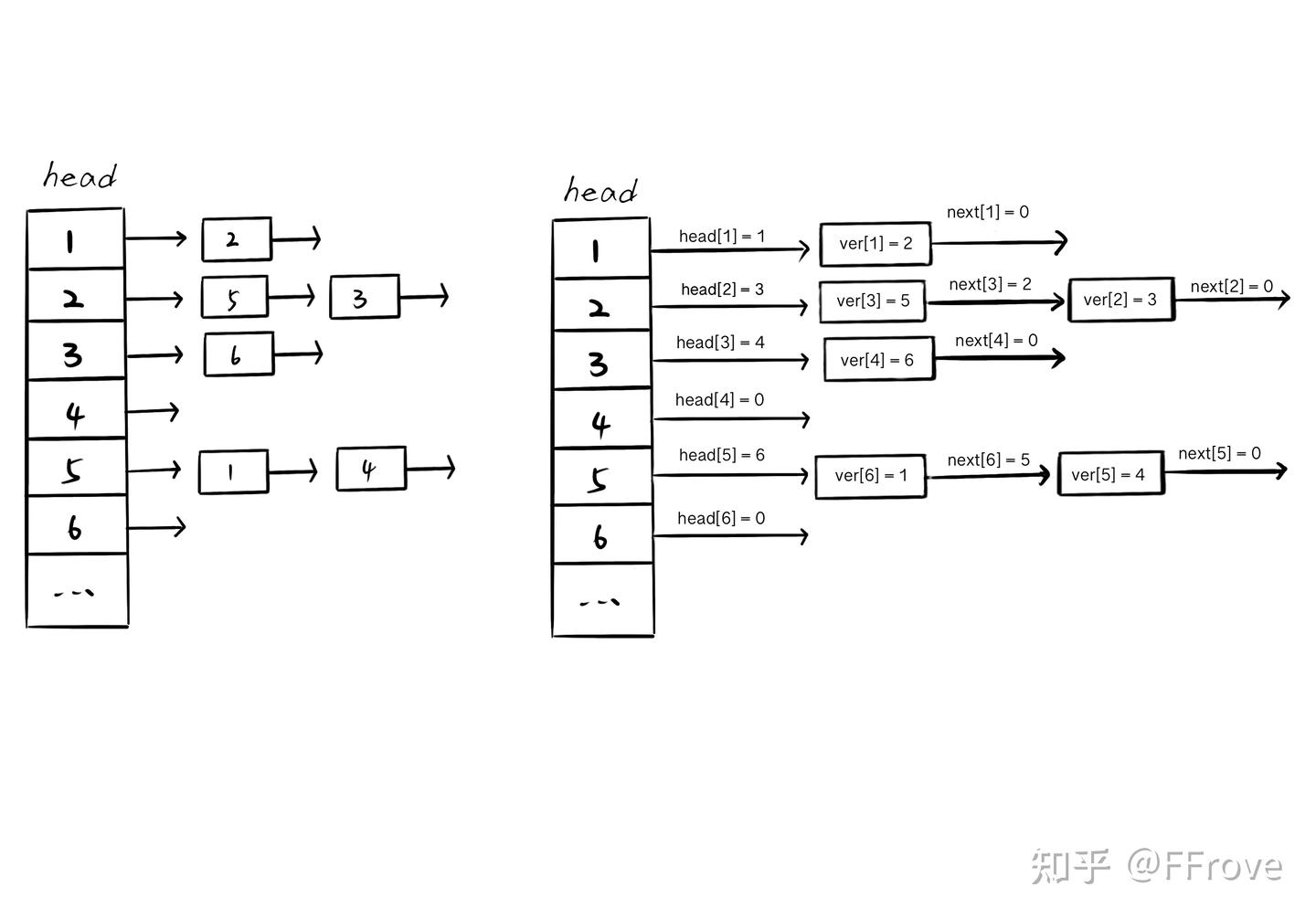
图3.2 邻接表存储方式2(也是网上的图片,自己懒的❀)
这个图呢:
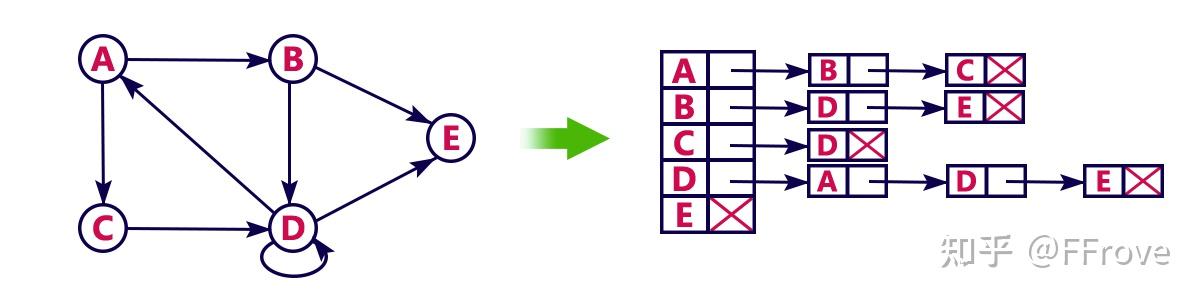
图3.3 邻接表存储方式3(也是网上的图片,自己懒的❀)
关于邻接表,有两种写法
一种是链式前向星,比较复杂,也就是3.1和3.2两张图
另一种是vector存图,也就是3.3,明显要简单很多,给出例子:
const int N = 1e5 + 10;
struct Edge
{
int to; // 终点
int w; // 边的权值
};
vector <Edge> g[N]; // g[i] 中 i 表示起始位置
// 加边(带权)
void add(int from, int to, int c)
{
Edge e = {to, c};
g[from].push_back(e); // 向 vector 的最后添加一条边
}
// 遍历逻辑
void print(int a)
{
for (int i = 0; i < g[a].size(); i ++ )
// Code
}
如果不带权,有两种写法:
- 可以把w 始终设为1
- 删掉w
owo
复杂度
- 查询边是否存在:O(d),其中d为顶点的度
- 遍历某个顶点的所有邻接点:O(d)
- 空间复杂度:O(n + m)
使用图种:
all The graph
边集数组
struct Edge
{
int u, v, w; // 起点,终点,权值
};
vector<Edge> edges;
- 优点:结构简单,便于按边操作
- 缺点:查找某个顶点的邻接边效率低
其他的乱七八糟十字链表或是邻接多重表诸如此类
十字链表:用于有向图,同时记录出边和入边
邻接多重表:用于无向图,避免边的重复存储
其他的都懒得查了
这两个也是搜的
结构选择
| 场景 | 推荐结构 | 理由 |
|---|---|---|
| n ≤ 500的稠密图 | 邻接矩阵 | 实现简单,常数小 |
| n ≤ 10⁵, m ≤ 2×10⁵ | 邻接表(vector) | 空间效率高,遍历快 |
| 需要频繁加删边 | 邻接表(链式前向星) | 动态操作效率高 |
| Kruskal算法 | 边集数组 | 便于排序所有边 |
| 需要反向边 | 邻接表+反向边 | 网络流算法需要 |
OI-图(\(graph\))的遍历
DFS/大法师
深度优先搜索遵循"尽可能深"的原则,沿着一条路径不断深入,直到无法继续,然后回溯。
vector<bool> vis(n, false);
void dfs(int u)
{
vis[u] = true;
// 处理顶点u
for(int v : G[u])
{
if(!vis[v])
{
dfs(v);
}
}
}
时间复杂度:O(n + m),每个顶点和边都被访问一次
空间复杂度:O(n),递归栈深度最坏为O(n)
DFS非递归实现
vector<int> st;
while (!st.empty())
{
int u = st.back();
if (歪比巴布)
st.push_bacl(玛卡巴卡);
else
st.pop_back();
}
DFS求连通块分量技术或是二分图也可能是拓扑排序或是诸如此类
int count()
{
vector<bool> vis(n, false);
int count = 0;
for(int i = 0; i < n; i++)
{
if(!vis[i])
{
dfs(i);
count++;
}
}
return count;
}
二分图(给你也看不懂)
拓扑(给你也看不懂)
awawawa
我太懒了
BFS/爸法师
广度优先搜索按照"层次"进行搜索,先访问离起点最近的顶点。
模板先啦~
void bfs(int start)
{
vector<bool> vis(n, false);
queue<int> q;
vis[start] = true;
q.push(start);
while(!q.empty())
{
int u = q.front();
q.pop();
// 处理顶点u
for(int v : G[u])
{
if(!vis[v])
{
vis[v] = true;
q.push(v);
}
}
}
}
时间复杂度:O(n + m)
空间复杂度:O(n),队列最大长度
BFS 求顶点层次
vector<int> bfs start)
{
vector<int> dist(n, -1);
queue<int> q;
dist[start] = 0;
q.push(start);
while(!q.empty())
{
int u = q.front();
q.pop();
for(int v : G[u])
{
if(dist[v] == -1)
{
dist[v] = dist[u] + 1;
q.push(v);
}
}
}
return dist;
}
*BFS->Dijkstra
优先处理权小的(贪心)
void dijkstra(vector<vector<pair<int, int>>> &g, int s)
{
queue<pair<int, int>, vector<pair<int, int>>, greater<>> pq;
vector<int> dist(g.size(), INT_MAX);
pq.emplace(dist[s] = 0, s);
while (!pq.empty())
{
auto [d, u] = pq.top();
pq.pop();
if (d > dist[u])
continue;
for (auto [v, w] : g[u])
if (dist[v] > d + w)
pq.emplace(dist[v] = d + w, v);
}
}
优先队列的呢:
void dijkstra(vector<vector<pair<int,int>>>& g, int s)
{
priority_queue<pair<int,int>, vector<pair<int,int>>, greater<>> pq;
vector<int> dist(g.size(), INT_MAX);
pq.emplace(dist[s]=0, s);
while (!pq.empty())
{
auto [d,u] = pq.top(); pq.pop();
if (d > dist[u]) continue;
for (auto [v,w] : g[u])
if (dist[v] > d+w) pq.emplace(dist[v]=d+w, v);
}
}
完结撒花!!!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号