
第一次个人编程作业
链接:GitHub链接
计算模块接口的设计与实现过程:
经历了C的折磨,以及百度的介绍,我决定使用python。使用jieba库(分词),gensim库中TF-IDF算法来计算文本相似度。
代码流程图如下:

代码原理:
1.读取停用词,利用jieba分词。
通过使用jieba库中的jieba.lcut(s)函数,将文本在精确模式(即不存在冗余单词)下切分开。并将分词的结果保存在words中。再利用读取的停用词,将words中的停用词去掉。
代码如下:
#分词
def cut_words(file):
with open(file, 'r',encoding="utf-8") as f:
text = f.read()
words = jieba.lcut(text)
return words
#去词
def drop_Disable_Words(cut_res,stopwords):
res = []
for word in cut_res:
if word in stopwords or word =="\n" or word =="\u3000":
continue
res.append(word)
return res
2.利用TF-IDF模型计算相似度。
TF-IDF是一种用于信息检索与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。


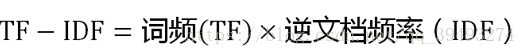
通过TF-IDF可知每个词在文章的占比权重,再对比两个文本的相似度。
代码如下:
# 建立TF-IDF模型
tfidf = models.TfidfModel(doc_vectors)
tfidf_vectors = tfidf[doc_vectors]
# 使用TF-IDF模型计算相似度
TF_IDF(tfidf_vectors, query_bow, respath)
# 建立TF-IDF计算函数
def TF_IDF(tfidf_vectors, query_bow, respath):
try:
index = similarities.MatrixSimilarity(tfidf_vectors)
sims = index[query_bow]
ans = 1 - float(list(enumerate(sims))[0][1])
create_file(respath, "TF-IDF模型计算结果为:" + str('%.2f\n' % ans))
except:
create_file(respath, "TF-IDF模型计算结果为:1.00")
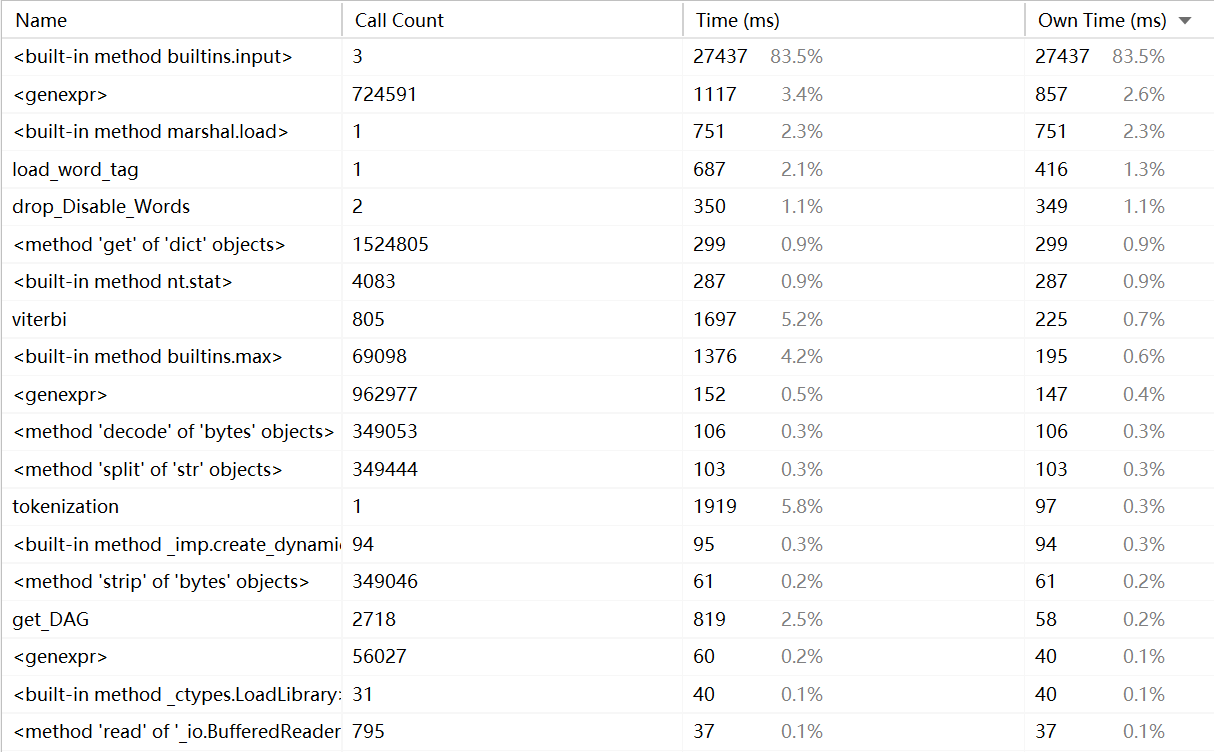
计算模块接口部分的性能改进:
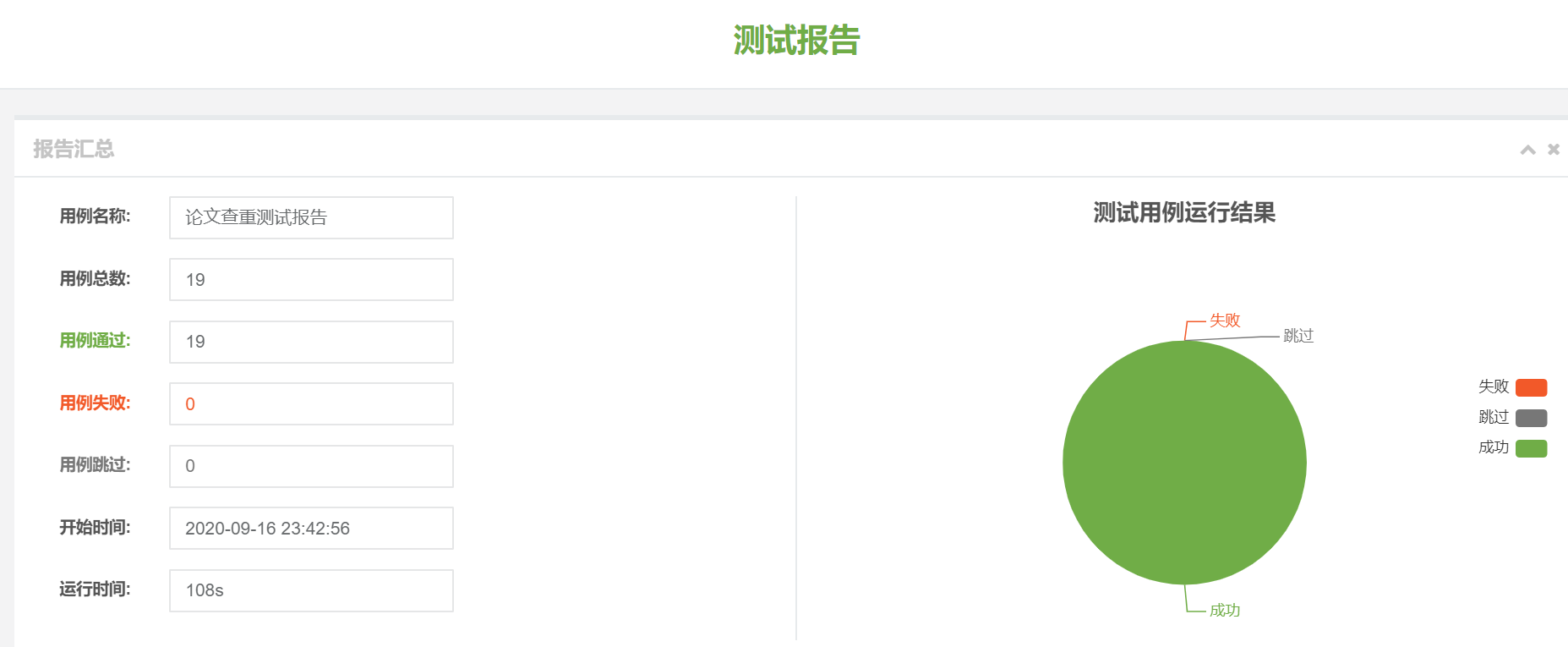
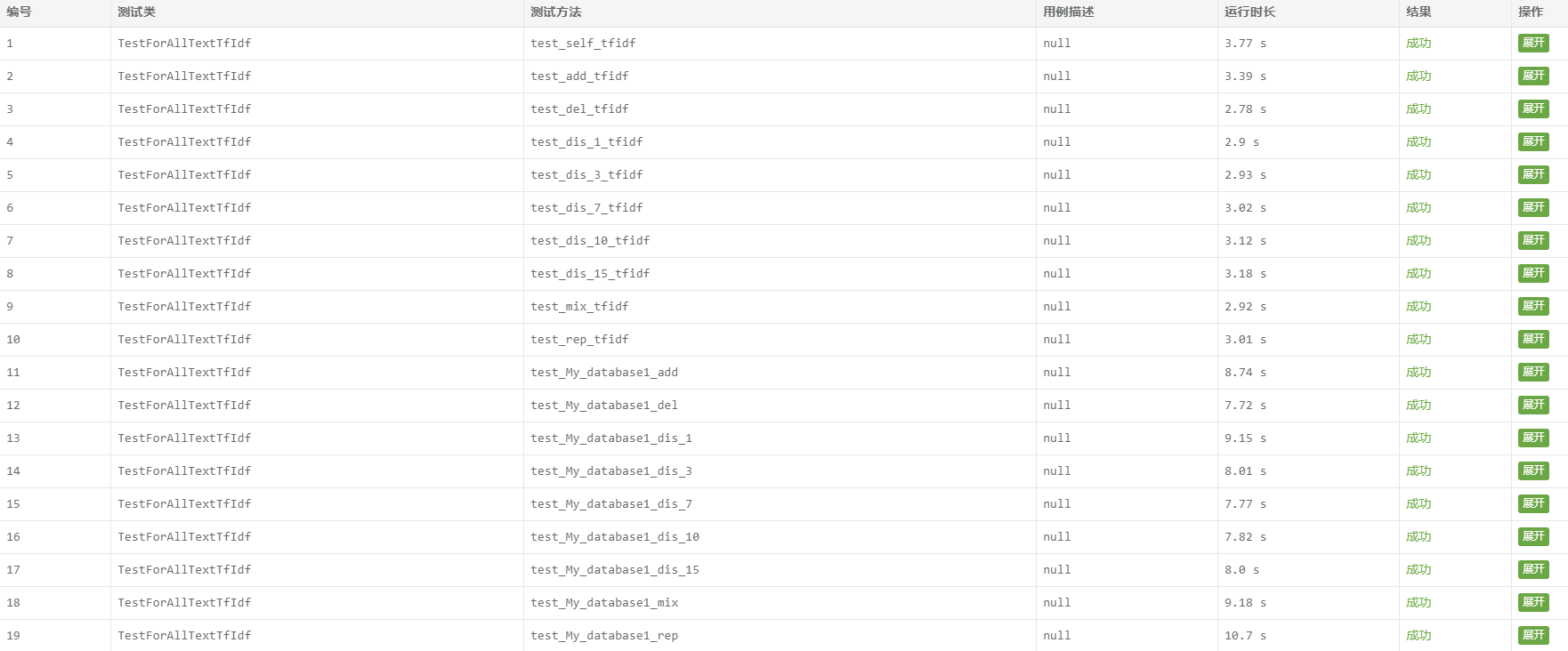
计算模块部分单元测试展示:
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |实际耗时(分钟)|
| ---- | ---- | ---- | ---- | ---- |
| Planning | 计划 | 180 | 200 |
|· Estimate| · 估计这个任务需要多少时间| 2000 | 2400 |
|Development|开发| 2000 | 1800 |
|· Analysis|· 需求分析 (包括学习新技术)| 200 | 480 |
|· Design Spec|· 生成设计文档| 120 | 120 |
|· Design Review|· 设计复审| 100 | 80 |
|· Coding Standard|· 代码规范 (为目前的开发制定合适的规范)| 60 | 20 |
|· Design|· 具体设计| 200 | 240 |
|· Coding|· 具体编码| 1000 | 880 |
|· Code Review|· 代码复审| 100 | 120 |
|· Test|· 测试(自我测试,修改代码,提交修改)| 200 | 420 |
|Reporting|报告| 100 | 240 |
|· Test Repor|· 测试报告| 100 | 480 |
|· Size Measurement|· 计算工作量| 60 | 30 |
|· Postmortem & Process Improvement Plan|· 事后总结, 并提出过程改进计划| 60 | 90 |
| |· 合计| 2480 | 3400 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号