多模态识别
多模态识别的本质 不是“先把字读出来”,
而是:
先把图像分块 → 映射成向量 → 与语言/语义空间对齐 → 判断“这张图在表达什么” 它的能力边界有限 因为它根本不是在“读字”
多模态识别 =
模型不是“先读字”,
而是“一边看图,一边理解这图里在说什么”。
它做的不是 OCR → 文本,
而是 图像 ↔ 语言 ↔ 语义 的联合推理。
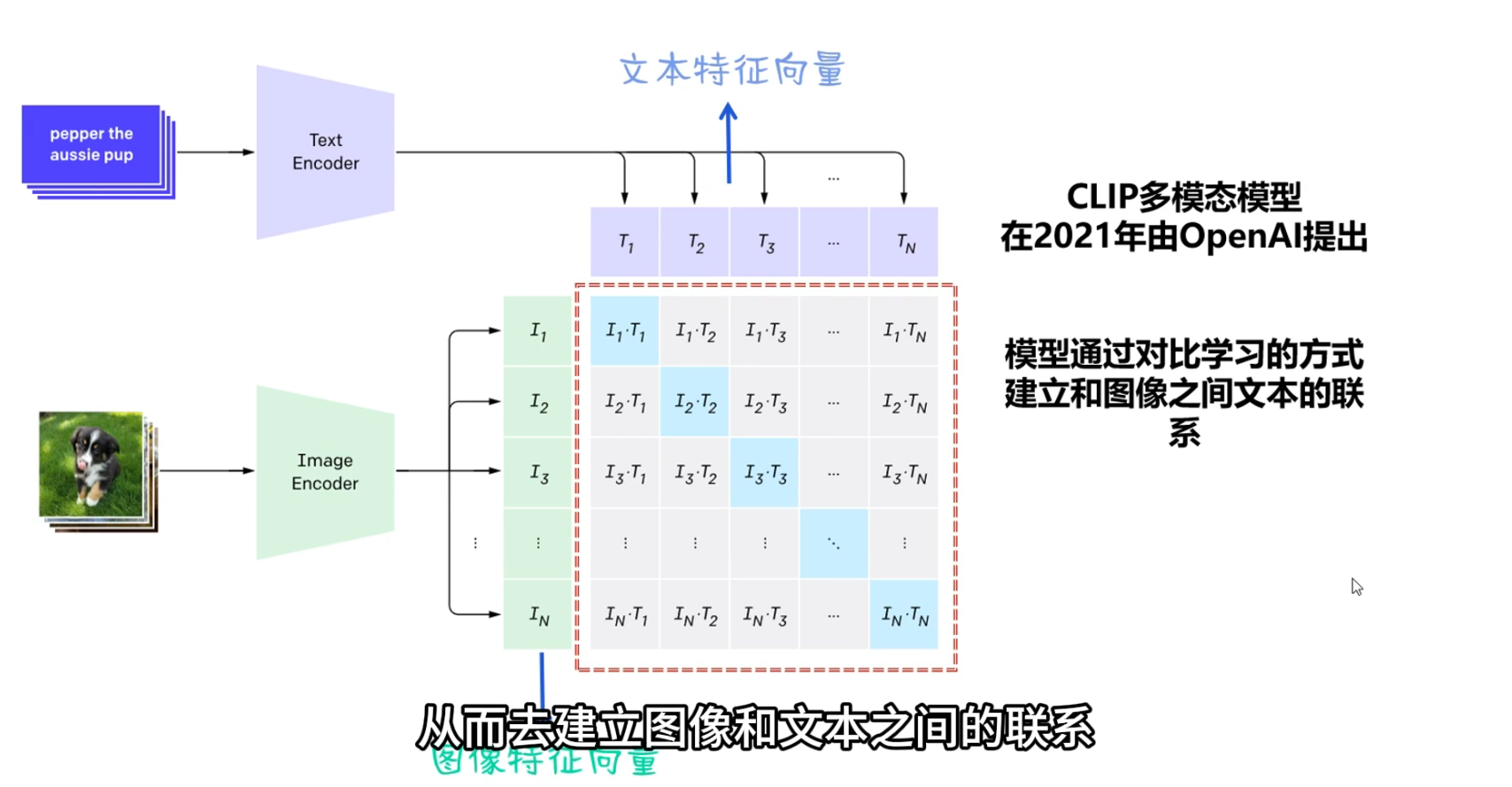
“哪一维是耳朵” “哪一维是鼻子”本身就是人类的抽象
模型里的真实特征是高维、分布式、不可命名的
“耳朵”只是人类对某些激活模式的事后解释
✅ 微调训练本质上只能通过“参数约束”影响模型
✅ 模型输出的语义结果,是模型内部自动形成的高维向量变换
✅ 人类无法直接指定这些高维向量的语义,只能间接塑形
大模型的不可解释性不是工程缺陷,而是分布式高维表示的必然结果;
稀疏电路研究不是让模型“变可解释”,而是让我们在局部、结构层面理解其工作机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号