NEMU_PA1: 开天辟地的篇章: 最简单的计算机

请注意你的学术诚信!
本博客只提供个人思路的参考和一些想法, 并非能够抄袭的答案
1.本人水平有限,实现的PA可能有可怕的bug
2.本人思路可能有误,需要各位自行判别
C语言中.h的作用 与 如何起作用的?
一个实际问题:我们看到一个.c文件引用了某个.h文件,那么.c文件就可以使用其中定义的变量,宏,数据结构,函数等。
但是在.h文件中函数只有函数声明,他是如何找到实现函数在哪里的呢?
假设我有三个函数:main.c,add.h,add.c
add.c实现了add.h中声明的函数
那么我们在main.c中#include 'add.h'后,我们要使用gcc -o main main.c add.c,在编译链接这个过程,会在add.c中找到add.h中声明函数的实现
RTFSC
配置系统kconfig
我们在PA0中做过如下命令:

然后蹦出个菜单,里面可以选择我们实验要用哪一种ISA进行。
目前我要知道的是通过make menuconfig以及我的选择,会反应到:
-
nemu/include/generated/autoconf.h, 可以被包含到C代码中的宏定义,这些宏的名称都是形如CONFIG_xxx的形式,阅读C代码时使用 -
nemu/include/config/auto.conf, 阅读Makefile时使用可以被包含到Makefile中的变量定义
项目构建和Makefile

在src/filelist下

准备第一个客户程序
parse_args()
这个函数与getopt有点像,我曾经遇到过在CSAPP中
getopt_long 是 C 语言中用于解析命令行参数的函数,它允许程序处理长选项(例如 --help)和短选项(例如 -h)。
以下是 getopt_long 函数的基本用法:
- 包含头文件:
#include <stdio.h>
#include <stdlib.h>
#include <getopt.h>
- 定义长选项数组:
static struct option long_options[] = {
{"help", no_argument, NULL, 'h'},
{"version", no_argument, NULL, 'v'},
{"output", required_argument, NULL, 'o'},
{NULL, 0, NULL, 0}
};
这个数组描述了所有的长选项。每个数组元素都是一个 struct option 结构体,包含了选项的名称、选项类型等信息。数组的最后一个元素是一个全零的结构体,用来表示数组结束。
- 解析命令行参数:
int option;
int option_index = 0;
while ((option = getopt_long(argc, argv, "hvo:", long_options, &option_index)) != -1) {
switch (option) {
case 'h':
printf("Help message\n");
break;
case 'v':
printf("Version message\n");
break;
case 'o':
printf("Output file: %s\n", optarg);
break;
case '?':
// 处理未知选项
break;
default:
// 处理其他情况
break;
}
}
在这个 while 循环中,getopt_long 函数用来解析命令行参数。它的参数依次是命令行参数的个数 argc、命令行参数数组 argv、短选项字符串、长选项数组、以及一个指向整数的指针,用于记录当前选项在长选项数组中的索引。
在 switch 语句中,根据 option 的值来判断用户输入了哪些选项。optarg 变量保存了当前选项的参数值(如果有的话)。
void init_monitor(int argc, char *argv[])
NEMU是一个用来执行客户程序的程序, 但客户程序一开始并不存在于客户计算机中. 我们需要将客户程序读入到客户计算机中, 这件事是monitor来负责的.
在nemu/src/monitor/monitor.c中
void init_monitor(int argc, char *argv[]) {
/* Perform some global initialization. */
/* Parse arguments. */
/*
* 就在nemu/src/monitor/monitor.c中
* 作用为解析参数,为下面的操作初始化一些根据参数的配置
* case 'b': sdb_set_batch_mode(); break;
* case 'p': sscanf(optarg, "%d", &difftest_port); break;
* case 'l': log_file = optarg; break;
* case 'd': diff_so_file = optarg; break;
* case 1: img_file = optarg; return 0;
*/
parse_args(argc, argv);
/* Set random seed. */
init_rand();
/* Open the log file. */
/*
* 将日志写到指定的文件中,没有指定就默认输出到标准输出中
*/
init_log(log_file);
/* Initialize memory. */
/*
* 就是调用memset来初始化我们用数组模拟的内存
* IFDEF(CONFIG_MEM_RANDOM, memset(pmem, rand(), CONFIG_MSIZE));
* Log("physical memory area [" FMT_PADDR ", " FMT_PADDR "]", PMEM_LEFT, PMEM_RIGHT);
* CONFIG_MSIZE为内存大小
*/
init_mem();
/* Initialize devices. */
IFDEF(CONFIG_DEVICE, init_device());
/* Perform ISA dependent initialization. */
/*
* 在nemu/src/isa/riscv32/init.c下
* memcpy(guest_to_host(RESET_VECTOR), img, sizeof(img));
* 其中img为内置镜像,在nemu/src/isa/riscv32/init.c
* static const uint32_t img [] = {
0x00000297, // auipc t0,0
0x00028823, // sb zero,16(t0)
0x0102c503, // lbu a0,16(t0)
0x00100073, // ebreak (used as nemu_trap)
0xdeadbeef, // some data
};
* 这段代码定义了一个名为 img 的静态常量数组,其中包含了一系列32位无符号整数。具体来说,这个数组中的每个元素都是一个32位的机器指令,用于构建一个简单的程序或数据。
* 内存的定义在nemu/include/memory/paddr.h,实现在nemu/src/memory/paddr.c
* 定义:#define PMEM_LEFT ((paddr_t)CONFIG_MBASE)
* #define PMEM_RIGHT ((paddr_t)CONFIG_MBASE + CONFIG_MSIZE - 1)
* #define RESET_VECTOR (PMEM_LEFT + CONFIG_PC_RESET_OFFSET)
* 我们让monitor直接把客户程序读入到一个固定的内存位置RESET_VECTOR
* 实现:static uint8_t pmem[CONFIG_MSIZE] PG_ALIGN = {};
* PG_ALIGN用来对齐的
* uint8_t* guest_to_host(paddr_t paddr) { return pmem + paddr - CONFIG_MBASE; }
* 将来CPU访问内存时, 我们会将CPU将要访问的内存地址映射到pmem中的相应偏移位置, 这是通过nemu/src/memory/paddr.c中的guest_to_host()函数实现的
****************************************************
* restart();
* restart()在 nemu/src/isa/riscv32/init.c
* 就简单地设置了PC cpu.pc = RESET_VECTOR;
* 初始化了寄存器 cpu.gpr[0] = 0;
*/
init_isa();
/* Load the image to memory. This will overwrite the built-in image.
* 在nemu/src/monitor/monitor.c下
* 如果我们有镜像文件,那么 int ret = fread(guest_to_host(RESET_VECTOR), size, 1, fp);
* 将一个有意义的客户程序从镜像文件读入到内存, 覆盖刚才的内置客户程序. 这个镜像文件是运行NEMU的一个可选参数, 在运行NEMU的命令中指定. 如果运行NEMU的时候没有给出这个参数, NEMU将会运行内置客户程序.
*/
long img_size = load_img();
...
}
然后很简单,只要将nemu/src/monitor/monitor.c中welcome函数中的assert(0);注释掉就行了
我本来是想要
git add .git commit的,没想到我make run运行编译了nemu都会帮我自动保存
运行第一个客户程序
nemu/src/nemu-main.c int main()调用engine_start();
nemu/src/engine/interpreter/init.c engine_start();调用sdb_mainloop();
nemu/src/monitor/sdb/sdb.c sdb_mainloop()通过for (char *str; (str = rl_gets()) != NULL; )
其中rl_gets()核心调用函数为line_read = readline("(nemu) ");
只要我们不输入ctrl+D表示自己输入完了readline返回NULL,或者使用ctrl+z,ctrl+c强制终止,或者使用其内置命令q直接调用return
我们就一直会在其for (char *str; (str = rl_gets()) != NULL; )循环中
我们输入c,会执行nemu/src/monitor/sdb/sdb.c cmd_c,其中调用nemu/src/cpu/cpu-exec.c cpu_exec
nemu/src/cpu/cpu-exec.c cpu_exec(n)中会执行计时以及最主要的execute(n);

究竟要执行多久?

nemu/src/cpu/cpu-exec.c execute
static void execute(uint64_t n) {
Decode s;
for (;n > 0; n --) {
exec_once(&s, cpu.pc);
g_nr_guest_inst ++;
trace_and_difftest(&s, cpu.pc);
if (nemu_state.state != NEMU_RUNNING) break;
IFDEF(CONFIG_DEVICE, device_update());
}
}
传入参数是-1,但是我们是以无符号64位整数来解释-1,又因为-1的二进制为64个1,即其表示无符号64位整数的最大数
在我们第一次运行的时候,即执行内置镜像文件时,运行了4次,然后导致nemu_state.state != NEMU_RUNNING从而break出去了
解析rl_gets函数
代码如下:其是一个用于从标准输入流(stdin)中读取用户输入的函数。它使用了名为 readline 的库,该库提供了更多灵活性来读取用户输入,并允许历史记录功能。
-
static char *line_read = NULL;:定义了一个静态的字符指针line_read,用于存储用户输入的字符串。静态变量的作用域限定在函数内部,但其生存期跨越了函数调用,因此在每次调用函数时,line_read的值都会被保留。 -
if (line_read) { ... }:如果line_read不为空(即已经包含之前的用户输入),则释放先前分配的内存。 -
line_read = readline("(nemu) ");:调用readline函数来读取用户输入的一行。在这里,"(nemu) "是一个提示符,显示在用户输入之前。readline函数会等待用户输入,并返回用户输入的字符串。 -
if (line_read && *line_read) { ... }:如果成功读取了用户输入,并且用户输入的字符串不为空,则将该输入添加到历史记录中。 -
最后,函数返回用户输入的字符串。
在nemu上使用gdb
要想在nemu上使用gdb,直接键入gdb然后咋办?
再键入b main?没有用,找不到main!

这个时候应该反应过来了,我们再menuconfig的设置会反应到nemu/include/config/auto.conf,然后会影响Makefile!

添加上了CONFIG_CC_DEBUG
去看看nemu/Makefile吧
看了一通,根本没看懂!不要说和gdb有关的了,与run有关的都没有!我make run是咋运行起来的?
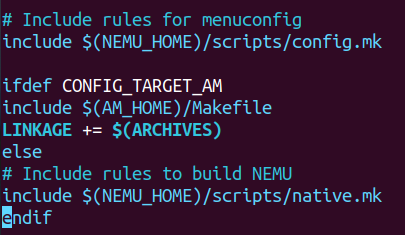
噢!他还include了,而且通过查看nemu/include/config/auto.conf发现CONFIG_TARGET_AM没有被定义!
所以我们应该到$(NEMU_HOME)/scripts/native.mk 看看
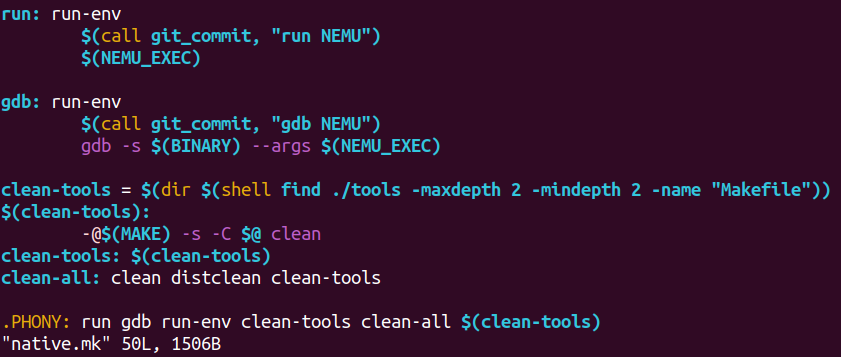
好起来了,现在连如何用gdb调试都知道了,man gdb!
优美地退出
使用make gdb,b main
通过直接键入q,发现会在nemu/src/monitor/sdb/sdb.c sdb_mainloop()中直接调用其内置命令
static int cmd_q(char *args) {
return -1;
}
然后在main的return is_exit_status_bad();

可以知道我们nemu退出要不就是通过运行命令,然后命令运行完了到达nemu_state.state == NEMU_END && nemu_state.halt_ret == 0,然后按下q退出
要不就是直接使用内置命令q让nemu_state.state == NEMU_QUIT
其余都是非正常退出
所以问题出在static int cmd_q(char *args)这个函数直接return -1,而没有给nemu_state.state == NEMU_QUIT
所以改动如下:
static int cmd_q(char *args) {
nemu_state.state = NEMU_QUIT;
return -1;
}
基础设施: 简易调试器 有代码的地方, 就有基础设施
我发现我们这次实验要实现的代码都在nemu/src/monitor/sdb/sdb.c,而sdb不就是Simple debugger的缩写吗?
单步执行
直接调用在cmd_c函数中使用过的cpu_exec即可
static int cmd_si(char *args){
/* extract the first argument */
char *arg = strtok(NULL, " ");
/* Number of single-step execution instructions */
int i;
if (arg == NULL) {
/* no argument given */
i = 1;
}
else {
sscanf (arg, "%d", &i);
}
cpu_exec(i);
return 0;
}
打印寄存器
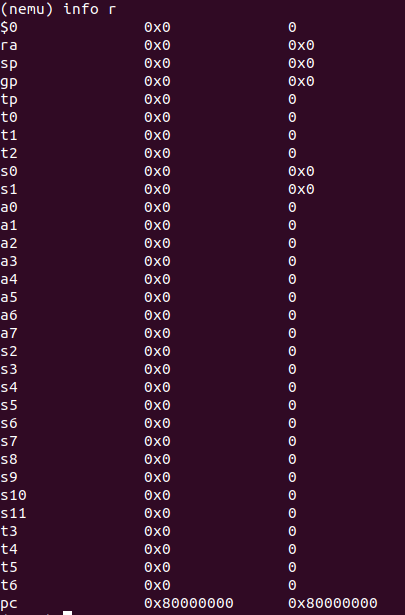
gdb中info r的输出
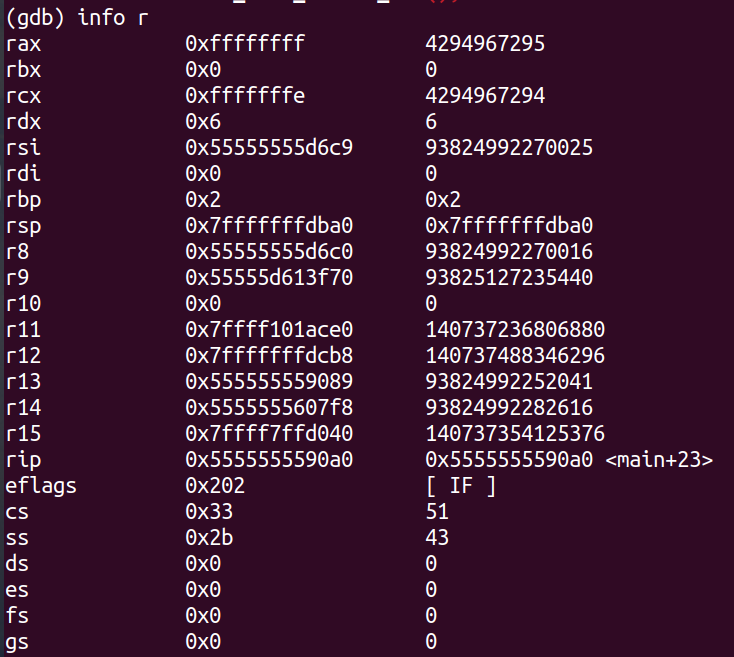
其中我们可以发现最右边一列的数据较为特殊,有些是中间一列十六进制数的十进制,而有些与中间列一致,有些则带有说明含义。其中
rbp,rsp,rip的最右列是十六进制的
其中rbp 是基址指针寄存器(Base Pointer Register)的名称。它是通用寄存器之一,用于在函数调用过程中存储当前函数的栈帧基址。在函数执行过程中,rbp 寄存器通常指向当前函数的栈帧底部。
可以发现最右边是十六进制的寄存器都保存的是地址,而其他除了标志寄存器eflag特殊外,既可以保存地址,也可以保存数据
rip中<...>表示当前pc中记录的指令的位置,以函数+偏移量的方式表现了出来
我们在nemu/src/isa/riscv32/init.c restart()中对寄存器进行过初始化操作
static void restart() {
/* Set the initial program counter. */
cpu.pc = RESET_VECTOR;
/* The zero register is always 0. */
cpu.gpr[0] = 0;
}
我们得看看cpu这个变量是如何定义的
在nemu/src/cpu/cpu-exec.c中有定义:
CPU_state cpu = {};
我们继续看看CPU_state这个属性
在nemu/include/isa.h中有定义:
// The macro `__GUEST_ISA__` is defined in $(CFLAGS).
// It will be expanded as "x86" or "mips32" ...
typedef concat(__GUEST_ISA__, _CPU_state) CPU_state;
我们继续深究看看这个CPU_state中到底是什么
在nemu/src/isa/riscv32/include/isa-def.h中有定义:
typedef struct {
word_t gpr[MUXDEF(CONFIG_RVE, 16, 32)];
vaddr_t pc;
} MUXDEF(CONFIG_RV64, riscv64_CPU_state, riscv32_CPU_state);
我们是riscv32_CPU_state,所以进行宏展开后应该是
typedef struct {
word_t gpr[32];
vaddr_t pc;
}riscv32_CPU_state;
为啥这里命名为gpr?可能是“General Purpose Register”(通用寄存器)的缩写
这里word_t gpr[32];正好与nemu/src/isa/riscv32/reg.c中32个寄存器相对应
const char *regs[] = {
"$0", "ra", "sp", "gp", "tp", "t0", "t1", "t2",
"s0", "s1", "a0", "a1", "a2", "a3", "a4", "a5",
"a6", "a7", "s2", "s3", "s4", "s5", "s6", "s7",
"s8", "s9", "s10", "s11", "t3", "t4", "t5", "t6"
};
这个列表中的寄存器名称是 RISC-V 32位指令集架构中常见的寄存器,以下是它们的含义:
-
"$0"(zero): 这是一个特殊的零寄存器,它的值始终为零。在一些指令中,它被用作立即数为零的默认目标,也可以用作函数的返回值为零的标志。
-
"ra": 返回地址寄存器。在函数调用时,用来存储函数返回地址。
-
"sp": 堆栈指针寄存器。用来指向当前的堆栈顶部。
-
"gp": 全局指针寄存器。用来指向全局数据区的起始地址。
-
"tp": 线程指针寄存器。在多线程环境中,用来存储当前线程的指针。
-
"t0", "t1", "t2": 临时寄存器。用于存储临时数据。
-
"s0", "s1": 基址寄存器或者帧指针寄存器。用于存储函数调用的基址或者帧指针。
-
"a0", "a1", "a2", "a3", "a4", "a5", "a6", "a7": 参数寄存器。用于传递函数参数。
-
"s2"-"s11": 保存寄存器。用于存储函数调用中需要保存的寄存器。
-
"t3", "t4", "t5", "t6": 临时寄存器。用于存储临时数据。
根据上述我们对gdb中寄存器的分析,可以知道
ra,sp,gp,s0,s1最右边应该打印出与中间一样的十六进制数,而其他的最右边应该打印出中间十六进制数的十进制数
rip没有定义在regs[]中,而是单独放在riscv32_CPU_state这个数据结构中,命名为pc
噢!还有很重要的一点是,十进制是无符号的十进制,所以我们输出时不能使用%d,而是%u
# nemu/src/isa/riscv32/reg.c
void isa_reg_display() {
int i;
for (i = 0; i < (sizeof(regs) / sizeof(char *)); i++){
if ((i == 1) || (i == 2) || (i == 3) || (i == 8) || (i == 9)){
printf("%-10s\t0x%-10x\t0x%x\n", regs[i], cpu.gpr[i], cpu.gpr[i]);
} else {
printf("%-10s\t0x%-10x\t%u\n", regs[i], cpu.gpr[i], cpu.gpr[i]);
}
}
printf("%-10s\t0x%-10x\t0x%x\n", "pc", cpu.pc, cpu.pc);
}
左对齐(Left Alignment): 使用
-符号指定。例如,%-10s表示左对齐并且字段宽度为 10 个字符。
目前不知道pc中<...>咋实现的...
扫描内存
遗留...
我想要完成表达式求值后,再完成这个函数
好!我来实现了
首先看看要求和gdb中的输出格式为:


如何访问客户计算机的内存数据?
x86的物理内存是从0开始编址的, 但对于一些ISA来说却不是这样, 例如mips32和riscv32的物理地址均从0x80000000开始.
因此对于mips32和riscv32, 其CONFIG_MBASE将会被定义成0x80000000

我们的pmem数组定义在nemu/src/memory/paddr.c, 是我们NEMU的内存,我们肯定是数组下标肯定是从0~CONFIG_MSIZE。
static uint8_t pmem[CONFIG_MSIZE] PG_ALIGN = {};
但是根据上面的说法,我们可以知道每一次我们要访问内存时,内存地址addr都是0x80000000+paddr。
所以我们要让其访问到pmem[addr-0x80000000],这个工作是nemu/src/memory/paddr.c uint8_t* guest_to_host(paddr_t paddr) { return pmem + paddr - CONFIG_MBASE; }做的
同时框架代码还封装了错误简称的访存函数:
//nemu/src/memory/paddr.c
static word_t pmem_read(paddr_t addr, int len) {
word_t ret = host_read(guest_to_host(addr), len);
return ret;
}
static void pmem_write(paddr_t addr, int len, word_t data) {
host_write(guest_to_host(addr), len, data);
}
word_t paddr_read(paddr_t addr, int len) {
if (likely(in_pmem(addr))) return pmem_read(addr, len);
IFDEF(CONFIG_DEVICE, return mmio_read(addr, len));
out_of_bound(addr);
return 0;
}
void paddr_write(paddr_t addr, int len, word_t data) {
if (likely(in_pmem(addr))) { pmem_write(addr, len, data); return; }
IFDEF(CONFIG_DEVICE, mmio_write(addr, len, data); return);
out_of_bound(addr);
}
我们可以通过打印0x0x80000000这个内存地址进行验证,因为在nemu/src/isa/loongarch32r/init.c将默认镜像文件加载进了pmem
// this is not consistent with uint8_t
// but it is ok since we do not access the array directly
static const uint32_t img [] = {
0x00000297, // auipc t0,0
0x00028823, // sb zero,16(t0)
0x0102c503, // lbu a0,16(t0)
0x00100073, // ebreak (used as nemu_trap)
0xdeadbeef, // some data
};
void init_isa() {
/* Load built-in image. */
memcpy(guest_to_host(RESET_VECTOR), img, sizeof(img));
/* Initialize this virtual computer system. */
restart();
}
同时还有:
#define PMEM_LEFT ((paddr_t)CONFIG_MBASE)
#define RESET_VECTOR (PMEM_LEFT + CONFIG_PC_RESET_OFFSET)
#define CONFIG_PC_RESET_OFFSET 0x0
#define CONFIG_MBASE 0x80000000
需要注意我们的内存是按照字节为单位进行编址的!
gdb打印的内容:
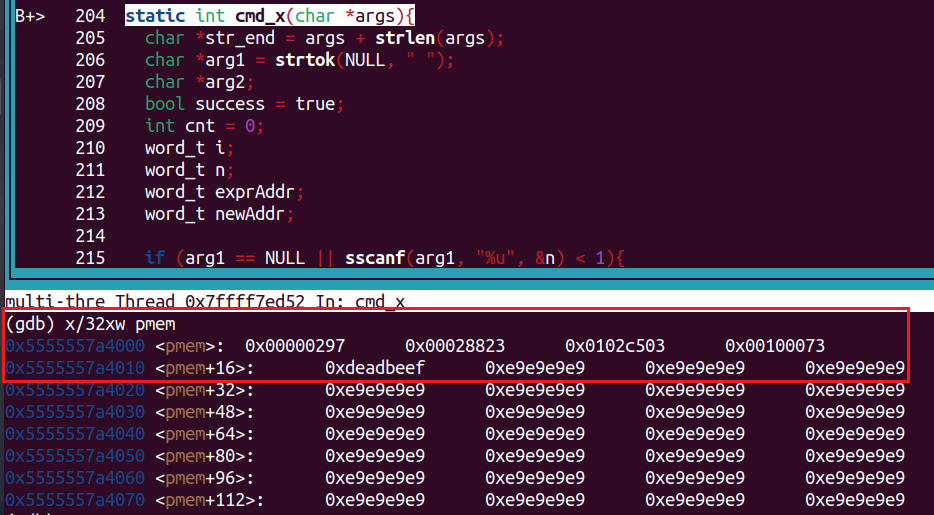
我实现cmd_x打印的内容:

可以看到,前面5个4字节是一样的,后面的内容都是每次运行随机初始化的,不一样很正常

表达式求值
如何用正则表达式提取出表达式每一个token?
在 C 语言中,正则表达式通常通过 PCRE(Perl Compatible Regular Expressions)库或 POSIX 正则表达式库来实现。这些库提供了一组函数,允许在 C 语言中使用正则表达式进行文本匹配和处理。
使用正则表达式的一般步骤如下:
-
包含头文件: 首先,你需要包含适当的头文件,例如
#include <regex.h>(POSIX 正则表达式库)或#include <pcre.h>(PCRE 库)。 -
编译正则表达式: 如果你使用 POSIX 正则表达式库,你需要调用
regcomp函数编译正则表达式字符串。如果你使用 PCRE 库,你需要调用pcre_compile函数编译正则表达式字符串。 -
匹配文本: 一旦正则表达式被编译,你可以使用
regexec(POSIX)或pcre_exec(PCRE)函数来匹配文本。 -
处理匹配结果: 匹配函数将返回匹配结果,你可以根据需要处理这些结果,例如提取匹配的子字符串或确定匹配的位置等。
-
释放资源: 当不再需要使用正则表达式时,记得释放相关资源,如编译正则表达式时分配的内存等。
以下是一个简单的示例,演示了如何在 C 语言中使用 POSIX 正则表达式库进行文本匹配:
#include <stdio.h>
#include <stdlib.h>
#include <regex.h>
int main() {
regex_t regex;
char *pattern = "foo.*";
char *text = "foobar";
// 编译正则表达式
if (regcomp(®ex, pattern, REG_EXTENDED) != 0) {
fprintf(stderr, "Failed to compile regex\n");
exit(1);
}
// 匹配文本
if (regexec(®ex, text, 0, NULL, 0) == 0) {
printf("Text matches regex\n");
} else {
printf("Text does not match regex\n");
}
// 释放资源
regfree(®ex);
return 0;
}
这个示例使用 POSIX 正则表达式库,编译了一个简单的正则表达式 foo.*,然后匹配了字符串 "foobar"。
当使用正则表达式进行文本处理时,需要调用一系列函数来编译正则表达式、匹配文本、处理匹配结果等。以下是关于几个常用函数的使用方法和说明:
-
regcomp函数:- 功能:编译正则表达式。
- 原型:
int regcomp(regex_t *preg, const char *pattern, int cflags); - 参数:
preg:指向regex_t结构的指针,用于存储编译后的正则表达式。pattern:正则表达式的字符串表示。cflags:编译标志,可以是REG_EXTENDED、REG_ICASE等,用于指定编译选项。
- 返回值:成功返回0,失败返回一个非零值。
- 示例:
regex_t regex; char *pattern = "foo.*"; if (regcomp(®ex, pattern, REG_EXTENDED) != 0) { // 处理编译失败情况 }
-
regexec函数:- 功能:执行正则表达式匹配。
- 原型:
int regexec(const regex_t *preg, const char *string, size_t nmatch, regmatch_t pmatch[], int eflags); - 参数:
preg:指向已编译的正则表达式的指针。string:要匹配的字符串。nmatch:用于存储匹配结果的regmatch_t结构数组的大小。pmatch:存储匹配结果的数组。eflags:执行标志,一般设为0。
- 返回值:成功返回0,失败返回一个非零值。
- 示例:
regex_t regex; regmatch_t pmatch[1]; char *text = "foobar"; if (regexec(®ex, text, 1, pmatch, 0) == 0) { // 处理匹配成功情况 }
-
regfree函数:- 功能:释放由
regcomp分配的内存。 - 原型:
void regfree(regex_t *preg); - 参数:
preg:指向已编译的正则表达式的指针。
- 示例:
regex_t regex; // 编译正则表达式并匹配 // ... // 释放资源 regfree(®ex);
- 功能:释放由
然后我们运用上述库,对一个表达式,我们用变量position记录当前要识别token的位置,然后用从position开始,用如下正则表达式规则去匹配,如果匹配成功且匹配到的字符串开始位置与position一致说明成功!
然后我们让position+=strlen(匹配到的字符串),然后开始下一次匹配。
重复如此,可以得到全部我们记录的正则表达式规则所表示的token,我们用一个token数组保存除了空格外的token
enum {
TK_NOTYPE = 256, TK_EQ, TK_NUMBER, TK_NEGATIVE
/* TODO: Add more token types */
};
static struct rule {
const char *regex;
int token_type;
} rules[] = {
/* TODO: Add more rules.
* Pay attention to the precedence level of different rules.
*/
{" +", TK_NOTYPE}, // spaces
{"\\+", '+'}, // plus
{"==", TK_EQ}, // equal
{"\\-", '-'}, // sub
{"\\(", '('}, // left parenthesis
{"\\)", ')'}, // right parenthesis
{"\\*", '*'}, // multiply
{"/", '/'}, // division
{"(0u?|[1-9][0-9]*u?)", TK_NUMBER}, // decimal integer
};
其中regex是例子中的pattern,token_type是为了接下来递归求解表达式用的。
# token数组
typedef struct token {
int type;
char str[32];
} Token;
static Token tokens[32] __attribute__((used)) = {};
static int nr_token __attribute__((used)) = 0;

同时tokens数组也是有限的,当token过多,tokens数组也没空间了. 咋办?


注意在
nemu/include/debug.h中提供给我们一些很好用的函数Log,Assert...
活用他们
static bool make_token(char *e) {
int position = 0;
int i;
regmatch_t pmatch;
nr_token = 0;
while (e[position] != '\0') {
/* Try all rules one by one. */
for (i = 0; i < NR_REGEX; i ++) {
if (regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) {
char *substr_start = e + position;
int substr_len = pmatch.rm_eo;
Log("match rules[%d] = \"%s\" at position %d with len %d: %.*s",
i, rules[i].regex, position, substr_len, substr_len, substr_start);
position += substr_len;
/* TODO: Now a new token is recognized with rules[i]. Add codes
* to record the token in the array `tokens'. For certain types
* of tokens, some extra actions should be performed.
*/
switch (rules[i].token_type) {
case TK_NOTYPE:
break;
case TK_NUMBER:
//Assert(nr_token < 32, "The tokens array has insufficient storage space.");
Assert(nr_token < 65536, "The tokens array has insufficient storage space.");
Assert(substr_len < 32, "token is too long");
strncpy(tokens[nr_token].str, substr_start, substr_len);
tokens[nr_token].type = rules[i].token_type;
tokens[nr_token].str[substr_len] = '\0';
nr_token++;
break;
default:
//Assert(nr_token < 32, "The tokens array has insufficient storage space.");
Assert(nr_token < 65536, "The tokens array has insufficient storage space.");
tokens[nr_token].type = rules[i].token_type;
nr_token++;
break;
}
break;
}
}
if (i == NR_REGEX) {
printf("no match at position %d\n%s\n%*.s^\n", position, e, position, "");
return false;
}
}
return true;
}
%.*s在printf中的使用方法
%.*s 是 C 语言中格式化输出字符串的方式之一,通常用于以指定的精度打印字符串。
这个格式字符串中的 %.*s 包含两个格式控制部分:
%.*:指定了一个精度(precision)参数,该参数由后面的变量提供。这个精度参数告诉printf函数要打印的字符数。s:表示要打印的变量是一个字符串。
这种格式化输出的方式在打印不定长度的字符串时很有用,因为它允许指定要打印的字符数,而不是打印整个字符串。通常情况下,%.*s 用于打印带有精确长度的字符串。
例如,下面的代码演示了如何使用 %.*s 打印一个字符串,并指定打印的字符数:
#include <stdio.h>
int main() {
char *str = "Hello, world!";
int precision = 5; // 指定要打印的字符数
printf("%.*s\n", precision, str); // 打印字符串的前 5 个字符
return 0;
}
这段代码将打印字符串 "Hello",因为指定了精度参数为 5。
strncpy的使用方法
strncpy 函数用于将指定长度的字符串从源字符串复制到目标字符串。它是一个更安全的字符串复制函数,可以指定要复制的字符数目,以避免缓冲区溢出的问题。以下是 strncpy 函数的使用方法:
#include <string.h>
char *strncpy(char *dest, const char *src, size_t n);
dest:目标字符串的指针,指向要复制到的目标位置。src:源字符串的指针,指向要复制的源字符串。n:要复制的最大字符数目。
strncpy 函数会将 src 指向的字符串的前 n 个字符复制到 dest 指向的位置。如果 src 的长度小于 n,则剩余的位置会用空字符 \0 填充;如果 src 的长度大于等于 n,则只会复制 n 个字符。目标字符串 dest 的长度至少应该为 n+1,以确保复制的字符串后面有足够的空间来存放空字符 \0。
示例:
#include <stdio.h>
#include <string.h>
int main() {
char dest[20]; // 目标字符串
const char *src = "Hello, world!"; // 源字符串
strncpy(dest, src, sizeof(dest) - 1); // 将源字符串的前 sizeof(dest) - 1 个字符复制到目标字符串
dest[sizeof(dest) - 1] = '\0'; // 手动添加字符串结尾的空字符
printf("Copied string: %s\n", dest); // 打印复制后的字符串
return 0;
}
递归求值

-
负号前面一定是token数组的开始或者其前一个token一定是除
)的符号,而减号其前一个token一定是数值或者),且不可能在tokens数组的开始部分 -
我打算在make_tokens()函数调用之后,利用上述性质标记出负号出来,然后再eval()函数中对负号进行特殊处理
-
负号在分裂时,要特殊判断下。我打算遇到负号时特判,让原来的 -exp 执行 -1 * exp
-
设置负号的优先级为最高(这是根据我的实现特别设置的,虽然和正常的优先级不太一样),但是这能够保证我的表达式在计算如
23+-1时,会分裂成'23' + '-1',而不是'23+' '-1'
!!!超级注意点
在check_parentheses()函数中, (4 + 3)) * ((2 - 1)和(4 + 3) * (2 - 1)这两个表达式虽然都返回false, 因为前一种情况是表达式不合法, 是没有办法成功进行求值的;
而后一种情况是一个合法的表达式, 是可以成功求值的, 只不过它的形式不属于BNF中的"("")", 需要使用主运算符的方式进行处理.
因此你还需要想办法把它们区别开来.
开始我是没太注意的,直到我遇到了一个死亡案例:((9490u)*(7u)),想一想,如果不考虑上述提示,你的代码会如何运行?
我当时写的代码会对9490u)*(7u进行求值!!!
即我们的check_parentheses()函数还需要判断当去除最左右的'(',')'后,表达式的括号是否还匹配?即是否是个最基础的正确的表达式?
咋办?栈!
出现在一对括号中的token不是主运算符. 注意到这里不会出现有括号包围整个表达式的情况, 因为这种情况已经在check_parentheses()相应的if块中被处理了.
当有多个运算符的优先级都是最低时, 根据结合性, 最后被结合的运算符才是主运算符. 一个例子是1 + 2 + 3, 它的主运算符应该是右边的+.
不知道有没有和我一样倒霉的孩子忽视了上述两点,如果你还没有反应过来,想一想这个案例3/2/5,如果你遇到了除零错误,那么恭喜你,你的代码要重新写一边了
在3/2/5中,最右边的/为主运算符,那么执行顺序是:先3/2 再/5, 遇到除零错误是先3,再/(2/5)了
咋办?栈!

咋办?我个人的做法是传递个bool指针success给eval函数,用这个指针告知上层函数是否成功
word_t eval(int p, int q, bool *success);
void markNegative() {
int i;
for (i = 0 ; i < nr_token; i++){
if (tokens[i].type == TK_NUMBER) continue;
if (tokens[i].type == (int)('-') && (i == 0 ||
(tokens[i - 1].type != TK_NUMBER && tokens[i - 1].type != (int)(')')))){
tokens[i].type = TK_NEGATIVE;
}
}
}
word_t expr(char *e, bool *success) {
bool evalSuccess;
word_t exprAns;
if (!make_token(e)) {
*success = false;
return 0;
}
/* TODO: Insert codes to evaluate the expression. */
//TODO();
markNegative();
evalSuccess = true;
exprAns = eval(0, nr_token - 1, &evalSuccess);
*success = evalSuccess;
if (evalSuccess){
return exprAns;
}
return 0;
}
/*检查表达式的左右括号是否匹配*/
bool check_expr_parentheses(int p, int q){
int i;
int stack_top = -1;
bool flag = true;
for (i = p; i <= q ; i++){
if (tokens[i].type == (int)('(')){
stack_top++;
} else if (tokens[i].type == (int)(')')){
if (stack_top >= 0){
stack_top--;
} else {
flag = false;
break;
}
}
}
if (stack_top < 0 && flag == true){
flag = true;
} else {
flag = false;
}
return flag;
}
bool check_parentheses(int p, int q){
/*判断表达式是否被一对匹配的括号包围着*/
if (tokens[p].type == (int)('(') && tokens[q].type == (int)(')')){
return check_expr_parentheses(p + 1, q - 1);
}
return false;
}
int priority(int op_type){
switch (op_type)
{
case '(':
case ')':
return 0;
break;
case '+':
case '-':
return 1;
break;
case '*':
case '/':
return 2;
break;
case TK_NEGATIVE:
return 3;
break;
default:
Assert(0, "No corresponding operator found");
}
}
struct stack_node{
int idx;
int type;
};
word_t eval(int p, int q, bool *success){
// printf("expr:");
// for (int i = p; i <= q; i++){
// if (tokens[i].type == TK_NUMBER){
// printf("%s", tokens[i].str);
// } else {
// printf("%c", (char)tokens[i].type);
// }
// }
// printf("\n");
word_t number;
if (p > q){
*success = false;
return 0;
} else if (p == q){
if (sscanf(tokens[p].str,"%u", &number) < 1){
*success = false;
return 0;
}
return number;
} else if (check_parentheses(p, q) == true){
return eval(p + 1, q - 1, success);
} else {
if (check_expr_parentheses(p, q) == false){
*success = false;
return 0;
}
int i;
int top = -1;
int op_type;
word_t val1;
word_t val2;
/*这个stack数组不能设太大,否则会因为栈溢出导致段错误*/
struct stack_node stack[1024];
/*
* 出现在一对括号中的token不是主运算符. 注意到这里不会出现有括号包围整个表达式的情况, 因为这种情况已经在check_parentheses()相应的if块中被处理了.
* 主运算符的优先级在表达式中是最低的.
* 当有多个运算符的优先级都是最低时, 根据结合性, 最后被结合的运算符才是主运算符
* 一个例子是1 + 2 + 3, 它的主运算符应该是右边的+.
*/
for (i = p; i <= q; i++){
Assert(top < 1024, "stack in eval function over overflow!");
if (tokens[i].type == TK_NUMBER) continue;
if (top < 0){
top++;
stack[top].idx = i;
stack[top].type = tokens[i].type;
continue;
}
if (tokens[i].type == (int)('(')){
top++;
stack[top].idx = i;
stack[top].type = tokens[i].type;
continue;
}
if (tokens[i].type == (int)(')')){
/*出现在一对括号中的token不是主运算符*/
while (top >=0 && stack[top].type != '('){
top--;
}
/*pop (*/
top--;
continue;
}
/*优先级越低越在stack下面,主运算符的优先级在表达式中是最低的.当有多个运算符的优先级都是最低时, 根据结合性, 最后被结合的运算符才是主运算符*/
while (top >= 0 && priority(tokens[i].type) <= priority(stack[top].type) ){
if (tokens[i].type == stack[top].type && stack[top].type == TK_NEGATIVE){
/*负号比较特殊,当负号前面是负号时,主运算符是前面的负号,如--1*/
break;
}
top--;
}
++top;
stack[top].idx = i;
stack[top].type = tokens[i].type;
}
Assert(top < 1024, "stack in eval function over overflow!");
/*If the primary operator cannot be found, the expression is incorrect.*/
if (top < 0){
*success = false;
return 0;
}
if (stack[0].type == TK_NEGATIVE){
val1 = -1;
val2 = eval(stack[0].idx + 1, q, success);
op_type = '*';
} else {
val1 = eval(p, stack[0].idx - 1, success);
val2 = eval(stack[0].idx + 1, q, success);
op_type = stack[0].type;
}
/*Something went wrong in a step of the recursive solution.*/
if (*success != true){
return 0;
}
switch (op_type)
{
case '+':
return val1 + val2;
case '-':
return val1 - val2;
case '*':
return val1 * val2;
case '/':
if (val2 == 0){
*success = false;
return 0;
}
return val1 / val2;
default:
Assert(0, "No corresponding operator found");
}
}
}
如何测试你的代码
表达式生成器实现四问:
-
如何保证表达式进行无符号运算?
要看个人如何实现的expr函数及其相关函数,因为最后我们生成出来了表达式,我们要调用expr函数去识别表达式,并计算
如果我们保证表达式进行无符号运算的方法使得产生的表达式不能被我们的expr函数识别也是徒劳!
我的方法是在gen_num()后加上u,如10u,表示数是一个无符号整数,计算时自然会按照无符号计算。同时在expr函数调用的make_token函数中,我是使用sscanf函数来实现将字符串整数->数值整数的,而sscanf是可以成功识别如10u这样的形式的
测试代码和测试结果如下:char str[] = "20u"; uint32_t strNumber; int cnt = sscanf(str, "%u", &strNumber);
-
如何随机插入空格?
将生成表达式的框架改下:
void gen_rand_expr() { switch (choose(3)) { case 0: gen_space(); gen_num(); gen_space(); break; case 1: gen('('); gen_space(); gen_rand_expr(); gen_space(); gen(')'); break; default: gen_rand_expr(); gen_space(); gen_rand_op(); gen_space(); gen_rand_expr(); break; } } -
如何生成长表达式, 同时不会使buf溢出?
我的做法是传给gen_rand_expr一个层数参数
n,当n达到一定的大小,则强制让gen_rand_expr()函数不再递归,而是直接gen_num -
如何过滤求值过程中有除0行为的表达式?

因为我们不做任何溢出处理,所以我们要尽量避免溢出问题
在有符号运算中,如果运算结果超出了有符号数的表示范围,可能会导致溢出。溢出会导致未定义行为,结果可能是不确定的。如当两个整数相乘,如果使用有符号运算会发生运算出的结果为负数。
但是如果是进行无符号运算,无符号整数运算会天然地给我们进行模运算。这是因为无符号整数的取值范围是 0 到 2^N-1(其中 N 是整数的位数)。当无符号整数发生溢出时,会自动进行模运算,即结果会被截断为可表示的范围内的值。
用以下测试代码:#include <stdint.h> #include <stdio.h> #include <stdlib.h> #include <time.h> #include <assert.h> #include <string.h> int main(int argc, char *argv[]) { char code_buf[]= "#include <stdio.h>\n" "int main() { " " unsigned a = 2;" " unsigned b = 0;" " unsigned ans = a / b;" " printf(\"%u\", ans); " " return 0; " "}"; FILE *fp = fopen("/tmp/.code.c", "w"); assert(fp != NULL); fputs(code_buf, fp); fclose(fp); int ret = system("gcc /tmp/.code.c -o /tmp/.expr"); if (ret != 0) { printf("call system error\n"); return 0; } fp = popen("/tmp/.expr", "r"); assert(fp != NULL); int result = -1; ret = fscanf(fp, "%d", &result); int status = 0; status = pclose(fp); printf("status: %d", status); // 检查子进程的终止状态 if (WIFEXITED(status)) { printf("子进程正常终止,退出状态码:%d\n", WEXITSTATUS(status)); } else if (WIFSIGNALED(status)) { printf("子进程被信号终止,信号编号:%d\n", WTERMSIG(status)); } printf("%u\n", result); return 0; }得到如下结果:

那如果换成" unsigned a = 2;" " unsigned b = 1;" " unsigned ans = a + b;"那么有如下结果

可见,我们可以使用WIFEXITED(status)与WTERMSIG(status)判断是否出现除零操作
特殊案例:
一个逆天的案例为( ( ( 92u ) / 70415u / ( ( ( ( 3967978u * 23387u ) ) / 7u / 0u ) ) ) );
可以试试,如果其作为一个表达式字符串直接如下运算是没有问题的,结果为0,但是编译链接时会warning:division by zero [-Wdiv-by-zero]

但是用eval函数一步一步算出来,就报除零错误...
噢!这种案例还不止一个,试试下面这个:
(((((5197867u)+((224180u)))-((278773u+49794747u+15084767u))/(854u/1888u)*0u*4628547u*((78129140u)))))

然后只有再编译链接的时候会有warning,但是执行起来还是正确的

但是,你是知道的,在我们的表达式运算函数eval中出现了除零那就是死刑
咋办? 一个简单但是很简单的方式是我将全部的warning看做error处理
将C代码中的warning当做错误处理 -Wall -Werrorint ret = system("gcc -o /tmp/.expr -Wall -Werror /tmp/.code.c"); if (ret != 0) continue;
// this should be enough
static char buf[65536] = {};
static char code_buf[65536 + 128] = {}; // a little larger than `buf`
static char *code_format =
"#include <stdio.h>\n"
"int main() { "
" unsigned result = %s; "
" printf(\"%%u\", result); "
" return 0; "
"}";
static int buf_index = 0;
/*Generate a random number less than n*/
static uint32_t choose(uint32_t n){
return (uint32_t)((double)rand() / ((double)RAND_MAX + 1) * n);
}
static void gen(char c){
buf[buf_index++] = c;
buf[buf_index] = '\0';
}
static void gen_num(){
/*
* the number of unsigned max is 4294967295
* so, to simplify, gen_num function will generate a number with bits ranging between 0 and 9;
*/
uint32_t len = choose(10);
if (len == (uint32_t)(0))
len += 1;
if (len == 1){
gen((char)(choose(10) + '0'));
return ;
}
uint32_t firstNum = choose(10);
/*Numbers cannot start with 0*/
if (firstNum == (uint32_t)(0)){
firstNum += 1;
}
gen((char)(firstNum + '0'));
uint32_t i;
for (i = 2; i <= len; i++){
gen((char)(choose(10) + '0'));
}
}
/*Randomly generate 0~10 spaces*/
static void gen_space(){
uint32_t len = choose(11);
uint32_t i;
for (i = 1; i <= len; i++){
gen(' ');
}
}
static void gen_rand_op(){
switch (choose(4))
{
case 0: gen('+'); break;
case 1: gen('-'); break;
case 2: gen('*'); break;
default: gen('/'); break;
}
}
static void gen_rand_expr(uint32_t n) {
uint32_t chooseAns = choose(3);
/*
* Up to ten levels of recursion
* Then let gen_rand_expr force no more recursion
*/
if (n >= 10){
chooseAns = 0;
}
switch (chooseAns)
{
case 0: gen_space(); gen_num(); gen('u'); gen_space(); break;
case 1: gen('('); gen_space(); gen_rand_expr(n + 1); gen_space(); gen(')'); break;
default: gen_rand_expr(n + 1); gen_space(); gen_rand_op(); gen_space(); gen_rand_expr(n + 1); break;
}
}
int main(int argc, char *argv[]) {
int seed = time(0);
srand(seed);
int loop = 1;
if (argc > 1) {
sscanf(argv[1], "%d", &loop);
}
int i;
for (i = 0; i < loop; i ++) {
/*Reset buf_index! This is really important unless you want to spend 2 hours debugging like me.*/
buf_index = 0;
gen_rand_expr(1);
sprintf(code_buf, code_format, buf);
FILE *fp = fopen("/tmp/.code.c", "w");
assert(fp != NULL);
fputs(code_buf, fp);
fclose(fp);
int ret = system("gcc -o /tmp/.expr -Wall -Werror /tmp/.code.c");
if (ret != 0) continue;
fp = popen("/tmp/.expr", "r");
assert(fp != NULL);
int result;
int status;
ret = fscanf(fp, "%d", &result);
status = pclose(fp);
//printf("WIFEXITED(status):%d ----- WEXITSTATUS(status):%d\n", WIFEXITED(status), WEXITSTATUS(status));
if (WIFEXITED(status)){
/*indicates a divide-by-zero operation*/
if (WEXITSTATUS(status) == 136){
continue;
}
}
printf("%u %s\n", result, buf);
}
return 0;
}
源代码细究:
# nemu/tools/gen-expr/gen-expr.c
int main(int argc, char *argv[]) {
int seed = time(0);
srand(seed);
int loop = 1;
if (argc > 1) {
sscanf(argv[1], "%d", &loop);
}
int i;
for (i = 0; i < loop; i ++) {
gen_rand_expr();
/*
* int sprintf(char *str, const char *format, ...);
* sprintf 函数将根据 format 字符串中的格式说明符将数据写入到 str 指向的字符串缓冲区中。
* printf是将根据 format 字符串中的格式说明符将数据写入到标准输出中
*/
sprintf(code_buf, code_format, buf);
FILE *fp = fopen("/tmp/.code.c", "w");
assert(fp != NULL);
fputs(code_buf, fp);
fclose(fp);
int ret = system("gcc /tmp/.code.c -o /tmp/.expr");
if (ret != 0) continue;
/*
* FILE *popen(const char *command, const char *mode);
* popen 函数会创建一个管道,并执行指定的命令。
* 如果 mode 是 "r",则管道连接到子进程的标准输出,允许父进程从管道中读取子进程的输出;
* 如果 mode 是 "w",则管道连接到子进程的标准输入,允许父进程向子进程发送输入。
*/
fp = popen("/tmp/.expr", "r");
assert(fp != NULL);
int result;
ret = fscanf(fp, "%d", &result);
/*
* int pclose(FILE *stream);
* pclose 函数关闭文件流 stream 所关联的管道,并等待与之关联的子进程终止。
* 如果成功关闭管道并获取了子进程的终止状态,pclose 函数会返回子进程的终止状态;
* 如果关闭管道或等待子进程终止失败,则返回 -1。
*/
pclose(fp);
printf("%u %s\n", result, buf);
}
return 0;
}
利用
sprintf(code_buf, code_format, buf);将要执行的源代码写到code_buf缓冲区(数组)中
FILE *fp = fopen("/tmp/.code.c", "w");fputs(code_buf, fp);将code_buf中的源代码写到文件/tmp/.code.c中
int ret = system("gcc /tmp/.code.c -o /tmp/.expr");编译链接这个/tmp/.code.c源代码文件,并生成/tmp/.expr可执行文件
fp = popen("/tmp/.expr", "r");在子进程中运行/tmp/.expr可执行文件;ret = fscanf(fp, "%d", &result);将输出结果从管道中读取保存到result变量中

如何改造NEMU的main函数?
我们知道,在main函数中主要运行了两个函数:init_monitor(argc, argv);,engine_start();
我们肯定是不能让engine_start();执行的,否则会进入到sdb_mainloop();循环中
一定要让init_monitor(argc, argv);执行,因为在这个函数中他会调用init_sdb();,而init_sdb();会调用init_regex();
噢!如果没有执行
init_regex();会发生什么?你会陷入崩溃
你会在regexec得到段错误--Segmentation Fault with complex regex - Regex.h
或者你的正则表达式写的不正确,也会在regexec执行发生段错误
所以检查你的init_regex()和正则表达式的正确性!
#include <common.h>
void init_monitor(int, char *[]);
void am_init_monitor();
void engine_start();
int is_exit_status_bad();
word_t expr(char *e, bool *success);
int main(int argc, char *argv[])
{
/* Initialize the monitor. */
#ifdef CONFIG_TARGET_AM
am_init_monitor();
#else
init_monitor(argc, argv);
#endif
FILE *file;
char line[65536 + 128];
char exprbuf[65536];
uint32_t result;
file = fopen("/home/cilinmengye/ics2023/nemu/tools/gen-expr/build/input", "r");
assert(file != NULL);
while (fgets(line, 65536 + 128, file) != NULL)
{
/*notice i and j need reset before start*/
int i = 0;
int j = 0;
int cnt = sscanf(line, "%u", &result);
assert(cnt == 1);
while (line[i] != ' ')
{
i++;
}
while (line[i] != '\n' && i < 65536)
{
exprbuf[j] = line[i];
j++;
i++;
}
exprbuf[j] = '\0';
bool success = true;
word_t ans = expr(exprbuf, &success);
if (success == false && result - ans != 0)
{
printf("- origin line: %s- success: %d\n- exprbuf: %s\n- result:%u\n- ans: %u\n",
line, success, exprbuf, result, ans);
return 0;
}
}
return 0;
/* Start engine. */
engine_start();
return is_exit_status_bad();
}
测试
cd tools
cd gen-expr
make
cd build
./gen-expr 10000 > input //这个过程如果出现error是正常的,因为表达式生成器很可能会生成出除零的表达式,但是我的上述代码将其过滤了,不必担心
cd $NEMU_HOME
make clean
make run // 没有任何报错!!!成功了!!!
满屏的蓝色匹配字,我就知道我成功了~
调试代码:
/* We use the POSIX regex functions to process regular expressions.
* Type 'man regex' for more information about POSIX regex functions.
*/
#include <regex.h>
#include <stdint.h>
#include <stdbool.h>
#include <stdlib.h>
#include <stdio.h>
#include <assert.h>
#include <string.h>
#define word_t uint32_t
enum {
TK_NOTYPE = 256, TK_EQ, TK_NUMBER, TK_NEGATIVE
/* TODO: Add more token types */
};
static struct rule {
const char *regex;
int token_type;
} rules[] = {
/* TODO: Add more rules.
* Pay attention to the precedence level of different rules.
*/
{" +", TK_NOTYPE}, // spaces
{"\\+", '+'}, // plus
{"==", TK_EQ}, // equal
{"\\-", '-'}, // sub
{"\\(", '('}, // left parenthesis
{"\\)", ')'}, // right parenthesis
{"\\*", '*'}, // multiply
{"/", '/'}, // division
{"(0u?|[1-9][0-9]*u?)", TK_NUMBER}, // decimal integer
};
#define ARRLEN(arr) (int)(sizeof(arr) / sizeof(arr[0]))
#define NR_REGEX ARRLEN(rules)
static regex_t re[NR_REGEX] = {};
/* Rules are used for many times.
* Therefore we compile them only once before any usage.
*/
void init_regex() {
int i;
char error_msg[128];
int ret;
for (i = 0; i < NR_REGEX; i ++) {
ret = regcomp(&re[i], rules[i].regex, REG_EXTENDED);
if (ret != 0) {
regerror(ret, &re[i], error_msg, 128);
printf("regex compilation failed: %s\n%s", error_msg, rules[i].regex);
}
}
}
typedef struct token {
int type;
char str[32];
} Token;
//static Token tokens[32] __attribute__((used)) = {};
static Token tokens[65536] __attribute__((used)) = {};
static int nr_token __attribute__((used)) = 0;
static bool make_token(char *e) {
int position = 0;
int i;
regmatch_t pmatch;
nr_token = 0;
while (e[position] != '\0') {
/* Try all rules one by one. */
for (i = 0; i < NR_REGEX; i ++) {
if (regexec(&re[i], e + position, 1, &pmatch, 0) == 0 && pmatch.rm_so == 0) {
char *substr_start = e + position;
int substr_len = pmatch.rm_eo;
//printf("match rules[%d] = \"%s\" at position %d with len %d: %.*s\n",
// i, rules[i].regex, position, substr_len, substr_len, substr_start);
position += substr_len;
/* TODO: Now a new token is recognized with rules[i]. Add codes
* to record the token in the array `tokens'. For certain types
* of tokens, some extra actions should be performed.
*/
switch (rules[i].token_type) {
case TK_NOTYPE:
break;
case TK_NUMBER:
//Assert(nr_token < 32, "The tokens array has insufficient storage space.");
assert(nr_token < 65536);
assert(substr_len < 32);
strncpy(tokens[nr_token].str, substr_start, substr_len);
tokens[nr_token].type = rules[i].token_type;
tokens[nr_token].str[substr_len] = '\0';
nr_token++;
break;
default:
//Assert(nr_token < 32, "The tokens array has insufficient storage space.");
assert(nr_token < 65536);
tokens[nr_token].type = rules[i].token_type;
nr_token++;
break;
}
break;
}
}
if (i == NR_REGEX) {
printf("no match at position %d\n%s\n%*.s^\n", position, e, position, "");
return false;
}
}
return true;
}
word_t eval(int p, int q, bool *success);
void markNegative() {
int i;
for (i = 0 ; i < nr_token; i++){
if (tokens[i].type == TK_NUMBER) continue;
if (tokens[i].type == (int)('-') && (i == 0 ||
(tokens[i - 1].type != TK_NUMBER && tokens[i - 1].type != (int)(')')))){
tokens[i].type = TK_NEGATIVE;
}
}
}
word_t expr(char *e, bool *success) {
bool evalSuccess;
word_t exprAns;
if (!make_token(e)) {
*success = false;
return 0;
}
printf("tokens:\n");
for (int i = 0; i < nr_token; i++){
if (tokens[i].type == TK_NUMBER){
printf("%s", tokens[i].str);
} else {
printf("%c", (char)tokens[i].type);
}
}
printf("\n");
/* TODO: Insert codes to evaluate the expression. */
//TODO();
markNegative();
evalSuccess = true;
exprAns = eval(0, nr_token - 1, &evalSuccess);
*success = evalSuccess;
if (evalSuccess){
return exprAns;
}
return 0;
}
/*检查表达式的左右括号是否匹配*/
bool check_expr_parentheses(int p, int q){
int i;
int stack_top = -1;
bool flag = true;
for (i = p; i <= q ; i++){
if (tokens[i].type == (int)('(')){
stack_top++;
} else if (tokens[i].type == (int)(')')){
if (stack_top >= 0){
stack_top--;
} else {
flag = false;
break;
}
}
}
if (stack_top < 0 && flag == true){
flag = true;
} else {
flag = false;
}
return flag;
}
bool check_parentheses(int p, int q){
/*判断表达式是否被一对匹配的括号包围着*/
if (tokens[p].type == (int)('(') && tokens[q].type == (int)(')')){
return check_expr_parentheses(p + 1, q - 1);
}
return false;
}
int priority(int op_type){
switch (op_type)
{
case '(':
case ')':
return 0;
break;
case '+':
case '-':
return 1;
break;
case '*':
case '/':
return 2;
break;
case TK_NEGATIVE:
return 3;
break;
default:
assert(0);
}
}
struct stack_node{
int idx;
int type;
};
void printfexpr(int p, int q){
printf("expr:");
for (int i = p; i <= q; i++){
if (tokens[i].type == TK_NUMBER){
printf("%s", tokens[i].str);
} else {
printf("%c", (char)tokens[i].type);
}
}
printf("\n");
}
word_t eval(int p, int q, bool *success){
printfexpr(p, q);
word_t number;
if (p > q){
*success = false;
return 0;
} else if (p == q){
if (sscanf(tokens[p].str,"%u", &number) < 1){
*success = false;
return 0;
}
return number;
} else if (check_parentheses(p, q) == true){
return eval(p + 1, q - 1, success);
} else {
if (check_expr_parentheses(p, q) == false){
*success = false;
return 0;
}
int i;
int top = -1;
int op_type;
word_t val1;
word_t val2;
struct stack_node stack[1024];
/*
* 出现在一对括号中的token不是主运算符. 注意到这里不会出现有括号包围整个表达式的情况, 因为这种情况已经在check_parentheses()相应的if块中被处理了.
* 主运算符的优先级在表达式中是最低的.
* 当有多个运算符的优先级都是最低时, 根据结合性, 最后被结合的运算符才是主运算符
* 一个例子是1 + 2 + 3, 它的主运算符应该是右边的+.
*/
for (i = p; i <= q; i++){
if (tokens[i].type == TK_NUMBER) continue;
if (top < 0){
top++;
stack[top].idx = i;
stack[top].type = tokens[i].type;
continue;
}
if (tokens[i].type == (int)('(')){
top++;
stack[top].idx = i;
stack[top].type = tokens[i].type;
continue;
}
if (tokens[i].type == (int)(')')){
/*出现在一对括号中的token不是主运算符*/
while (top >=0 && stack[top].type != '('){
top--;
}
/*pop (*/
top--;
continue;
}
/*优先级越低越在stack下面,主运算符的优先级在表达式中是最低的.当有多个运算符的优先级都是最低时, 根据结合性, 最后被结合的运算符才是主运算符*/
while (top >= 0 && priority(tokens[i].type) <= priority(stack[top].type) ){
if (tokens[i].type == stack[top].type && stack[top].type == TK_NEGATIVE){
/*负号比较特殊,当负号前面是负号时,主运算符是前面的负号,如--1*/
break;
}
top--;
}
++top;
stack[top].idx = i;
stack[top].type = tokens[i].type;
}
/*If the primary operator cannot be found, the expression is incorrect.*/
if (top < 0){
printf("what happen? top<0!!!");
printfexpr(p, q);
*success = false;
return 0;
}
if (stack[0].type == TK_NEGATIVE){
val1 = -1;
val2 = eval(stack[0].idx + 1, q, success);
op_type = '*';
} else {
val1 = eval(p, stack[0].idx - 1, success);
val2 = eval(stack[0].idx + 1, q, success);
op_type = stack[0].type;
}
/*Something went wrong in a step of the recursive solution.*/
if (*success != true){
printf("what happen? child call fail!!!");
printfexpr(p, q);
return 0;
}
switch (op_type)
{
case '+':
return val1 + val2;
case '-':
return val1 - val2;
case '*':
return val1 * val2;
case '/':
if (val2 == 0){
printf("what happen? val1 / val2 and val2 == 0!!!");
printfexpr(p, q);
*success = false;
return 0;
}
return val1 / val2;
default:
assert(0);
}
}
}
int main()
{
// init_regex();
// FILE *file;
// //char line[65536 + 128];
// char exprbuf[65536]="2 + ----1\0";
// uint32_t result = 3;
// int i;
// bool success = true;
// printf("- origin line: %s\n- success: %d\n- exprbuf: %s\n- result:%u\n",
// exprbuf, success, exprbuf, result);
// word_t ans = expr(exprbuf, &success);
// if (success == false || result - ans != 0){
// printf("- origin line: %s- success: %d\n- exprbuf: %s\n- result:%u\n- ans: %u\n",
// exprbuf, success, exprbuf, result, ans);
// printf("tokens:\n");
// for (i = 0; i < nr_token; i++){
// if (tokens[i].type == TK_NUMBER){
// printf("%s", tokens[i].str);
// } else {
// printf("%c", (char)tokens[i].type);
// }
// }
// printf("\n");
// return 0;
// }
// printf("\n");
// return 0;
init_regex();
FILE *file;
char line[65536 + 128];
char exprbuf[65536];
uint32_t result;
file = fopen("/home/cilinmengye/ics2023/nemu/tools/gen-expr/build/input", "r");
assert(file != NULL);
while (fgets(line, 65536 + 128, file) != NULL){
/*notice i and j need reset before start*/
int i = 0;
int j = 0;
int cnt = sscanf(line, "%u", &result);
assert(cnt == 1);
while (line[i] != ' '){
i++;
}
while (line[i] != '\n' && i < 65536){
exprbuf[j] = line[i];
j++;
i++;
}
exprbuf[j] = '\0';
bool success = true;
printf("- origin line: %s- success: %d\n- exprbuf: %s\n- result:%u\n",
line, success, exprbuf, result);
word_t ans = expr(exprbuf, &success);
if (success == false && result - ans != 0){
printf("- origin line: %s- success: %d\n- exprbuf: %s\n- result:%u\n- ans: %u\n",
line, success, exprbuf, result, ans);
printf("tokens:\n");
for (i = 0; i < nr_token; i++){
if (tokens[i].type == TK_NUMBER){
printf("%s", tokens[i].str);
} else {
printf("%c", (char)tokens[i].type);
}
}
printf("\n");
return 0;
}
printf("\n");
}
return 0;
}

监视点
扩展表达式求值的功能

获取寄存器的值:nemu/src/isa/riscv32/reg.c word_t isa_reg_str2val(const char *s, bool *success);
就是在已完成的基础上添加功能即可,注意优先级的实现!具体看我github上的代码吧
实现监视点



实现设置监控点
//nemu/src/cpu/cpu-exec.c
static void trace_and_difftest(Decode *_this, vaddr_t dnpc) {
#ifdef CONFIG_ITRACE_COND
if (ITRACE_COND) { log_write("%s\n", _this->logbuf); }
#endif
if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); }
IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));
IFDEF(CONFIG_WATCHPOINT, checkWatchPoint());
}
//其中Decode定义在nemu/include/cpu/decode.h
typedef struct Decode {
vaddr_t pc;
vaddr_t snpc; // static next pc
vaddr_t dnpc; // dynamic next pc
ISADecodeInfo isa;
IFDEF(CONFIG_ITRACE, char logbuf[128]);
} Decode;
在nemu/src/monitor/sdb/sdb.c init_sdb()实现了调用init_wp_pool();,所以初始化我们可以不用担心了~
void init_wp_pool();
void init_sdb() {
/* Compile the regular expressions. */
init_regex();
/* Initialize the watchpoint pool. */
init_wp_pool();
}
实现设置CONFIG_WATCHPOINT=y
//在nemu/Kconfig下的 menu "Testing and Debugging"下写上
config WATCHPOINT
bool "Enable watchpoint"
default n
然后是watchpoint.c的内容了:
/***************************************************************************************
* Copyright (c) 2014-2022 Zihao Yu, Nanjing University
*
* NEMU is licensed under Mulan PSL v2.
* You can use this software according to the terms and conditions of the Mulan PSL v2.
* You may obtain a copy of Mulan PSL v2 at:
* http://license.coscl.org.cn/MulanPSL2
*
* THIS SOFTWARE IS PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND,
* EITHER EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO NON-INFRINGEMENT,
* MERCHANTABILITY OR FIT FOR A PARTICULAR PURPOSE.
*
* See the Mulan PSL v2 for more details.
***************************************************************************************/
#include "sdb.h"
#include "utils.h"
#define NR_WP 32
typedef struct watchpoint {
int NO;
struct watchpoint *next;
/* TODO: Add more members if necessary */
word_t oldValue;
char *express;
} WP;
static WP wp_pool[NR_WP] = {};
static WP *head = NULL, *free_ = NULL;
void init_wp_pool() {
int i;
for (i = 0; i < NR_WP; i ++) {
wp_pool[i].NO = i;
wp_pool[i].next = (i == NR_WP - 1 ? NULL : &wp_pool[i + 1]);
}
head = NULL;
free_ = wp_pool;
}
/* TODO: Implement the functionality of watchpoint */
/*这两个函数会作为监视点池的接口被其它函数调用*/
/*
* new_wp()从free_链表中返回一个空闲的监视点结构
* 调用new_wp()时可能会出现没有空闲监视点结构的情况, 为了简单起见, 此时可以通过assert(0)马上终止程序
*/
WP* new_wp(){
Assert(free_ != NULL, "There is no free monitoring point returned in the free_ linked list");
/*free monitoring point from free_*/
WP* freeWP = free_;
free_ = free_->next;
/*link free monitoring point into head*/
freeWP->next = head;
head = freeWP;
return head;
}
/*
* free_wp()将wp归还到free_链表中
*/
void free_wp(WP *wp){
Assert(head != NULL, "There is no busy monitoring point free into the head linked list");
WP* front = head;
WP* tail = NULL;
bool success = false;
while (front != NULL){
if (front == wp){
success = true;
if (tail == NULL){
/*indicate front = head*/
Assert(front == head, "when tail == NULL, but front != NULL");
head = head->next;
} else {
Assert(tail != NULL, "tail == NULL in free_wp");
tail->next = front->next;
}
break;
}
tail = front;
front = front->next;
}
/*过滤未找到的NO交给no2Wp函数*/
Assert(success == true, "Can't find the corresponding wp in the head linked list");
front->next = free_;
free_ = front;
}
/*
* 扫描所有的监视点
* 在扫描监视点的过程中, 你需要对监视点的相应表达式进行求值(你之前已经实现表达式求值的功能了), 并比较它们的值有没有发生变化,
* 若发生了变化, 程序就因触发了监视点而暂停下来, 你需要将nemu_state.state变量设置为NEMU_STOP来达到暂停的效果.
* 最后输出一句话提示用户触发了监视点, 并返回到sdb_mainloop()循环中等待用户的命令.
*/
void checkWatchPoint(){
WP* freeWP = head;
word_t newValue;
bool success = true;
while (freeWP != NULL){
Assert(freeWP->express != NULL, "There are no express in watchpoint");
newValue = expr(freeWP->express, &success);
Assert(success == true, "The error express was put into watchpoint");
if (newValue != freeWP->oldValue){
nemu_state.state = NEMU_STOP;
printf("Hardware watchpoint %d: %s\n\n", freeWP->NO, freeWP->express);
printf("Old value = %u\n", freeWP->oldValue);
printf("New value = %u\n", newValue);
}
freeWP = freeWP->next;
}
}
void infoWatchPoint(){
WP* freeWP = head;
if (freeWP == NULL){
printf("No watchpoints\n");
return ;
}
printf("%-10s%s\n","Num","What");
while (freeWP != NULL){
printf("%-10d%s\n",freeWP->NO, freeWP->express);
freeWP = freeWP->next;
}
}
void free_wpByNO(int NO, bool *success){
WP* freeWP = head;
while (freeWP != NULL){
if (freeWP->NO == NO){
break;
}
freeWP = freeWP->next;
}
if (freeWP == NULL){
*success = false;
return;
}
free_wp(freeWP);
}
void new_wpSet(char *express, word_t oldValue){
WP* freeWP;
freeWP = new_wp();
Assert(freeWP != NULL, "Error in cmd_w When call new_wp(), the return value is NULL");
freeWP->express = express;
freeWP->oldValue = oldValue;
printf("Hardware watchpoint %d: %s\n", freeWP->NO, express);
}
之后的内置命令
cmd_d,cmd_w等就是在原来的基础在nemu/src/monitor/sdb/sdb.c上加就是了,没啥难的
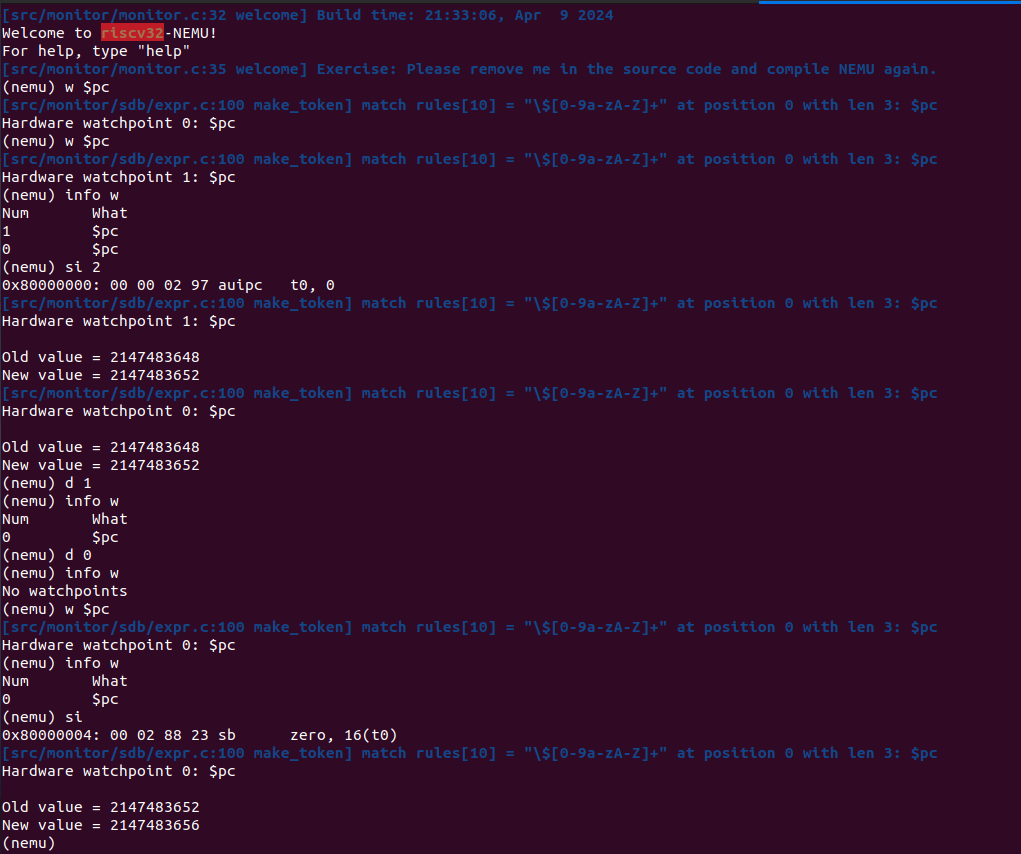
这么一套测试下面应该没问题吧~
gdb 参考输出
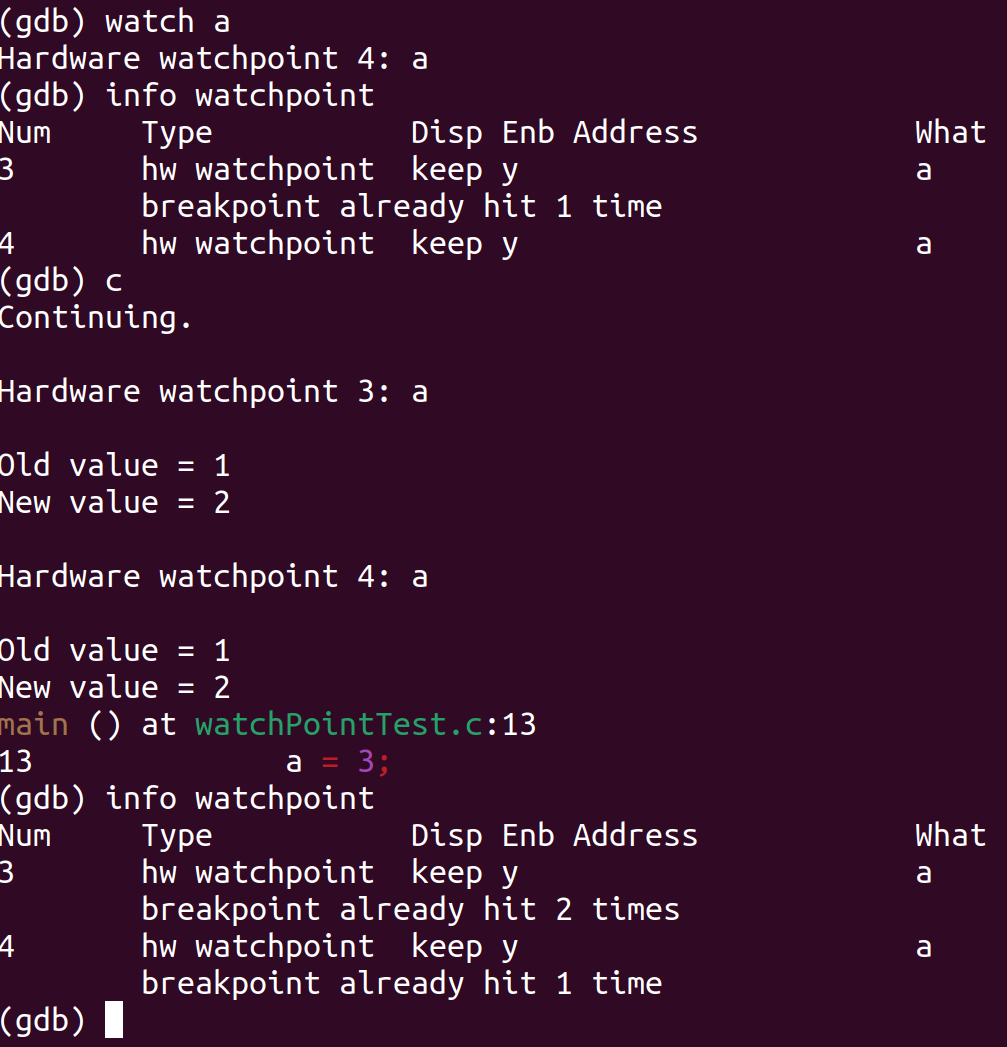
调试工具与原理


告知了我代码在哪里出现了段错误

断点

如果对于原先指令的长度就为1字节的,那么我们用
int 3覆盖,会覆盖掉原先指令后面一个指令的内容,如果这个时候我们不保存到2个指令的内容的话,就不能正常工作了

可能会导致运行其他奇奇怪怪的指令去了,如果学习过CSAPP就好懂了,因为我们的指令通过编码识别的,如果原先一个指令,中间或后面的编码突然变成了
int 3的编码,那么在通过分析编码判断这个是那条指令时,那么很可能被解释为其他指令去了。
但是如果int 3在最前面,那么int 3的编码最先被解析到,肯定将这个指令解释成int 3而不会出错
断点的实现方式
-
我们NEMU中断点的实现方式

-
实际上的断点的实现方式
推荐的这篇文章- 使用
int 3中断命令,int是trap instruction的简称,int 3只占一个字节 - 打断点时,将断点处的指令的第一个字符替换成
int 3, 记录原先的指令内容 - 执行,执行到
int 3触发中断,注意我们在用gdb调试时,运行的程序只是我们gdb的一个子进程,当子进程中断,作为父进程的gdb可以通过捕获信号的方式,做一些处理:比如这个时候查看子进程程序中运行的状态(变量值,pc值,寄存器值...) - 再运行,然后我们要恢复之前保存的 原先的指令内容,然后让pc--(因为他要运行我们恢复的指令内容)
- 使用
如何阅读手册

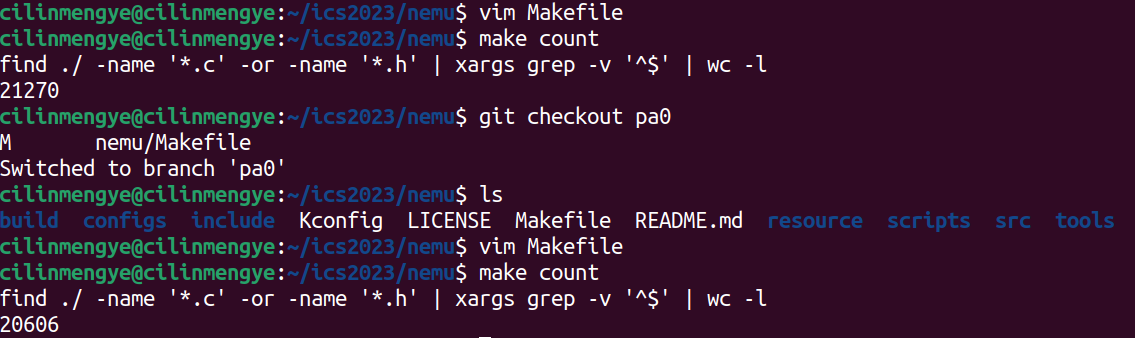
原来我就写了600多行代码...但是我感觉过了一个世纪一般漫长
非改源码,配置命令记录
git commit --allow-empty -am "before starting pa1"
git checkout master
git merge pa0
git checkout -b pa1
/*
* PA1: 在开始愉快的PA之旅之前
* 在这个[网站](https://box.nju.edu.cn/f/3e56938d9d8140a7bb75/?dl=1)上下载游戏的rom
* 发现在ics2023下有fceux-am这个文件夹,根据fceux-am/README.md,就知道要将压缩包放到那里了
* 启动游戏后我的键盘对这个游戏没有相应,但是执行
* cd ics2023
* bash init.sh am-kernels
* cd am-kernels/tests/am-tests
* make ARCH=native mainargs=k run
* 运行测试程序后键盘响应是有效的
* 算是一个遗留问题吧
*/
# 加速编译的软件
/* 我们清除所有编译结果之后重新编译, 源文件并没有发生任何变化, 按道理编译出来的目标文件也应该和上一次编译结果完全相同.
* 既然这样, 那我们能不能把这些目标文件以某种方式存起来, 下次编译的时候如果发现源文件没有变化,
* 就直接取出之前的目标文件作为编译结果, 从而跳过编译的步骤呢?
*/
sudo -i
apt-get install ccache
vim ~/.bashrc #然后末尾添加上export PATH="/usr/lib/ccache:$PATH"
which gcc #查看结果是/usr/lib/ccache/gcc
make -j2 #用两个CPU加速编译
# 为NEMU编译时添加GDB调试信息
make menuconfig
选择bulid option
选择Enable debug information
save
exit
exit
make clean
make
make menuconfig
选择bulid option
选择Enable address sanitizer
save
exit
exit
make clean
make
gdb 小知识
-
跳出循环
until 源代码行号num
含义为运行到num行,然后停止 -
在gdb中打印的字符串数组过长,报错:gdb:value requires 400020 bytes, which is more than max-value-size
解决方案
键入命令set max-value-size unlimited -
以16进制的形式打印出内存n个4字节内容
x/4xw pmemgdb中使用“x”命令来打印内存的值,格式为“x/nfu addr”。含义为以f格式打印从addr开始的n个长度单元为u的内存值。参数具体含义如下:
a)n:输出单元的个数。
b)f:是输出格式。比如x是以16进制形式输出,o是以8进制形式输出,等等。
c)u:标明一个单元的长度。b是一个byte,h是两个byte(halfword),w是四个byte(word),g是八个byte(giant word)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号