CSAPP Cache Lab

知识点
在这里我会回答以下几个问题:
-
计算机的访问内存的整个流程是什么?计算机中
虚拟地址,物理地址(P573),以及访问缓存的地址(P426) 他们之间的关系是什么,又是如何进行转换的? -
我们在两个C语言程序中打印某个变量的内存,发现他们的内存显示是一样的,难道不会冲突吗?
PS:图均来自九曲阑干
Question1
让我们先来了解下缓存
我们要知道,为了解决CPU与存储器之间速度的巨大差异,我们的存储器并不再是单纯地指内存了。
我们也不再是单纯地将我们运行程序时访问内存抽象成直接访问一个数组了,而是访问一个存储器层次结构
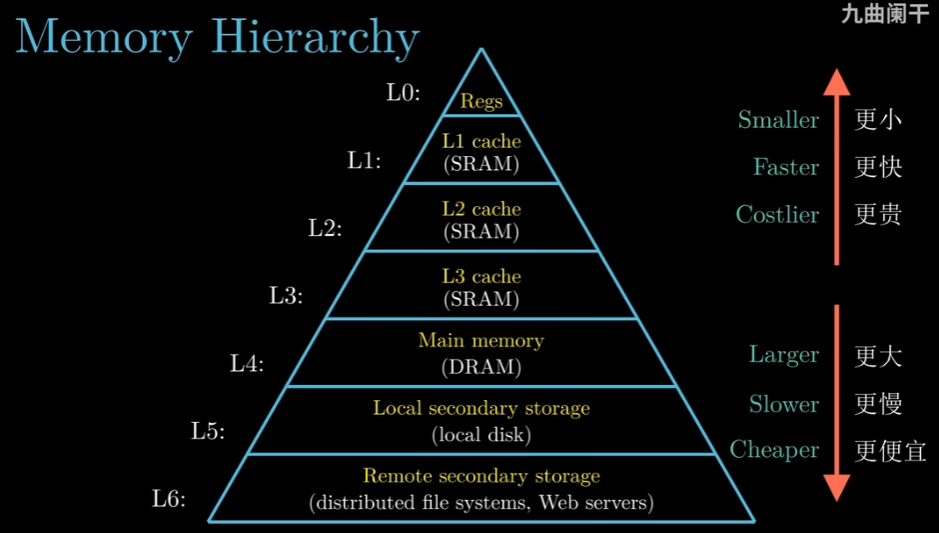
其中,缓存贯穿存储器层次结构,甚至可以说第Li-1层就是第Li层的缓存
不同层次之间的数据交流是以块为单位,为此各个层次的存储器都对数据进行了分块(特殊的是在内存和磁盘之间的数据交流单位也被称为页,这主要是因为有虚拟内存技术)
相邻的层次之间块的大小是一样的
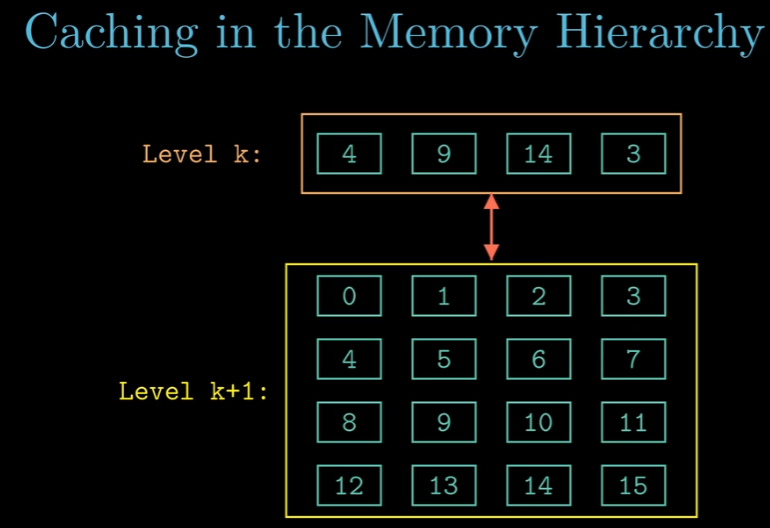
在L1~L3cache这些缓存,内部结构是有S个set,每一个Set中有E行,每一行保存着有效位,标记位,缓存位(P426),这种结构被称为缓存块。
缓存行大小 == 2^缓存位,现代CPU中典型的缓存行大小为64字节,即缓存位一般9位。

那么我现在有来自CPU的地址,那么我如何使用地址去访问缓存呢?
在地址的基础上,原地将物地址分为标记,组索引,块偏移这些位(P426)
内存按照L1~L3cache一行能够保存数据的大小划分了块,每一个块属于不同的组(P432)
假设地址0x0DD5,那么翻译为二进制为0000....0000 1101 1101 0101(共64位)
假设L1cache的组有8个,那么组索引位有3位;一行能够保存4字节,那么块偏移位有2个。剩下的58位为标记位,同时使用直接映射高速缓存方式
那么我们可以知道地址0x0DD5在第5组,偏移字节数为2,标记为0x6E
在内存与磁盘之间,内存是磁盘的缓存
想一想当我们有许多程序,如果每一个程序的数据,代码等都放到内存,那么内存肯定是放不下的。但是为了保持每一个程序都能够时刻运行,好像他们都在内存中的假象,我们偷偷将在内存中放不下的数据放到了磁盘上,可以说磁盘就是我们虚拟出来的内存
我们的x86-64,那么我们的总共有N=2^64个地址,这个地址被称为虚拟地址,这个虚拟地址被用在操作系统给我们的程序提供的内存映像中
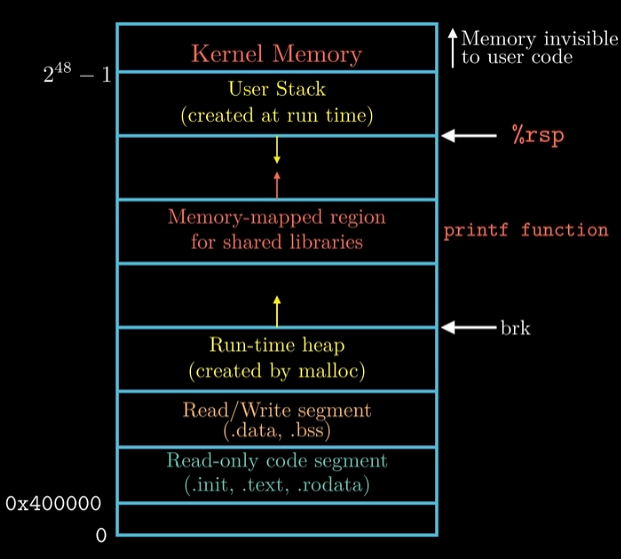
可以看到,在这里每一个程序的代码段,数据段等从0x400000开始,一直到2^48-1都是用户可用的地址空间,再往上就是内核的地址空间了。
这些地址就是虚拟地址,我们的每一个程序在运行时,指令中都是这样的地址,同时我们每一个程序都有属于自己的页表
和缓存一样,程序的内存映像被分块,而页表就记录的每一块是否在内存?在内存的哪个物理地址。
在一个带虚拟内存的系统中,CPU得到虚拟地址,然后虚拟地址被内存管理单元MMU(P560)翻译(通过我们的页表)成适当(当我们要的数据在内存时,通过页表直接翻译。当不在内存而是还在磁盘上时,要将磁盘上的数据放到内存,记录放的内存地址,再翻译)的物理地址。
然后我们带着我们的物理地址,经过层层缓存,或遇到缓存上有数据,或最后还是要访问内存
那么总结来了
虚拟地址- - - MMU翻译 -- - > 物理地址 - - 原地划分(即物理地址没变,只是按位划分了) - - > 缓存地址 - - - 如果要访存 - - -> 物理地址
有一个具体的例子,来自书P573
但是在现代计算机体系结构中,CPU请求L1,L2缓存时使用的是虚拟地址进行索引,但最终匹配缓存行时依赖物理地址的标记。
当CPU需要访问数据时,流程如下:
-
虚拟地址生成:程序使用虚拟地址(Virtual Address, VA)访问内存。
-
缓存索引与地址转换并行:
-
缓存索引:虚拟地址的一部分(如中间位)用于直接定位L1缓存中的缓存行(称为 Virtual Index)。
-
地址转换:同时,虚拟地址通过MMU(内存管理单元)转换为物理地址(Physical Address, PA)。
-
-
标记匹配:缓存的每个条目包含物理地址的标记(Physical Tag),转换后的物理地址与缓存行的标记进行比较。
- 若匹配(Tag Hit),则缓存命中,直接返回数据。
- 若不匹配(Tag Miss),则触发缓存未命中,需从下级缓存或主存加载数据。
这是一种被称为 VIPT(虚拟索引、物理标记)的架构
我们来看看我们的内存是如何组成的
首先我们的内存是由许多DRAM芯片封装而成,被称之为内存模块
每一次要读取数据时,内存控制器(P401)将物理地址翻译成(行地址,列地址)的形式,并行地从8片DRAM相同的行列定位到的DRAM超单元中读取数据,每一个超单元中有8bit数据,所以总共读取到8x8=64bit数据,并保存到内存控制器中(工作方式如下图左图所示)
这种并行的工作方式可以提高我们存储数据的速度,所以我们的数据是分开存放到不同DRAM芯片上的。
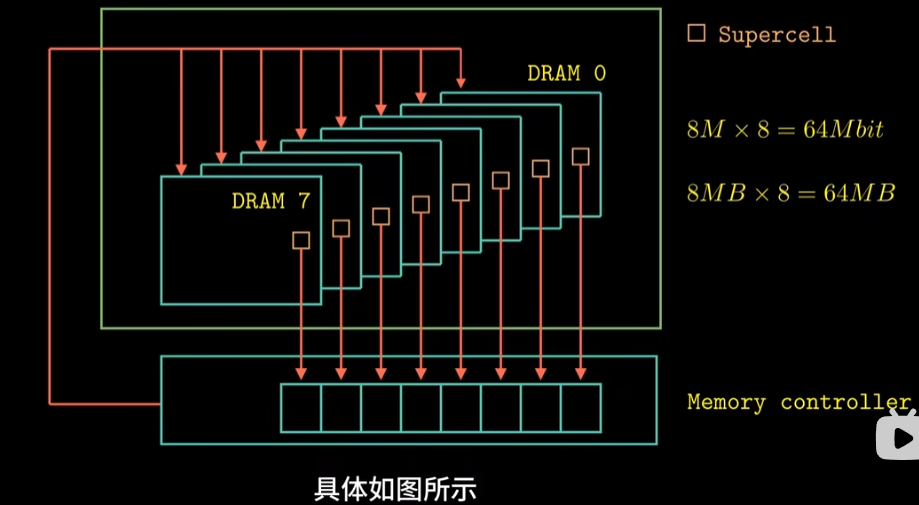
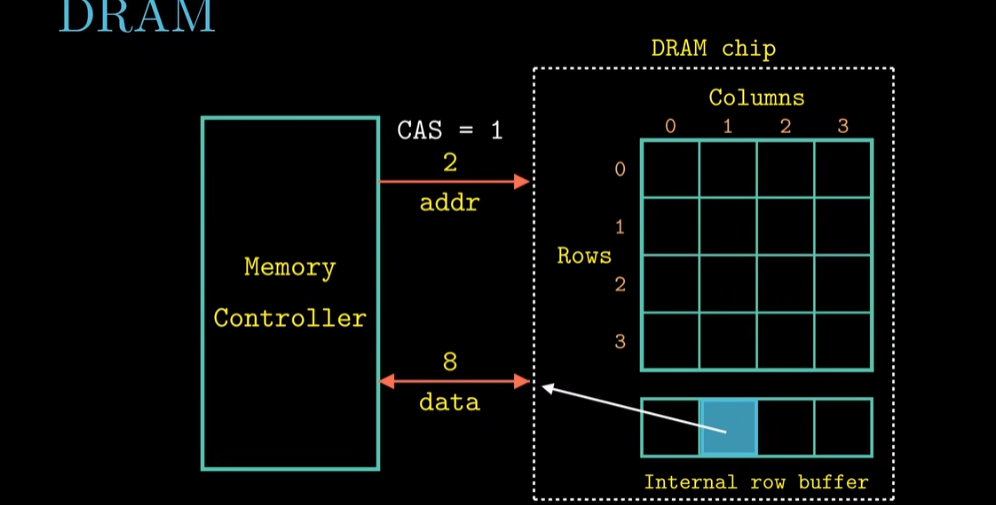
每一个DRAM芯片工作方式如右图所示,其通过内存控制器转换出来的(行地址,列地址)的形式地址,先读取行地址,将一行放入内存行缓冲器,在读取列地址,选取唯一的超单元(P401)
我们往往忽视这种复杂的访问内存的方式,而是将内存看做是一个大数组,我们为每一个字节都进行了编址,我们俗称物理地址
要存取数据时我们带着物理地址访问就行,具体各种操作由操作系统和硬件帮我们完成了
Question2
我们的程序写好后,经过编译,汇编,链接之后得到可执行目标文件,其都是保存在磁盘上.

每一个程序运行时都有一个内存映像
我们再程序中打印出来的内存地址其实都是'假内存地址',即在内存映像中的内存地址,即虚拟地址。
即使我们的程序都有相同的虚拟地址,但是每一个程序的独有页表也都会将这个虚拟地址翻译到或者相同,或者不同的物理地址上。如果这个物理地址是相同的,很有可能说明这个物理地址上有程序都要的东西(如共享库代码,内核代码等)。
虚拟内存 页表 TLB SWAP
我们知道每个进程都有个虚拟内存映像,其中代码段,数据段,共享库区,内核区...这些没有在运行时就有在的静态内容早早地被存放在了磁盘上,即是持久化的内容。
想像下我有个程序,其ELF二进制可执行文件被放在磁盘中,现在我创建了个进程来执行这个程序,我们来看看这整个过程是如何的:
基础知识:内存映射
Linux 通过将一个虚拟内存区域与一个磁盘上的对象(object)关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)
内核 loader 加载器,加载可执行程序和动态库将可执行文件的各段(text、data 等)映射到虚拟地址空间中即是内存映射的一个过程
一般我们是通过调用mmap函数实现将某个虚拟内存区域映射到磁盘上一段已有的文件(比如可执行文件、库文件、数据文件)上的连续区间。
虚拟内存区域(Virtual Memory Area, VMA):在 Linux 进程的地址空间中,每个连续的、权限(读/写/执行)相同的地址范围由内核用一个数据结构(如 vm_area_struct)表示,称为一个虚拟内存区域。
#include <unistd.h>
#include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags,
int fd, off_t offset);
// 返回:若成功时则为指向映射区域的指针,若出错则为 MAP_FAILED(-1)。
mmap 函数要求内核最好从start的位置创建(start 地址仅仅是一个暗示,通常被定义为 NULL)一个新的虚拟内存区域,并将文件描述符 fd 指定的一片连续的对象(这个对象从文件开头偏移量offset开始,长度为length)映射到新的虚拟内存区域。
参数 prot 包含描述新映射的虚拟内存区域的访问权限位(即在相应区域结构中的 vm_prot 位)。
- PROT_EXEC:这个区域内的页面由可以被 CPU 执行的指令组成。
- PROT_READ:这个区域内的页面可读。
- PROT_WRITE:这个区域内的页面可写。
- PROT_NONE:这个区域内的页面不能被访问。
参数 flags 与内存映像的机制有关,我们在下面详细讲解:
虚拟内存区域背后可以关联的“对象”(object)主要有两种情况:
- 文件系统中的普通文件(File-backed mapping):磁盘上一段已有的文件(比如可执行文件、库文件、数据文件)上的连续区间。
- 匿名文件(Anonymous mapping): 没有对应的磁盘普通文件,通常初始内容全是 0。
- 进程的堆(brk/sbrk 实现底层可能也依赖匿名映射)和线程栈,动态申请内存(如 malloc),共享匿名内存(如 POSIX 共享内存的一种实现)。
- 临时使用的大块内存,不需要持久化内容。
文件系统中的普通文件
mmap(addr, length, prot, MAP_PRIVATE or MAP_SHARED, fd, offset)
参数flag上可以有两种写法:
MAP_PRIVATE: 表现行为为写时拷贝(COW),即对映射区写入时修改不会写回文件,仅在内存中产生私有副本。MAp_SHARED: 写入会直接修改底层文件(或标记脏页稍后写回磁盘)。
这也是进程间一种通信的方式:共享内存,多个进程对同一文件做 MAP_SHARED,可实现跨进程通信。
匿名文件
mmap(NULL, length, prot, MAP_ANONYMOUS | MAP_PRIVATE, -1, 0)。
因为匿名文件的定义就说不对应文件系统上任何文件,所以参数 fd 为-1,offset 为0
参数 flag 一般写法为MAP_ANONYMOUS | MAP_PRIVATE, 表示映射不对应任何文件,同时映射区域的写操作是“私有的”:任何写入只影响本进程的私有页(通过写时拷贝机制),不会修改文件内容,也不会对其他映射同一文件或映射同一区域的进程可见。
交换空间
交换空间本质上就是操作系统用来存放被换出的内存页的磁盘区域,常见形式是专门划分的 swap 分区或 swap 文件。
通过交换空间,操作系统可以让活跃的、经常访问的页保留在物理内存中,而把长时间未访问或优先级较低的页移到磁盘上,进而支持总的虚拟内存容量超过物理内存大小。
对于匿名内存(anonymous memory,比如通过 malloc/new 分配的内存,或通过 mmap 分配的、非文件映射的区域),操作系统需要确保每个已分配的虚拟页都有一个可用的后备存储位置,以便在物理内存压力下可以换出。
因此,一旦分配(初始化)了该虚拟页,就会在交换空间中为它保留“对应的位置”(可以是延迟分配,但逻辑上存在后备),并在之后进行换入/换出操作。
swap 文件/分区本身的磁盘空间占用是系统管理员或发行版配置 swap 时就固定了,而不是程序每次启动才动态分配这部分空间。
程序申请匿名内存主要影响的是虚拟内存的可分配额度和后续可能的 swap 写入,而不是每次都直接占用新的磁盘空间。
交换空间限制虚拟页总数
内核会把可用的交换空间大小视作对匿名内存分配的一个约束。
换句话说,能分配的匿名虚拟内存 ≈ 物理内存 + 交换空间(再考虑内核的 overcommit 策略和安全性检查)。
如果应付不了物理内存压力,必须依赖足够的交换空间,否则会拒绝分配或触发 OOM(out of memory) 机制。
首先fork
内核为新进程创建各种数据结构,并分配给它一个唯一的 PID。
为了给这个新进程创建虚拟内存,它创建了当前进程的 mm_struct、区域结构和页表的原样副本。
原样副本意味着不管是原先的私有虚拟映像空间,还是共享虚拟映射空间,新旧进程都指向了同一块物理区域:
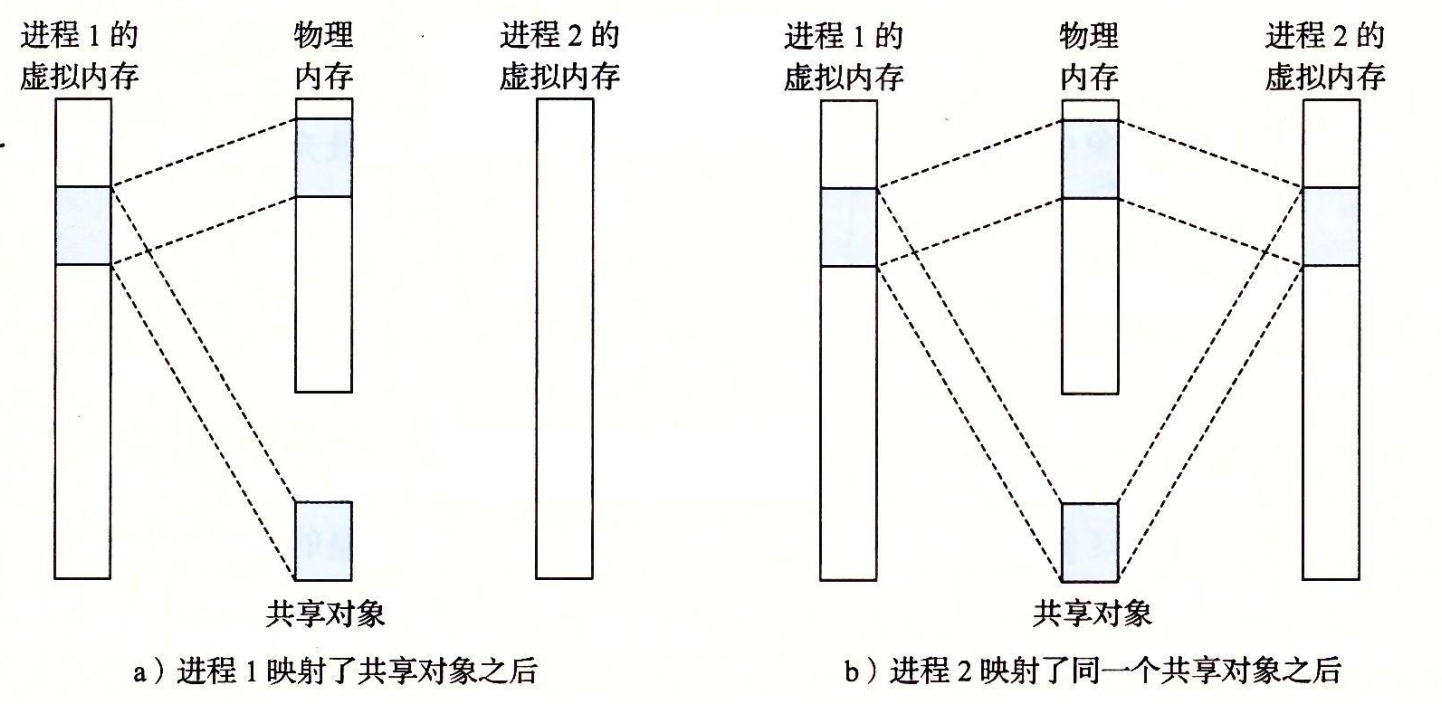
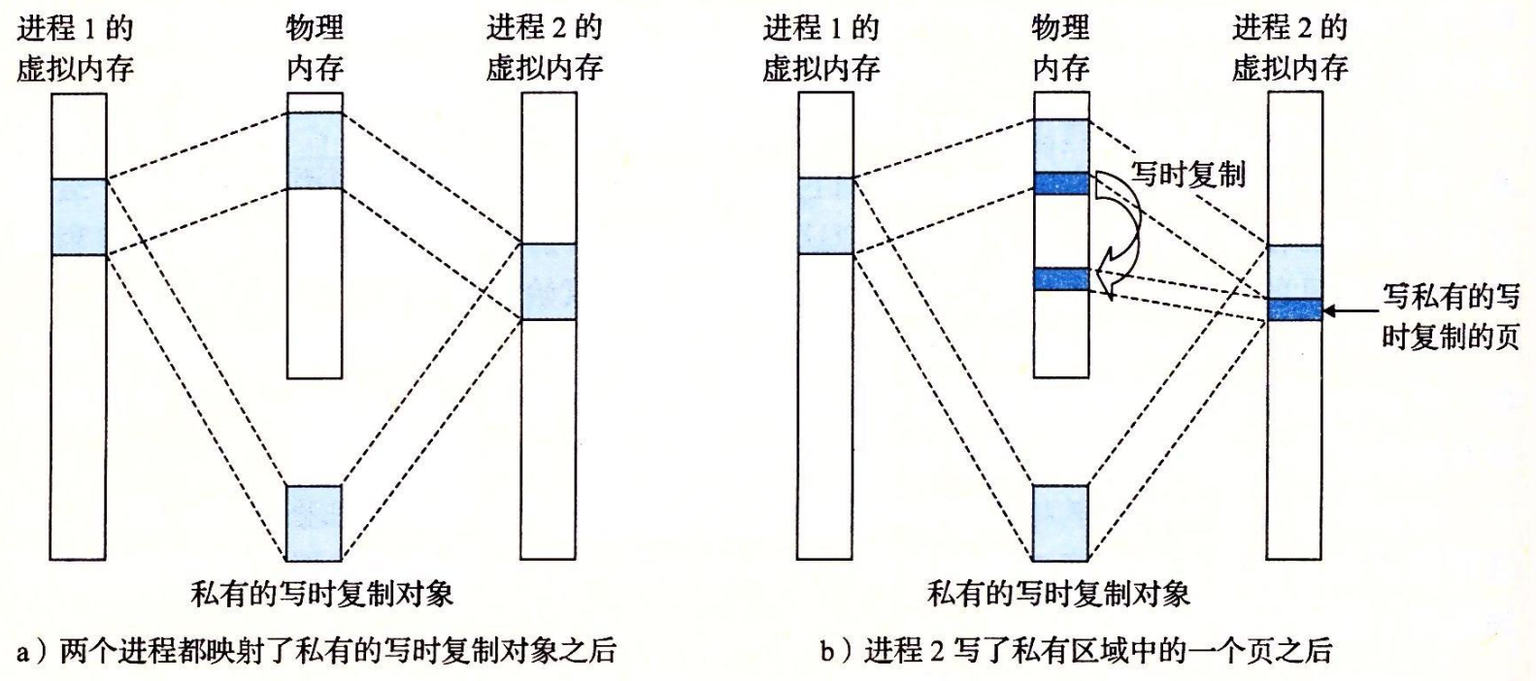
对于私有虚拟映像空间,为保证进制之间的独立性,私有对象使用一种叫做写时复制的技术:
- 相应私有区域的页表条目都被标记为只读,并且区域结构被标记为私有的写时复制。
- 当没有进程试图写它自己的私有区域,它们就可以继续共享物理内存中对象的一个单独副本。
- 只要有一个进程试图写私有区域内的某个页面,那么这个写操作就会触发一个保护故障:
- 当故障处理程序会在物理内存中创建这个页面的一个新副本,更新页表条目指向这个新的副本,然后恢复这个页面的可写权限
- 写时复制机制保证创建新页面应对任一个后来进行的写操作,因此,也就为每个进程保持了私有地址空间的抽象概念。
再看 execve 函数
execve重点会运用上述我们讲解的内存映射技术:
-
映射私有区域。为新程序的代码、数据、bss 和栈区域创建新的区域结构。
- 所有这些新的区域都是私有的、写时复制的。
- 代码和数据区域被映射为可执行文件中的. text 和. data 区。
- bss 区域是请求二进制零的,映射到匿名文件,其大小包含在 可执行文件 中。
- 栈和堆区域也是请求二进制零的,初始长度为零。
-
映射共享区域。
- 如果 程序与共享对象(或目标)链接,比如标准 C 库 libc.so,那么这些对象都是动态链接到这个程序的,然后再映射到用户虚拟地址空间中的共享区域内。
页表
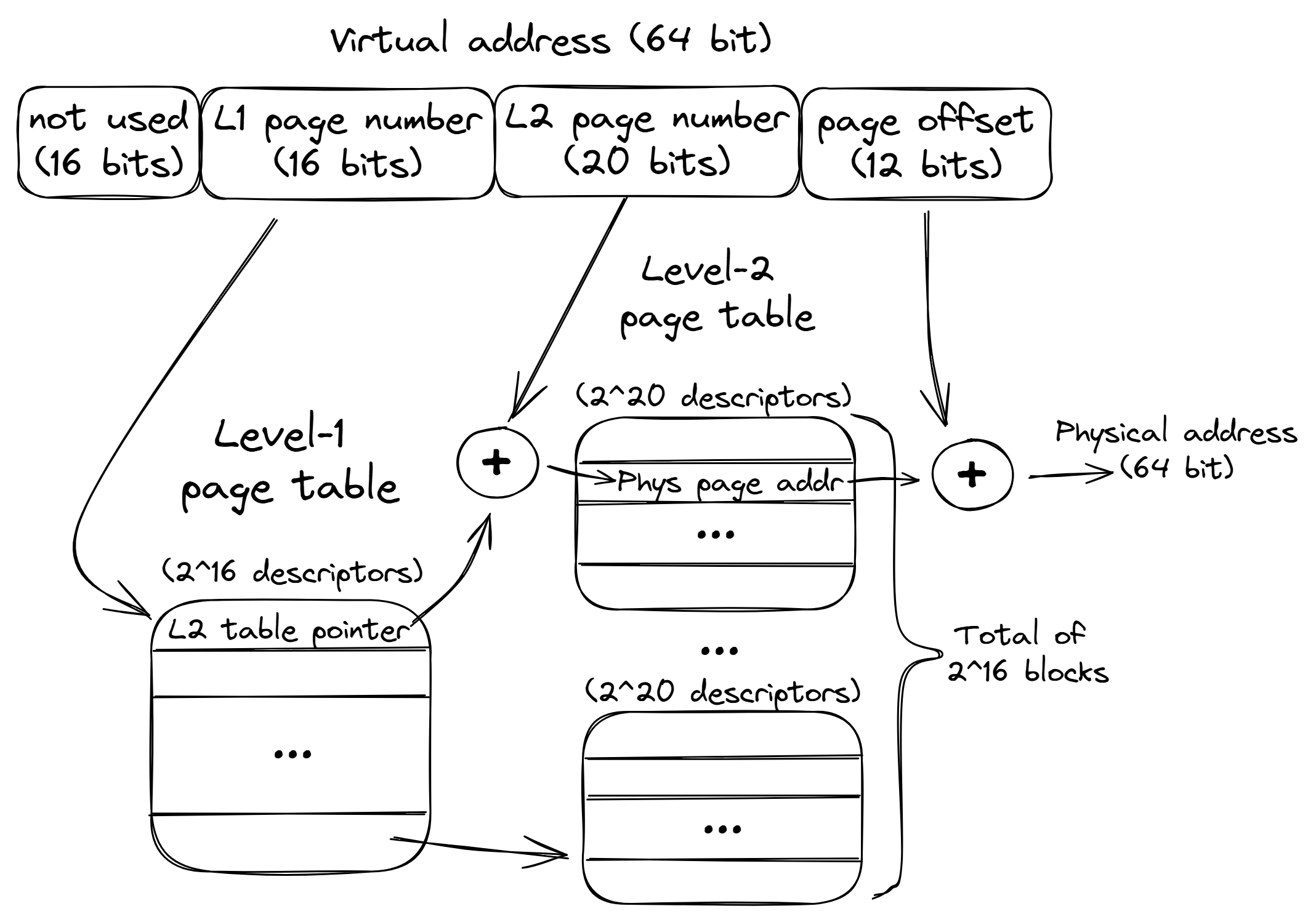
对于使用1级页表的处理器来说,依赖页表将虚拟内存地址转化为物理地址的过程如下:
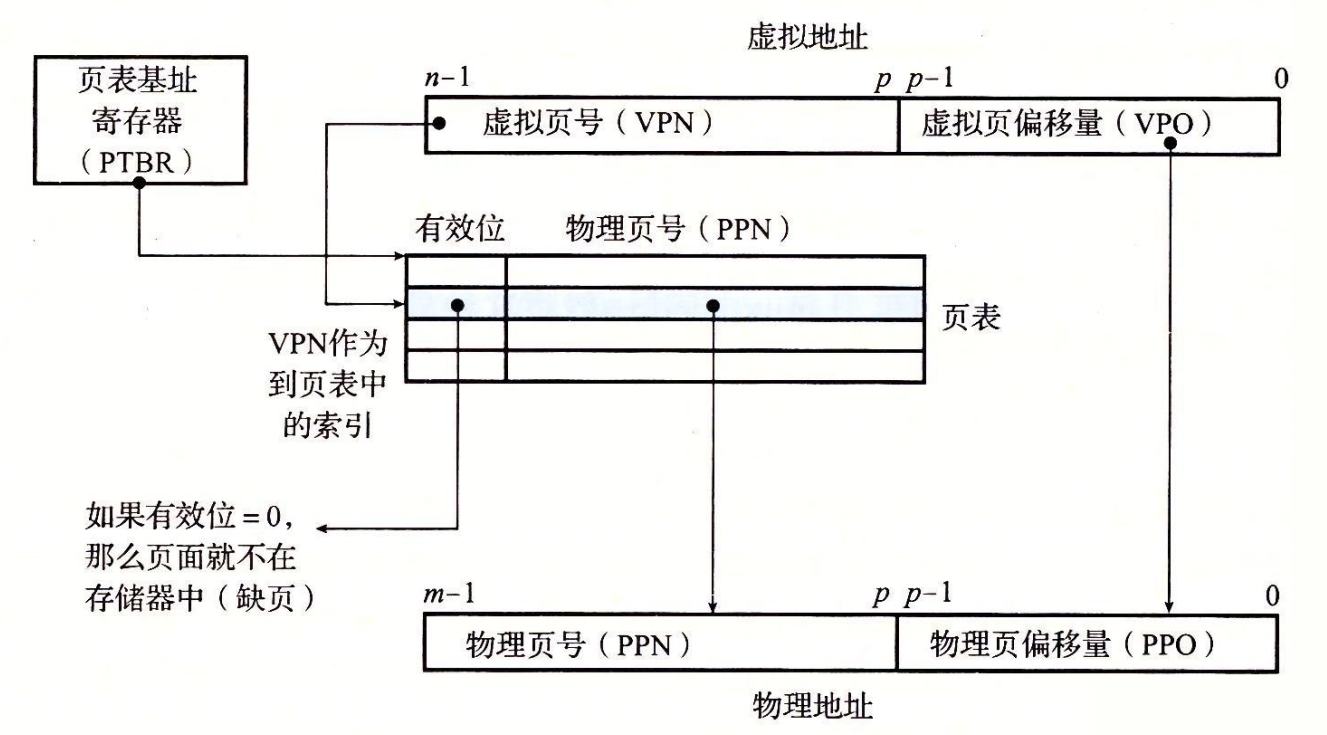
页表命中时
- 第 1 步:处理器生成一个虚拟地址,并把它传送给 MMU。
- 第 2 步:MMU 生成 PTE(Page Tabel Entry 页表项) 地址,并从高速缓存/主存请求得到它。
- 第 3 步:高速缓存/主存向 MMU 返回 PTE。
- 第 4 步:MMU 构造物理地址,并把它传送给高速缓存/主存。
- 第 5 步:高速缓存/主存返回所请求的数据字给处理器。
需要注意:我们每次将虚拟地址转换为物理地址时都需要查询页表项地址来告知我们该进程虚拟地址所在的页对应的物理地址的页
需要注意的是我们PTE地址的内容也是可以被cache缓存的,这样我们就可以不用每次再跳到页表地址中查看页表中记录的物理地址页内容
后续我们有专门缓存页表项的物理硬件:TLB。
在 MMU 中包括了一个关于 PTE 的小的缓存,称为翻译后备缓冲器(Translation Lookaside Buffer,TLB)。
TLB 是一个小的、虚拟寻址的缓存,其中每一行都保存着一个由单个 PTE 组成的块。
TLB对多级页表中尤为关键,因为多级页表常常要跳转多个内存物理地址区域获取到物理地址页:
大页
使用较小的页面大小可以更有效地管理可用内存并减少碎片化。然而,缺点是它需要更多的页表条目来覆盖相同的内存区域。考虑两种页面大小:4KB(x86 上的默认大小)和 2MB 的“大页”大小。对于处理 10MB 数据的应用程序,在第一种情况下需要 2560 个条目,而如果将地址空间映射到巨大页面,只需要 5 个条目。
较少的页表条目(页表项)可以很大程度上减少TLB的cache miss,从而提高性能
大页的缺点是内存碎片化,想象一些在做Malloc Labs时,一口气分配一个很大区域的空间,很可能这个空间中许多空间没有用上
同时后续过程中想要获得到一个完整的大页会越来越困难,会加大内核分配调度的延迟。
分块
思考过程
Tool
Valgrind
The Valgrind Quick Start Guide
The Valgrind tool suite provides a number of debugging and profiling tools that help you make your programs faster and more correct. The most popular of these tools is called Memcheck. It can detect many memory-related errors that are common in C and C++ programs and that can lead to crashes and unpredictable behaviour.
trace files are generated by a Linux program called valgrind
linux> valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes ls -l
Valgrind memory traces have the following form:
I 0400d7d4,8
M 0421c7f0,4
L 04f6b868,8
S 7ff0005c8,8
The format of each line is [space]operation address,size
Part A
- We recommend that you use the getopt function to parse your command line arguments.
- Each data load (L) or store (S) operation can cause at most one cache miss.
- The data modify operation (M) is treated as a load followed by a store to the same address.
Why modify can be treated as a load followed by a store to the same address?解释:
-
L操作CPU 发送请求到内存,以获取指定地址的值,并将检索到的值放入 CPU 寄存器。常见代码如:int x = array[i]
-
S操作CPU 从寄存器中获取值,并将其写入到指定的内存地址。,常见代码如:array[i] = x
-
M操作CPU 首先读取指定内存地址的当前值(加载),然后执行必要的计算或修改,最后将新值写回相同地址(存储)。常见代码如:array[i] = array[i] * x
具体而言,这道题目需要我们模拟通用的高速缓存存储器组织结构,读取Valgrind输出的memory traces, 将hit(命中),miss(未命中),evictions(替换)的情况输出。
通用的高速缓存存储器组织结构为:
根据每个组的高速缓存行数E,高速缓存被分为不同的类:
- E = 1,直接映射高速缓存
- 1 < E < C/B, 其中C = B(块大小) * S(组数) * E(组内行数),组相联高速缓存
- E = C/B,即S = 1,全相联高速缓存
缓存和内存地址之间的映射方法为:
- 组选择
- 行匹配
- 字抽取
内存的地址从左到右被'原地'划分为三部分:
-
标记位
-
组索引
-
块偏移
通过组索引进行组选择,标记位进行行匹配,块偏移进行字抽取
为何组索引用内存地址中间的位表示?
根据空间局部性原理,为了防止连续的内存块映射到相同的高速缓存块中,引发抖动等不良现象。
组相联高速缓存和全相联高速缓存每组具有多行,进行组选择后发现需要替换出去一行缓存,这时如何进行行匹配呢?
根据局部性原理有最近最少使用(LRU)策略,替换掉最后一次访问时间最久远的那一行
最不常使用(LFU)策略,替换掉过去某个时间窗口内引用次数最少的那一行
Part B
In Part B you will write a transpose function in trans.c that causes as few cache misses as possible
- You are allowed to define at most 12 local variables of type int per transpose function.
- Your transpose function may not use recursion.
- Your transpose function may not modify array A
- You are NOT allowed to define any arrays in your code or to use any variant of malloc.
• 32 × 32: 8 points if m < 300, 0 points if m > 600
• 64 × 64: 8 points if m < 1, 300, 0 points if m > 2, 000
• 61 × 67: 10 points if m < 2, 000, 0 points if m > 3, 000
-
题目输入输出格式:
将MxN的A矩阵转置存放到B矩阵中
-
运行的cache组织结构:
It then evaluates each trace by running the reference simulator on a cache with parameters (s = 5, E = 1, b = 5).
即块大小32B,组数32
- cache写入的方式:
- 写回 + 写分配(默认版本):即当写命中时,尽量延迟更新,只有当替换算法要驱逐这个更新过的块时才把它写入紧接着的下一层(写回);写不命中时,加载相应的低一层的块到高速缓存中,然后更新(写分配)
- 直写 + 非写分配:即当写命中时,立刻更新紧接着的下一层(直写);写不命中时,避开高数缓存,直接将字写入下一层(非写分配)
建议:
- Since your transpose function is being evaluated on a direct-mapped cache, conflict misses are a potential problem. Think about the potential for conflict misses in your code, espec ially along the diagonal.
- Blocking is a useful technique for reducing cache misses.
- There is an interesting technique called blocking that can improve the temporal locality of inner loops.
- blocking is to organize the data structures in a program into large chunks called blocks.
- The program is structured so that it loads a chunk into the L1 cache, does all the reads and writes that it needs to on that chunk, then discards the chunk, loads in the next chunk, and so on
我总结出来的想法:
-
每次访问矩阵,若矩阵的数据没有缓存,那么将以块为单位进行缓存。
-
调整访问矩阵的方式,充分利用已经被缓存的矩阵数据,尽量将这块数据要进行的全部读和写完成掉再换下一块数据。矩阵有天生分块的数学基础,将分块的子矩阵在许多地方(如乘法和转置)遵循与标量相同的数学规则。
-
为了简化代码编写,要求行和列均是块大小的倍数,对于不规整矩阵,将其填充为方阵。
-
利用局部变量,局部变量经过编译器优化后不是保存在栈中,而是保存在寄存器中无需访存
优化矩阵转置
题目假定有一层cache,32个组,每组一行,每行可保存32字节,要转置的矩阵单位为int(4字节)
首先以一个32x32矩阵转置的为例,简单画图标明各个矩阵数据所会被保存到cache的哪个组中
先执行朴素转置算法,观察算法在哪里会导致cache频繁地不命中。
发现在对角线上有频繁的冲突不命中,以及每次在访问不同行时,每行只对1个int数据进行操作,没有充分利用缓存。
- 解决方法为分块,分块的依据为块内数据并不会在缓冲中引起冲突。尽量将这块数据要进行的全部读和写完成掉再换下一块数据。
- 对角线处的分块较为特殊,即使分块后也会有较多次冲突不命中,解决方法为使用局部变量保存一些下次会引发冲突不命中的数据。
优化矩阵乘法
PartA
知识点
getopt C 解析命令行
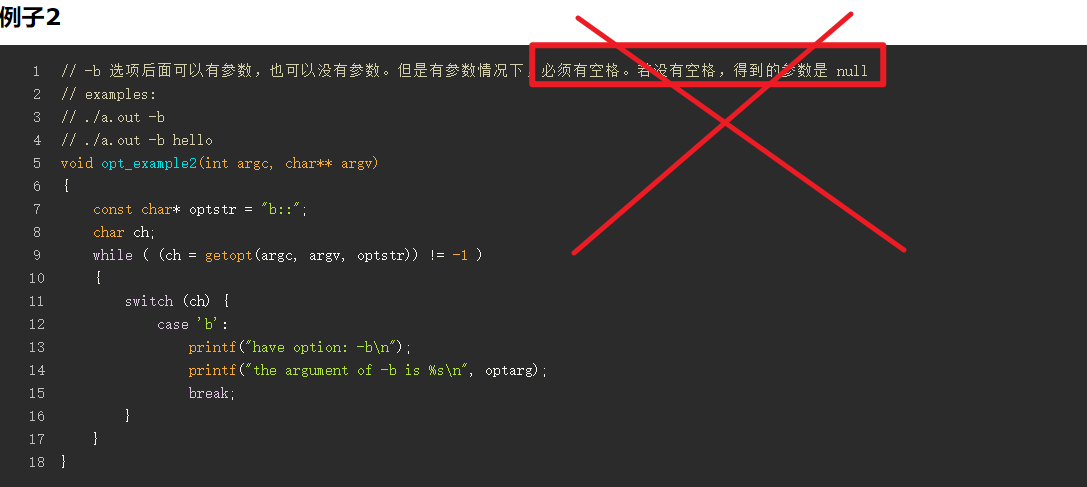
他这里写错了,应该是必须没有空格
gdb
p/d varname 相当于printf("%d",varname)
题解
算是算法比赛中的简单模拟题了
需要注意的是使用LRU算法时,记得每次要更新下使用到的cache行,没有使用到的cache行看个人实现方式,也要注意下是否要更新。
PartB
参考博客
思路:
画图,还是画图分析!

再结合分块,可以很自然的知道接下来如何做了
不过64x64的那个要得到满分真要点技巧
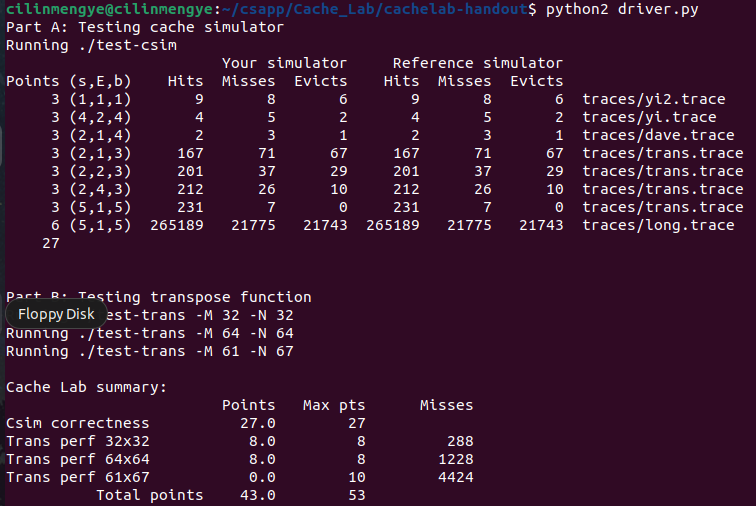
61x67的就放过我吧
具体图示在notebook中,具体解说在代码注释中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号