MapReduce依靠相同的字段合并两张表
在SQL中,我们可以根据两张表的相同的列,对两张表进行join操作。但是在MapReduce中是没有join这个方法的,要合并两张表只能靠自己去实现。
需求:
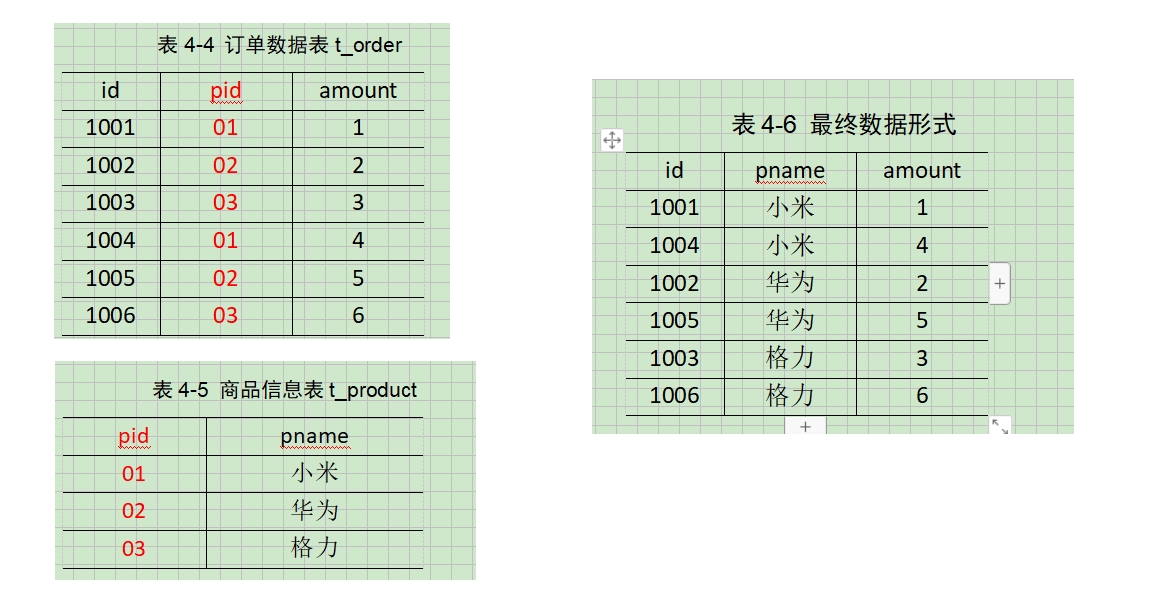
看到这两张表,
- 第一点:可以发现共同的列名是pid,所以待会pid在KV对中是肯定作为K的;
- 第二点:order表对product表来说多对一的关系。
无论什么都是MapReduce三板斧,mapper、reducer、driver三个类,而且由于数据类型需要序列化,作为KV对,所以还需创建一个bean类来存放数据类型的。
1.创建bean类,对两个表的各个字段实现序列化和反序列化,以及get()和set()方法,重写toString。还有就是增加一个字段,title,用来存储数据是来自哪张表的。
2.mapper类主要是读取两个表的数据,并把数据输出。其中pid作为输出类型的K,其他数据作为V。这里就有一个问题,怎么判断数据来自哪个表,所以需要先获取文件对象。
@Override protected void setup(Context context) throws IOException, InterruptedException { //获取文件切片逻辑对象,因为inputSplit是抽象类,没有实现getPath()方法,所以用其实现类FileSplit。我们知道了要
//获取文件路径,一般是getPath()方法,但是InputSplit类是一个父类,没有实现该方法,所以找其子类,看哪个有getPath()方法。 inputSplit = (FileSplit) context.getInputSplit(); }
然后在map方法中,实现读取实现并封装数据,但是有些数据是没有值的,是空参。比如当读取order表时,pid作为K,此时pname是没有值的。怎么办?要注意因为这些字段都实现了序列化和反序列化,所以是不能存在空参的,否则会报错。怎么办呢?对于string类型,可以传递一个空字符串,即此时pname=""。如果是基本数据类型,怎么办?如果赋值后,对最终的结果没有影响,那么可以随便赋值。就是不能传递空参。
另一个就是在封装数据时,如果数据来自order表,那么title就赋值为order。便于在reduce方法中,对数据进行解析分离。
3.在reduce类中,由mapper传递过来的数据,已经是按照相同的K对应的values数据,如pid对应着order表和product表的数据,相同的K在order有多条数据,而product只有1条。因为product表对order表是1对多的关系,待会对数据进行存储时,多的表就需要用集合来存储,而1的表就只需用原来的数据结构去存储数据。所以我们创建list集合来存储order的数据,创建bean对象来存储product的数据。如对于pid为1的,此时作为K,那么它对应的values有三个,两个是order表的,一个是product表的。
所以在reduce方法中,先对数据进行分离,并存储到各自的对象中。这里有一个问题需要注意,就是Hadoop为了节省资源,对于同一对象只会新建一次对象,后面如果传递了新的值,只会覆盖前面的值。而集合的值又是引用其他对象的,所以必须每次传递一个对象前都新建一次对象。
@Override protected void reduce(IntWritable key, Iterable<tableBean> values, Context context) throws IOException, InterruptedException { for (tableBean value : values) { //来自order表 if (value.getTitle().equals("order")){ //创建一个临时TableBean对象接收value,原因是Hadoop对于一个对象只能new一次, // 即后面的值会覆盖前面的值,而集合的值是引用值,就会造成所有的值都一样 tableBean temBean = new tableBean(); try { //使用工具类将value传递给temBean BeanUtils.copyProperties(temBean,value); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } //将临时表添加到order集合中 orderList.add(temBean); }else{ //来自pd表 try { //使用工具类将value传递给pdBean BeanUtils.copyProperties(pdBeans,value); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } } }
对数据进行分离后,此时order表中就只差name了,对于order和pd来说,他们的K是一样的,因为在同一个reduce方法中。
//key是pid,此时就可以为order表设置name了 for (tableBean ol : orderList) { ol.setName(pdBeans.getName()); context.write(ol,NullWritable.get()); } //因为reduce()使用后,会继续调用其他的KV对,所以必须清空list集合 orderList.clear();
4.driver中配置各类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号