MapReduce中inputformat的切片、partition分区、outputformat的输出
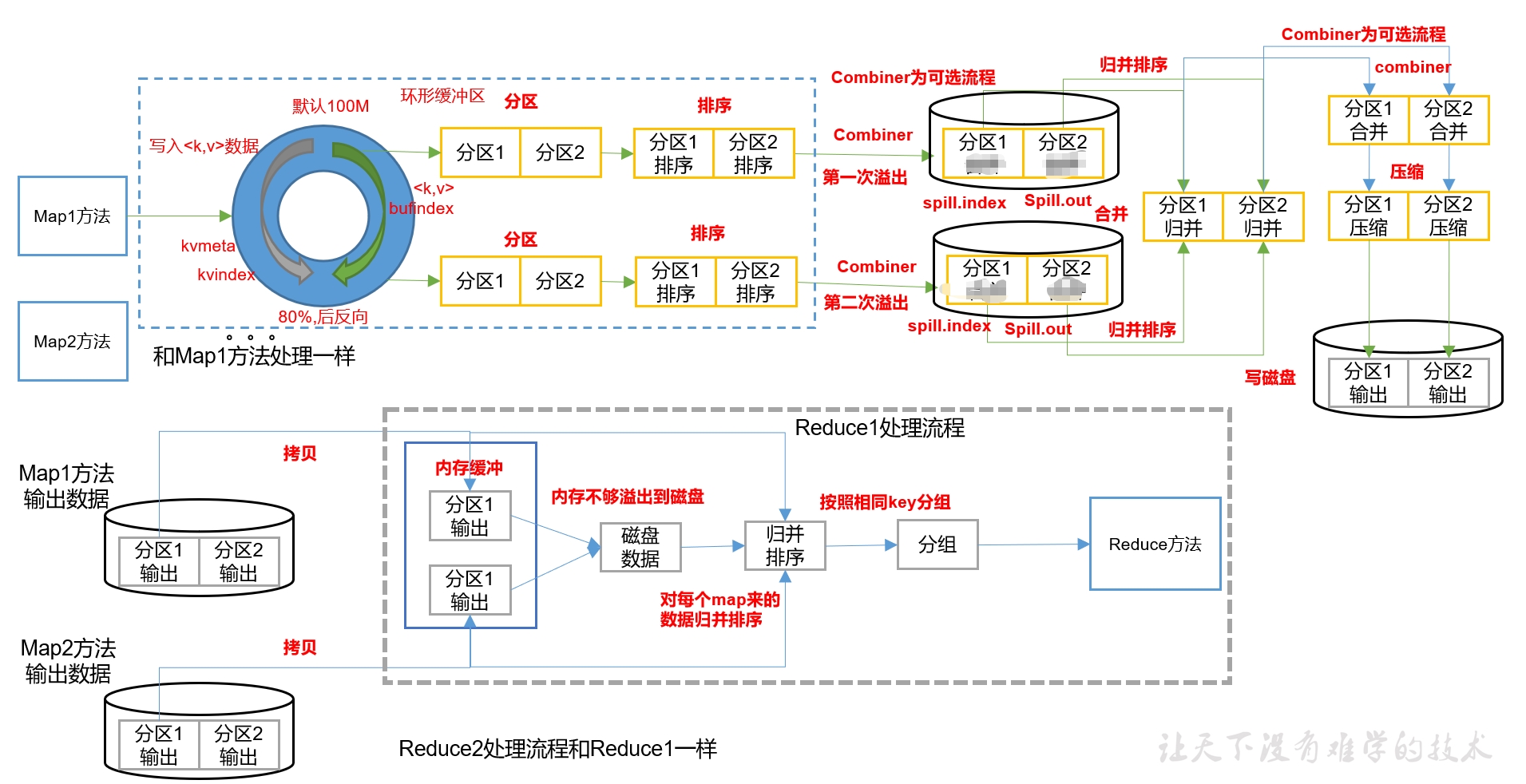
map输出KV后,会存储到环形缓冲区(内存)中,然后分继续分区、排序(区内),达到80%的阀值后,会溢出到磁盘中,一个mapTask可能会溢写为几个文件,如果有多个文件,那么在磁盘中还会按照相同的分区编号进行归并(如来自不同溢出文件的分区1和分区1进行归并);然后这时有一个可选流程,即对分区内的KV对进行combiner,原理是相同的K的V进行合并,如a 1,a 1,a 1合并为a 3。其实就是后面reduce的所做的事,只不过这里是对区内进行合并,而后面的reduce是对不同的mapTask的KV对进行合并。接下来还有一个可选流程,即对分区进行压缩,最后输出在磁盘中是一个mapTask就是只有一个输出文件。注意这里的combiner其实如果自定义的话,是继承Reducer类,因为原理就是和reduce一样。
reduceTask会拷贝磁盘中的map的输出数据到内存中,内存不够会溢出到磁盘中,按照一个分区编号执行一个reduceTask任务的规则,reduceTask对同一编号的分区进行归并、排序,然后按照相同的key进行分组,传递给reducer方
本次思路都是从尚硅谷得来的:
1.1 切片
-- ① 切片的概念:从文件的逻辑上的进行大小的切分,一个切片多大,将来一个MapTask的处理的数据就多大。
-- ② 一个切片就会产生一个MapTask
-- ③ 切片时只考虑文件本身,不考虑数据的整体集。
-- ④ 切片大小和切块大小默认是一致的,这样设计目的为了避免将来切片读取数据的时候有跨机器的情况
1.2 InputFormat的体系结构
-- FileInputFormat InputFormat的子实现类,实现切片逻辑,实现了getSplits() 负责切片
-- TextInputFormat FileInputFormat的子实现类, 实现读取数据的逻辑createRecordReader() 返回一个RecordReader,在RecordReader中实现了读取数据的方式:安行读取。
-- CombineFileInputFormat FileInputFormat的子实现类,此类中也实现了一套切片逻辑 (处理:适用于小文件计算场景)
CombineTextInputFormat是CombineFileInputFormat的实现类,只需在driver类中进行改进就可以了
// 如果不设置InputFormat,它默认用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置4m CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
2.自定义分区可以对K或V进行分区(和排序不一样,排序对象只能作为map输出类型的K值)
2.1 分为多少个区是在提交job任务时就已经确定的(通过确定reduceTask的个数),而一对KV输出到哪个区中是在map输出到环形缓冲区中(即内存中)实现的,默认的分区规则是通过KV对中的K的hashCode值除以分区的个数得到的余数来确定的,如分区个数为2,那么hashCode/2的余数为0或1。
自定义分区规则(如:对字母前缀a-q的分为0区,其余的分到1区),可通过实现
org.apache.hadoop.mapreduce.Partitioner 该类,并重写里面的getPartition()方法
注意,Partitioner的后面的数据类型和map输出的类型保持一致,因为分区的KV数据就是map输出的KV数据
public class FlowPartition extends Partitioner<Text,FlowBean>{}
2.2 然后在driver类中,进行配置
//设置ReduceTask数量 job.setNumReduceTasks(4); //设置分区自定义实现类 job.setPartitionerClass(FlowPartition.class);
2.3 要查看partition的分区实现过程源码,可以在mapTask类中查看
3. 排序有两种方式:
排序在mapTask和reduceTask任务中都有(当存在分区时,reduceTask需要对来自不同mapTask的同一分区编码的KV对进行归并且按照K进行排序;而mapTask在环形缓冲区中就会在同一分区中按照K进行排序了)。
第一种:MapReduce中默认的排序是按照字典顺序,所以如果需要自定义排序规则,一要排序的对象必须实现writableComparable接口;二需要自定义一个类继承writableComparator并指定当前比较器对象为谁服务,即使用构造方法调用super传递要排序的对象的类对象;三就是在driver类中配置自定义的排序类。
一:要排序的对象必须继承writableComparable接口
public class flowBeans implements WritableComparable<flowBeans> { private Integer upFlow; private Integer downFlow; private Integer totalFlow; //实现compare方法 public int compareTo(flowBeans o) { return -this.getTotalFlow().compareTo(o.getTotalFlow()); } //实现序列化 public void write(DataOutput out) throws IOException { out.writeInt(upFlow); out.writeInt(downFlow); out.writeInt(totalFlow); } //实现反序列化,注意反序列化的顺序必须与序列化的顺序保持一致且序列化时如果是用writeInt,那么反序列化只能用readInt,不能用read public void readFields(DataInput in) throws IOException { upFlow = in.readInt(); downFlow = in.readInt(); totalFlow = in.readInt(); } @Override public String toString() { return upFlow + " " + downFlow + " " + totalFlow ; } //因为是私有变量,外部无法直接获取,只能通过set和get方法来设置和获取私有变量 public Integer getUpFlow() { return upFlow; } public void setUpFlow(Integer upFlow) { this.upFlow = upFlow; } public Integer getDownFlow() { return downFlow; } public void setDownFlow(Integer downFlow) { this.downFlow = downFlow; } public Integer getTotalFlow() { return totalFlow; } public void setTotalFlow(Integer totalFlow) { this.totalFlow = totalFlow; } }
二:自定义一个比较器类,类中可以重写上面的compare()方法,如果重写了,那么就会覆盖上面的compare()方法
public class flowWritable extends WritableComparator { //指定当前比较器对象为谁服务 public flowWritable(){ //调用super的前提是flowBeans必须继承writableComparable接口,点击super进去就可以看源码 super(flowBeans.class,true); } //重写compare方法,这里可以不写,如果不写的话,那么这个比较器调用的就是上面的flowBeans对象在继承 //writableComparable接口时所实现的compare方法。但是如果这里重写了compare()方法,那么会覆盖掉原来的compare()方法。 @Override public int compare(WritableComparable a, WritableComparable b) { flowBeans aBean = (flowBeans) a; flowBeans bBean = (flowBeans) b; return aBean.getTotalFlow().compareTo(bBean.getTotalFlow()); } }
三:在driver类中配置比较器
//配置比较器 job.setSortComparatorClass(flowWritable.class);
第二种就是直接继承writableComparable接口就可以,不用再实现writableComparator类。用这种方式,hadoop会为该对象创建一个比较器,也就是上面的第二步。
4.可选流程combiner(分区内合并具有相同K的V),这里的combiner和inputformat中的combineTextInputFormat不要混淆了
4.1 好处是减少网络传输的字节数,提高效率。但是也有限制条件,即分区内合并的结果不影响最终的结果。比如要统计平均数,那就不可以用combiner了,因为在分区内对具体相同K的V进行合并后,平均数的分母变小,会改变最终的值。
4.2 实现过程,虽然叫combiner,但是由于原理和reduce一样,都是对相同K的V进行操作,所以其实自定义combiner类时,继承的是Reducer类,实现reduce()方法。而且这里的reduce()方法和我们在reducer类中写的reduce()方法是一模一样的。
第一:自定义一个类实现Reducer类
//这里的四个类型和reducer类的四个类型是保持一致的 public class WordCountCombiner extends Reducer<Text, IntWritable,Text,IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //实现的代码和reducer类中的reduce方法是一样的 } }
第二:在driver类中配置combiner类
//配置combiner类 job.setCombinerClass(WordCountCombiner.class);
4.3 使用的效果,减少网络传输的字节数

5.outputformat,自定义输出格式
-
FileOutputFormat是outputFormat子实现类,而FileOutputFormat中的RecordWriter()是一个抽象方法,我们在继承FileOutputFormat类后,就需要重写该方法。
案例:若要实现字段中有atguigu的输出到atguigu.txt文件,而不包括atguigu的输出到other.txt文件
第一:自定义outputformat类继承FileOutputFormat类,重写里面的方法
//类型和reducer的输出类型保持一致 public class logOutputFormat extends FileOutputFormat<Text, NullWritable> { //可以看到,返回类型是RecordWriter,所以我们必须自定义一个RecordWriter类 public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException { logRecordWriter lrw = new logRecordWriter(job);//必须把job对象传递过去 return lrw; } }
第二:可以看到,还需要自定义一个RecordWriter类,在该类中实现具体的业务逻辑
public class logRecordWriter extends RecordWriter<Text, NullWritable> { private String atguiguPath = "F:\\Program Files\\hadoop-projects\\out\\atguigu.txt"; private String otherPath = "F:\\Program Files\\hadoop-projects\\out\\other.txt"; private FSDataOutputStream atguiguOut; private FSDataOutputStream otherOut; //有参构造方法 public logRecordWriter(TaskAttemptContext job) throws IOException { //获取文件系统对象 FileSystem fs = FileSystem.get(job.getConfiguration()); //用文件系统对象创建两个输出流对应不同的目录 atguiguOut = fs.create(new Path(atguiguPath)); otherOut = fs.create(new Path(otherPath)); } //实现具体的输出逻辑 public void write(Text key, NullWritable value) throws IOException, InterruptedException { String log = key.toString(); if (log.contains("atguigu")){ atguiguOut.writeBytes(log + "\n"); }else{ otherOut.writeBytes(log+ "\n"); } } //关闭资源 public void close(TaskAttemptContext context) throws IOException, InterruptedException { //使用Hadoop提供的工具类去关闭资源 IOUtils.closeStream(atguiguOut); IOUtils.closeStream(otherOut); } }
第三:在driver类中配置
//配置自定义outputformat类 job.setOutputFormatClass(logOutputFormat.class);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号