Hadoop框架
1.
在Hadoop1.0版本中,Hadoop是有许多缺点的。比如,迭代计算效率低下,因为每一次map和reduce前,会读取hdfs中的数据,然后本次执行完毕后,会把数据存储到hdfs中,反复读取hdfs中的数据,降低了迭代计算的效率。所以在Hadoop2.0后,就有了spark,它是基于内存的分布式并行编程框架,具有较高的实时性,能更好的支持迭代计算。
在1.0中,HDFS中有名称节点(NameNode),负责存储元数据的信息,即负责管理文件系统的命名空间和客户端对文件的访问。还有第二名称节点(SecondaryNamenode),周期的读取NameNode中的镜像文件(FsImage)和修改日志(EditLog),把两个文件合并为一个,并发送给NameNode,用于替换掉原来的FsImage,避免EditLog过大,在NameNode失败进行恢复时销毁过多的时间。合并后的命名空间镜像文件 FsImage 在第二名称节点中也保存一份,当名称节 点失效的时候,它首先会把自己的 FsImage 和 EditLog 进行恢复,如果自己的 FsImage 发生丢失,还可以使用第二名称节点中的 FsImage 进行恢复。
由于第二名称节点无法提供“热备份”的功能,即在名称节点发生失效时,系统无法借助第二名称节点继续提供对外服务,仍然需要进行停机恢复,因此1.0中HDFS是存在“单点故障问题”的。
为了解决HDFS1.0中的单点故障问题,2.0中引入了HDFS HA(high aailability)架构。典型的HA架构,包含两个名称节点,一个处于“活跃状态”负责管理客户端对文件的访问,另一个处于“待命状态”,作为活跃名称节点的备份。二者通过共享存储系统,实现数据的同步,一般使用zookeeper。
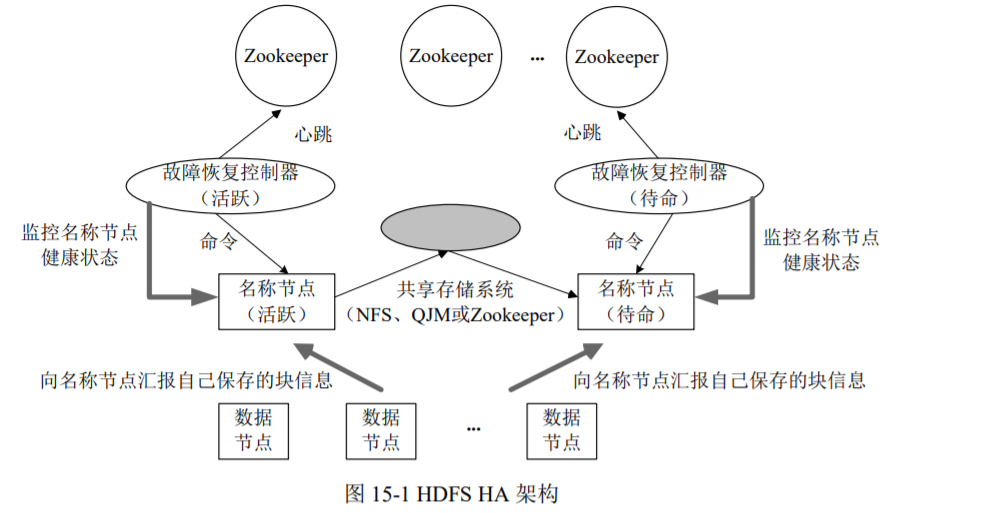
HDFS1.0中单名称节点的设计,不仅存在单点故障问题,还存在可拓展性、性能、隔离性等问题。HDFS HA 虽然提供了 两个名称节点,但是,在某个时刻,也只会有一个名称节点处于活跃状态,另一个则处于待命状态,因而,HDFS HA 在本质上还是单名称节点,只是通过“热备份”设计方式解决了单点故障问题,并没有解决可扩展性、系统性能和隔离性等三个方面的问题。
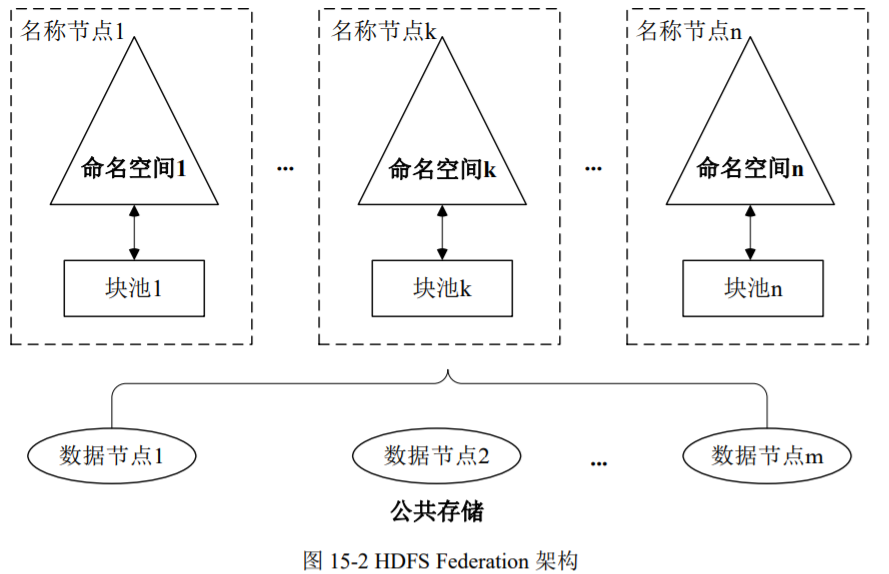
HDFS2.0引入了HDFS Federation机制,设计多个相互独立的名称节点,各个名称节点负责运行各自的命名空间和块管理。名称节点共享底层的所有数据节点,即一个数据节点会为多个块池存储块,当一个名称节点失效时,也不会影响到与它相关的数据节点继续为其他名称节点提供服务。
联系实际,可以这么理解:把名称节点比喻房产中介,以前只有一个中介,当中介跑路了,我们(客户端)就无法请求关于房子的信息(存储在DataNode中的数据);而现在有多个中介了,即使一个跑路了,那么还有其他的中介,我们还可以访问到想要的信息。
YARN(yet another resources negotiator)的诞生
Mar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号