【论文精读】PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume (2018 CVPR) 光流估计
title: PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume date: 2023-05-11 14:24:44 tags: 论文精读 光流估计
|
作者 |
Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz |
|
单位 |
NVIDIA |
|
代码 |
https://github.com/NVlabs/PWC-Net |
|
期刊/会议 |
CVPR |
|
关键词 |
2018 |
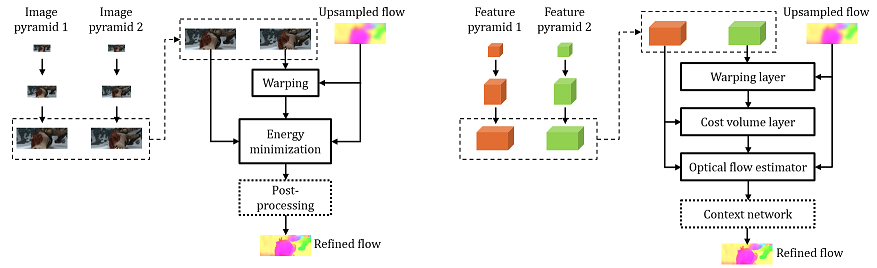
PWC-Net fuses several classic optical flow estimation techniques, including image pyramid, warping, and cost volume, in an end-to-end trainable deep neural networks for achieving state-of-the-art results.
PWC-Net融合了很多经典的光流估计技术,包括图像金字塔,warping,代价空间,融合成为一个端到端可训练深度网络模型,同时达到了SOFT效果。
0.摘要
- 问题:
光流估计是一个核心的计算机视觉问题。基于能量函数的方法对于实时应用来说计算量太大。
- 工作内容:
我们提出了一个紧凑但有效的光流CNN模型,称为PWC-Net。PWC-Net是根据简单而完善的原则设计的:pyramidal processing, warping, and the use of a cost volume。在可学习的特征金字塔中,PWC-Net使用当前光流估计来warping第二幅图像的CNN特征。然后,它使用warping的特征和第一图像的特征来构建代价空间,该代价空间由CNN处理以估计光流。
- 效果:
PWCNet的尺寸是最近的FlowNet2型号的17倍,更容易训练。此外,它在MPI Sintel最终通过和KITTI 2015基准测试上的性能优于所有已发表的光流方法,在Sintel分辨率(1024×436)图像上以约35帧/秒的速度运行。
1. Introduction
图3总结了PWC-Net的关键组件。
(1)首先,由于原始图像随阴影和照明变化而变化[9,45],我们用可学习的特征金字塔替换固定的图像金字塔。
(2)其次,我们将传统方法中的扭曲操作(warping)作为网络中的一层来估计大运动。
(3)第三,由于成本体积比原始图像更能区分光流,我们的网络有一个层来构建成本体积,然后由CNN层处理以估计流量。翘曲和成本体积层没有可学习的参数,并减小了模型尺寸。
(4)最后,传统方法的常见做法是使用上下文信息对光流进行后处理,如中值滤波[49]和双边滤波[54]。因此,PWC-Net使用上下文网络来利用上下文信息来细化光流。与能量最小化相比,翘曲、成本体积和CNN层在计算上更轻。
接下来,我们将解释每个组件的主要思想,包括金字塔特征提取器、光流估计器和上下文网络。
2. Method
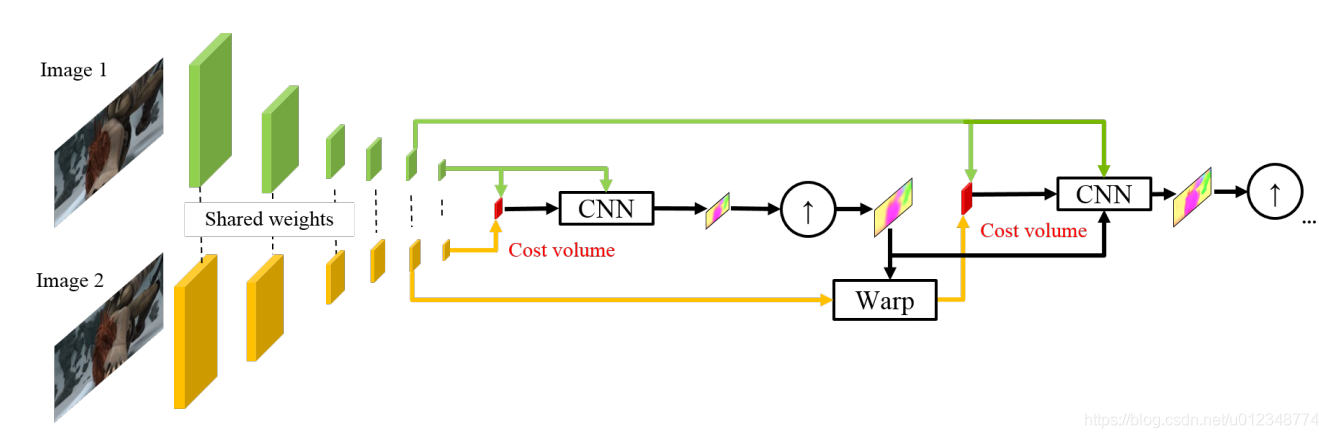
3.1. 特征金字塔提取器
给定两个输入图像I1和I2,我们生成L级特征表示金字塔,底部(第零级)为输入图像,即c0t=It。为了在第L层clt生成特征表示,我们使用多层卷积滤波器将第L−1个金字塔级cl-1t的特征下采样2倍。从第一级到第六级,特征通道的数量分别为16、32、64、96、128和196。
3.2 warping层。
在第l级,我们使用第l+1级的×2上采样流将第二个图像的特征向第一个图像warping:
![]()
其中x是像素索引,并且上采样的流up2(wl+1)在顶层被设置为零。我们使用双线性插值来实现扭曲warping操作,并根据[24,25]计算输入CNN特征和反向传播流的梯度。对于非翻译运动,扭曲warping可以补偿一些几何失真,并将图像块放在适当的尺度上。
3.3 Cost volume layer
我们将匹配成本定义为第一图像的特征和第二图像的扭曲特征之间的相关性
![]()
其中T是转置运算符,N是列向量cl1(x1)的长度。对于L级金字塔设置,我们只需要计算d个像素范围有限的部分成本体积,即|x1−x2|∞≤d。顶层的一个像素运动对应于全分辨率图像的2L−1个像素。因此,我们可以将d设置为较小。3D成本体积的尺寸为d2×H1×W1,其中H1和W1分别表示第三个金字塔级别的高度和宽度。
3.4 Optical flow estimator.
这是一个多层CNN。其输入是成本体积、第一图像的特征和上采样光流,其输出是第三级的流wl。
每个卷积层的特征通道的数量分别为128、128、96、64和32,在所有金字塔级别上保持固定。不同级别的估计量有自己的参数,而不是共享相同的参数。重复该估计过程,直到达到期望的水平l0。
使用DenseNet连接来增强估计器架构[22]。每个卷积层的输入是其前一层的输出和输入。DenseNet比传统层具有更多的直接连接,并导致图像分类的显著改进。我们将这个想法用于密流预测。
3.5 Context network
上下文网络是一种前馈CNN,其设计基于扩张卷积[57]。它由7个卷积层组成。每个卷积层的空间核是3×3。这些层具有不同的膨胀常数。具有膨胀常数的卷积层意味着该层中滤波器的输入单元在垂直和水平方向上与该层中的滤波器的其他输入单元相距k个单位。具有大膨胀常数的卷积层扩大了每个输出单元的感受野,而不会产生大的计算负担。从下到上,膨胀常数分别为1、2、4、8、16、1和1。
3.6 Training loss
设θ是我们最终网络中所有可学习参数的集合,包括不同金字塔级别的特征金字塔提取器和光流估计器(翘曲层和成本体积层没有可学习参数)。设wlθ表示网络预测的第l个金字塔级的流场,wlGT表示相应的监督信号。我们使用FlowNet[15]中提出的相同多尺度训练损失

对于微调,我们使用以下鲁棒训练损失:
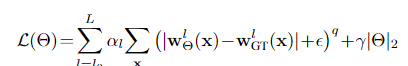
其中|·|表示L1范数,q<1对异常值的惩罚较小,并且ǫ是一个小常数。
不同分辨率特征进入 refine_block的迭代:
输入:本层特征、本层代价、上层特征、上层预测光流(第0层只有本层代价)
输出:本层特征、本层预测光流
warp5 = self.warp(c25, up_flow6*0.625)
corr5 = self.corr(c15, warp5)
corr5 = self.leakyRELU(corr5)
x = torch.cat((corr5, c15, up_flow6, up_feat6), 1)
x = torch.cat((self.conv5_0(x), x),1)
x = torch.cat((self.conv5_1(x), x),1)
x = torch.cat((self.conv5_2(x), x),1)
x = torch.cat((self.conv5_3(x), x),1)
x = torch.cat((self.conv5_4(x), x),1)
flow5 = self.predict_flow5(x)
up_flow5 = self.deconv5(flow5)
up_feat5 = self.upfeat5(x)
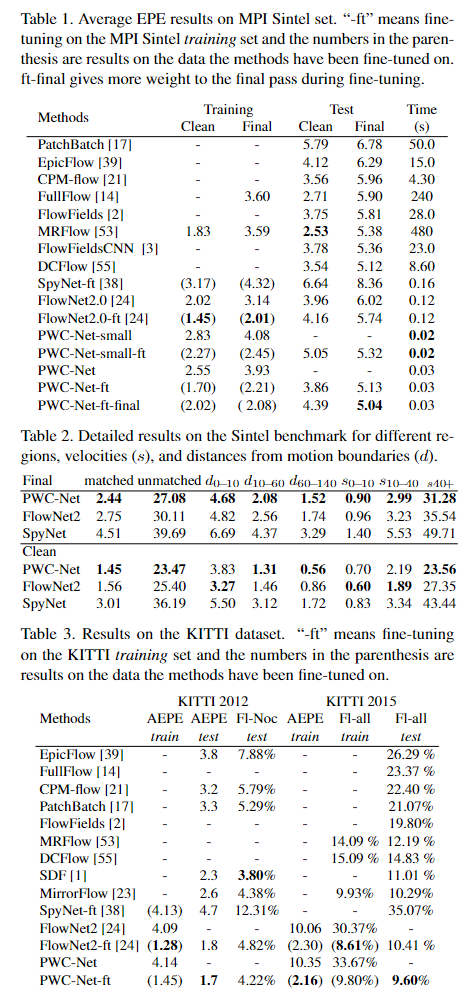
5. Experiments

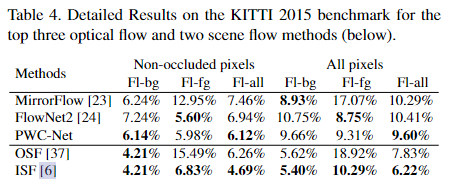
6. Conclusion
我们使用简单而成熟的原理开发了一个紧凑但有效的光流CNN模型:金字塔处理、翘曲和成本体积的使用。将深度学习与领域知识相结合,不仅减小了模型大小,而且提高了性能。PWC-Net的大小大约是FlowNet2的17倍,推理速度快2倍,并且更容易训练。在Sintel最终通过和KITTI 2015基准测试中,它优于迄今为止所有已发表的光流方法,在Sintel分辨率(1024×436)图像上以约35帧/秒的速度运行。鉴于PWC-Net的紧凑性、效率和有效性,我们预计它将成为许多视频处理系统的有用组件。
------------
参考:
1.https://github.com/NVlabs/PWC-Net/
2.http://t.csdn.cn/REQnf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号