【论文阅读】LoFTR: Detector-Free Local Feature Matching with Transformers
文献一:LoFTR: Detector-Free Local Feature Matching with Transformers
|
作者 |
Jiaming Sun1,2∗Zehong Shen1∗Yuang Wang1∗Hujun Bao1 Xiaowei Zhou1† |
|
单位 |
商汤&浙大(Zhejiang University & SenseTime Research) |
|
代码 |
https://github.com/zju3dv/LoFTR |
|
期刊/会议 |
CVPR2021 |
|
关键词 |
detector-free, local feature matching |
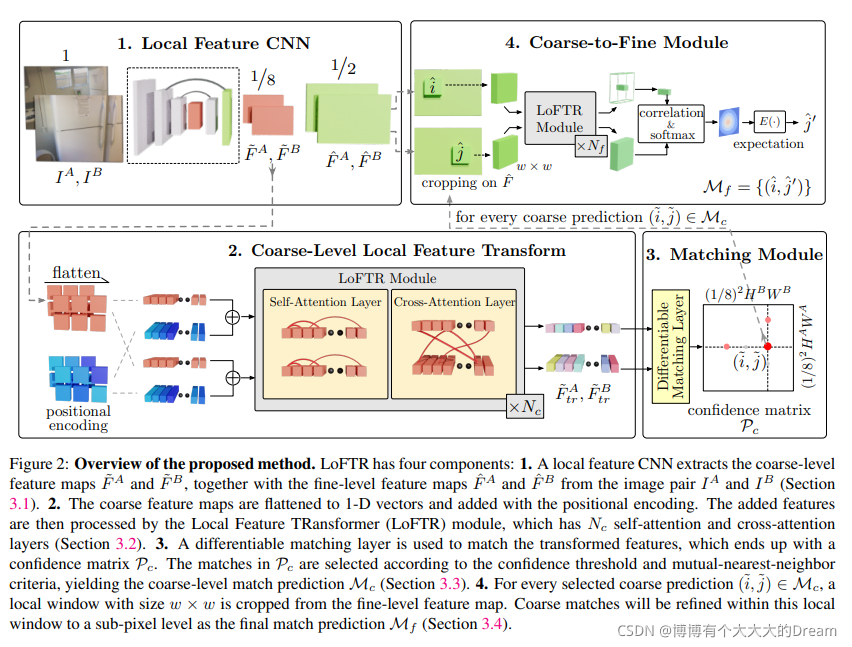
### 结论及创新点:
我们提出了Local Feature TRansformer(LoFTR),一种新的无特征检测器局部特征匹配方法。
- 受开创性工作SuperGlue[37]的启发,我们使用带有自我和交叉注意层的Transformer[48]来处理(转换)从卷积主干提取的密集局部特征。
- 首先以低特征分辨率(图像维度的1/8)在两组变换特征之间提取密集匹配。从这些密集匹配中选择具有高置信度的匹配,然后使用基于相关性的方法将其细化到亚像素级。
- Transformer的全局感受野和位置编码使变换后的特征表示具有上下文和位置依赖性。
通过多次交错自我和交叉注意层,LoFTR学习在ground-truth匹配中显示的密度范围内的全局一致匹配先验。还采用了线性Transformer,将计算复杂度降低到可管理的水平。
### 阅读笔记
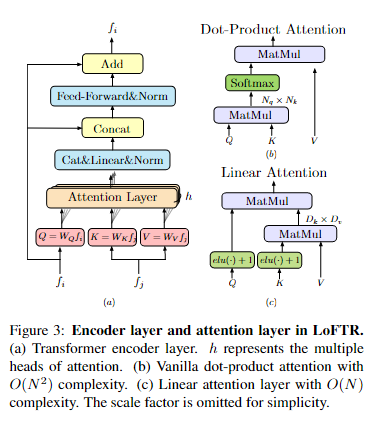
#### 3 Methods
给定图像对 ,局部特征匹配时候,现存的方法使用一个特征提取器去提取关键兴趣点points。我们设计的detector-free方法可以处理重复特征提取器的问题。
,局部特征匹配时候,现存的方法使用一个特征提取器去提取关键兴趣点points。我们设计的detector-free方法可以处理重复特征提取器的问题。
##### 3.1 Local Feature Extraction
论文使用FPN设计了一个标准的卷积网络架构从两个图片中提取多层级的特征。使用 表示在原始图像1/8维度处的粗粒度特征表示,
表示在原始图像1/8维度处的粗粒度特征表示,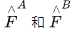 表示在原始图像1/2维度处的细粒度特征表示。
表示在原始图像1/2维度处的细粒度特征表示。
传统的卷积神经网络CNN具有平移不变性和局部性的归纳偏差,非常适合局部特征提取。CNN引入的下采样也减少了LoFTR模块的输入长度,这对于确保可控的计算成本至关重要。
##### 3.2 Local Feature Transformer Module
通过卷积提取后的特征会被送入LoFTR模块来提取位置特征和上下文依赖的局部特征。简而言之,LoFTR模块把“特征”转换成“易于匹配的特征”。我们把这个特征表示为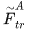 和
和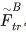 。
。
。。。。。。。。
Transformer背景介绍(此处省略部分)
Linear Transformer:
计算复杂度从O(N2)减少至O(N)
。。。。。。。。。。
##### 3.3 Establishing Coarse-level Matches
LoFTR中应用了两种可微的匹配层,一种是optimal transport OT层,另一种是dual-softmax operator。
首先计算两个转换的特征之间的得分矩阵S,
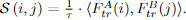 。
。
当使用OT时,可以用[37]中的代价矩阵。还可以将softmax用在两个维度上来获得最近邻匹配的概率。
当时用dual-softmax时候,匹配概率矩阵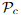 可以通过以下方式计算得到:
可以通过以下方式计算得到:
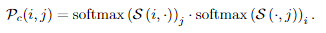
Match Selection. 基于置信度概率矩阵,来根据是否超过阈值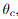 来选择匹配的,然后进一步使用最近邻mutual nearest neighborMNN,来过滤掉可能异常的粗匹配。我们把这个粗粒度匹配预测表示为:
来选择匹配的,然后进一步使用最近邻mutual nearest neighborMNN,来过滤掉可能异常的粗匹配。我们把这个粗粒度匹配预测表示为:
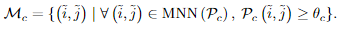
##### 3.4. Coarse-to-Fine Module
在建立粗略匹配之后,这些匹配通过coarse-tofine模块细化到原始图像分辨率。
受[50]的启发,我们为此使用了基于相关性的方法。对于每一个粗匹配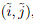 ,我们首先在精细级别的特征图中定位其位置。然后,然后裁剪两组大小为w×w的局部窗口。一个较小的LoFTR模块将每个窗口内的裁剪特征变换Nf次,产生两个变换后的局部特征图
,我们首先在精细级别的特征图中定位其位置。然后,然后裁剪两组大小为w×w的局部窗口。一个较小的LoFTR模块将每个窗口内的裁剪特征变换Nf次,产生两个变换后的局部特征图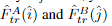 ,分别以i和j为中心。我们将
,分别以i和j为中心。我们将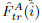 的中心向量与
的中心向量与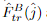 中的所有向量相关联,从而生成热图,该热图表示在j的邻域中的每个像素与i的匹配概率。通过计算概率分布上的期望值,我们在
中的所有向量相关联,从而生成热图,该热图表示在j的邻域中的每个像素与i的匹配概率。通过计算概率分布上的期望值,我们在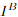 上获得具有亚像素精度的最终位置。收集所有匹配
上获得具有亚像素精度的最终位置。收集所有匹配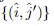 产生最终精细级别匹配
产生最终精细级别匹配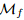 。
。
3.5. Supervision
最终损失包括粗粒层coarse-level和细粒层fine-level的损失:
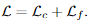
Coarse-level Supervision。粗略级别的损失函数是由最优传输层或双softmax算子返回的置信矩阵Pc上的负对数似然损失。我们遵循SuperGlue[37],在训练期间使用相机姿势和深度图来计算置信矩阵的地面真实标签。我们将ground-truth 粗糙匹配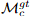 定义为两组1/8分辨率网格的相互最近邻结果。两个栅格之间的距离通过其中心位置的重新投影距离来测量。补充资料提供了更多详情。对于最佳传输层,我们使用与[37]中相同的损耗公式。当使用双softmax进行匹配时,我们最小化了中网格的负对数似然损失:
定义为两组1/8分辨率网格的相互最近邻结果。两个栅格之间的距离通过其中心位置的重新投影距离来测量。补充资料提供了更多详情。对于最佳传输层,我们使用与[37]中相同的损耗公式。当使用双softmax进行匹配时,我们最小化了中网格的负对数似然损失:
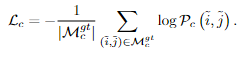
Fine-level Supervision.。我们使用l2损失进行精细级别细化。根据[50],对于每个查询点i,我们还通过计算相应热图的总方差σ2(i)来测量其不确定性。目标是优化具有低不确定性的精确位置,从而得到最终加权损失函数:
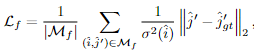

3.6. Implementation Details
我们在ScanNet[7]数据集上训练LoFTR的室内模型,在MegaDepth[21]上训练室外模型[37]。在ScanNet上,使用Adam训练模型,初始学习率为1×10−3,批量大小为64。它在64个GTX 1080Ti GPU上训练24小时后收敛。特征提取CNN使用ResNet-18[12]的修改版本作为backbone。使用随机初始化的权重对整个模型进行端到端训练。Nc设置为4,Nf为1。θc选择为0.2。窗口大小w等于5。
在通过实现中的精细级别LoFTR之前,对和进行上采样,并与连接。RTX 2080Ti上640×480图像对的dual-softmax匹配全模型运行时间为116毫秒。在最佳传输设置下,我们使用三次sinkhorn迭代,模型运行时间为130毫秒。(更多训练和时间分析的细节,请读者参考补充材料。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号