volatile关键字
volatile关键字作用域
volatile关键字只能修饰类变量和实例变量,对于方法参数、局部变量以及实例常量,类常量都不能进行修饰!
volatile写/读的内存语义
public class ReorderExample {
private int x = 0;
private int y = 1;
private volatile boolean flag = false;
public void writer(){
x = 42; // 1
y = 50; // 2
flag = true; // 3
}
public void reader(){
if (flag){ // 4
System.out.println("x:" + x); // 5
System.out.println("y:" + y); // 6
}
}
}
- 根据JMM,当线程A执行writer方法时,线程A将本地内存更改的变量写回到主内存中:
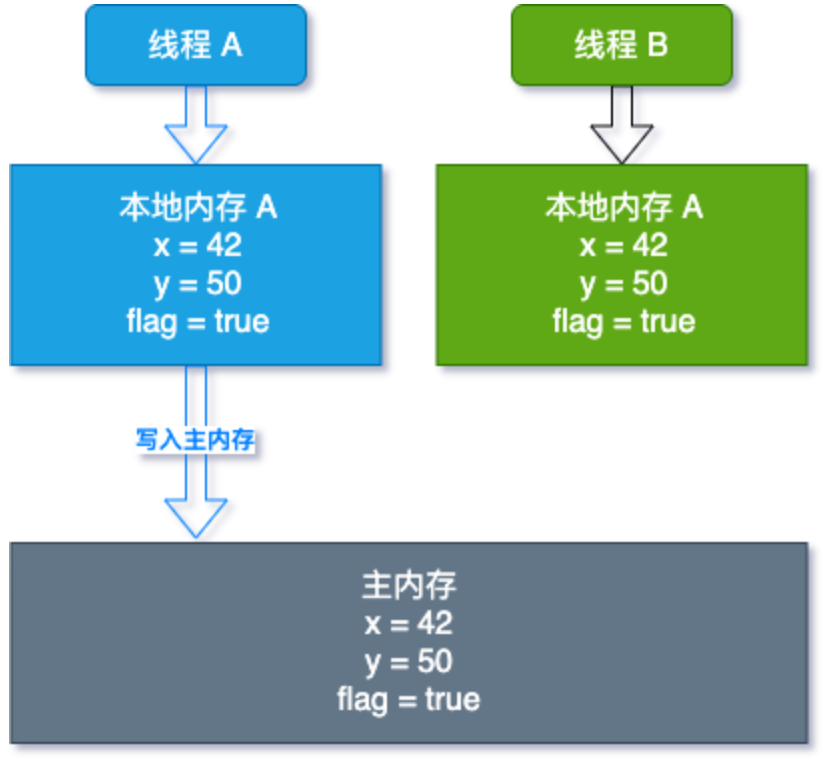
- volatile读的内存语义:当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
所以当线程B执行reader方法时:
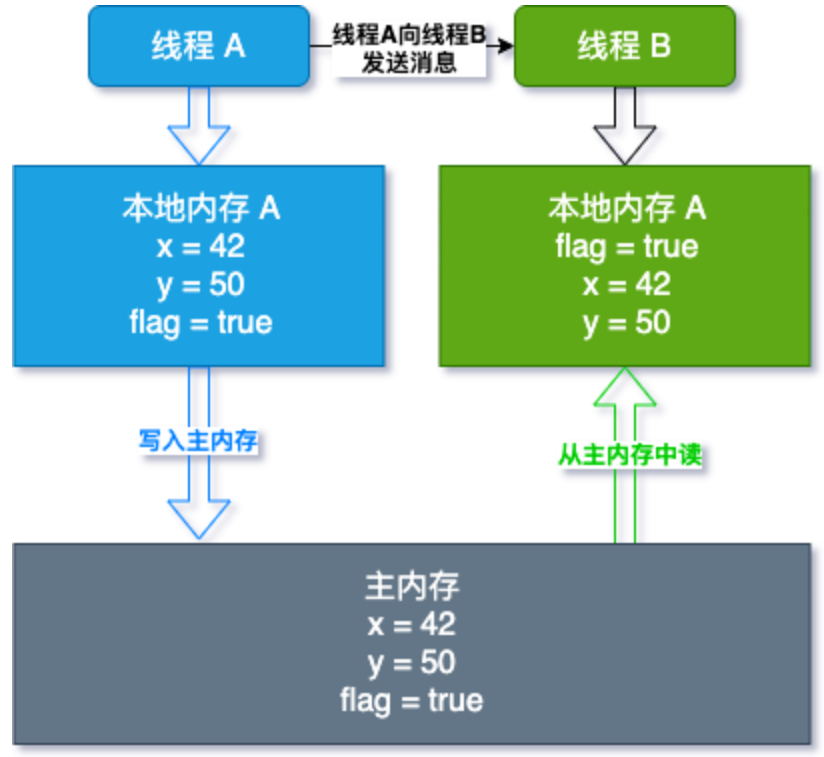
线程B本地内存变量无效,从主内存中读取变量到本地内存中,也就得到了线程A更改后的结果,这就是volatile是如何保证可见性的!
即:
- 线程A写一个volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所做修改的)消息。
- 线程B读一个volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。
- 线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
synchronized与volatile区别
| 区别 | synchronized | volatile |
|---|---|---|
| 内存语义有相同的内存效果 | 释放-获取 |
写-读 |
| 本质 | synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住 | 告诉Jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取 |
| 适用范围 | 以使用在变量、方法、和类级别 | 只能修饰类变量和实例变量 |
| 三特性 | 可以保证变量的修改可见性、有序性和原子性——synchronized关键字保证同一时刻只允许一条线程操作,可以避免指令重排的影响! |
仅能实现变量的修改可见性以及有序性(禁止重排),不能保证原子性 |
| 阻塞 | 会造成线程的阻塞 | 不会造成线程的阻塞 |
| 编译器优化 | synchronized标记的变量可以被编译器优化 | 标记的变量不会被编译器优化(禁止重排) |
volatile应用场景
-
如果写入变量值不依赖变量当前值,那么就可以用volatile!
- synchronized是排他的,线程排队就要有切换,上下文切换会带来很大开销!且无法控制阻塞时长、阻塞不可被中断。
- volatile是非阻塞的方式,在解决共享变量可见性问题的时候,volatile就是synchronized的弱同步体现!
-
状态标志
-
一次性安全发布(
双重检查锁定:详见并发三大特性——有序性和单例模式)
在缺乏同步的情况下,可能会遇到某个对象引用的更新值(由另一个线程写入)和该对象状态的旧值同时存在。这就是造成著名的双重检查锁定(double-checked-locking)问题的根源,其中对象引用在没有同步的情况下进行读操作,产生的问题是可能会看到一个更新的引用,但是仍然会通过该引用看到不完全构造的对象。private volatile static Singleton instace; public static Singleton getInstance(){ // 第一次null检查 if(instance == null){ synchronized(Singleton.class) { // 第二次null检查 if(instance == null){ instance = new Singleton(); } } } return instance; }
Happens-Before解决可见性与有序性
- 为了解决CPU、内存、IO的短板,增加了缓存,但这导致了可见性问题
- 编译器、处理器
擅自优化(Java代码在编译后会变成 Java 字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行),导致有序性、原子性问题。
初衷是好的,但引发了新问题,最有效的办法就禁止缓存和编译优化,问题虽然能解决,但程序的性能就堪忧了!既然不能完全禁止缓存和编译优化,那就按需禁用缓存和编译优化,按需就是要加一些约束,约束中就包括了volatile,synchronized,final三个关键字,以及Happens-Before原则!
程序员基于Happpen-Befores规则编程,但JMM并没有严格遵守Happpen-Befores规则:
- 对于会改变程序执行结果的重排序,JMM要求编译器和处理器必须禁止这种重排序。
- 对于不会改变程序执行结果的重排序,JMM对编译器和处理器不做要求(JMM允许这种重排序)。
Happens-before 规则主要用来约束两个操作,两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行,happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见!
程序顺序性规则
一个线程中的每个操作happens-before于该线程中的任意后续操作
即在一个线程内必须保证语义串行性,也就是说按照代码顺序执行。
volatile变量规则
对一个volatile域的写,happens-before于任意后续对这个volatile域的读
volatile变量的写,先发生于读,这保证了volatile变量的可见性(volatile通过在volatile变量的操作前后插入内存屏障的方式,保证了变量在并发场景下的可见性和有序性),简单的理解就是,volatile变量在每次被线程访问时,都强迫从主内存中读该变量的值,而当该变量发生变化时,又会强迫将最新的值刷新到主内存,任何时刻,不同的线程总是能够看到该变量的最新值。
public class ReorderExample {
private int x = 0;
private int y = 1;
private volatile boolean flag = false;
public void writer(){
x = 42; // 1
y = 50; // 2
flag = true; // 3
}
public void reader(){
if (flag){ // 4
System.out.println("x:" + x); // 5
System.out.println("y:" + y); // 6
}
}
}
volatile的内存增强语义——JMM针对编译器定制的volatile重排序的规则:
| 能否重排序 | 第二个操作 | 第二个操作 | 第二个操作 |
|---|---|---|---|
| 第一个操作 | 普通读/写 | volatile读 | volatile写 |
| 普通读/写 | - | - | NO |
| volatile读 | NO | NO | NO |
| volatile写 | - | NO | NO |
从这个表格最后一列可以看出:
如果第二个操作为volatile写,不管第一个操作是什么,都不能重排序,这就确保了volatile写之前的操作不会被重排序到volatile写之后。
代码1和2不会被重排序到代码3(添加了volatile)的后面,但代码1和2可能被重排序!
从这个表格的倒数第二行可以看出:
如果第一个操作为volatile读,不管第二个操作是什么,都不能重排序,这确保了volatile读之后的操作不会被重排序到volatile读之前
代码4是读取volatile变量,代码5和6不会被重排序到代码4之前!
volatile内存语义的实现是应用到了内存屏障!
传递性规则
如果A happens-before B,且B happens-before C,那么A happens-before C
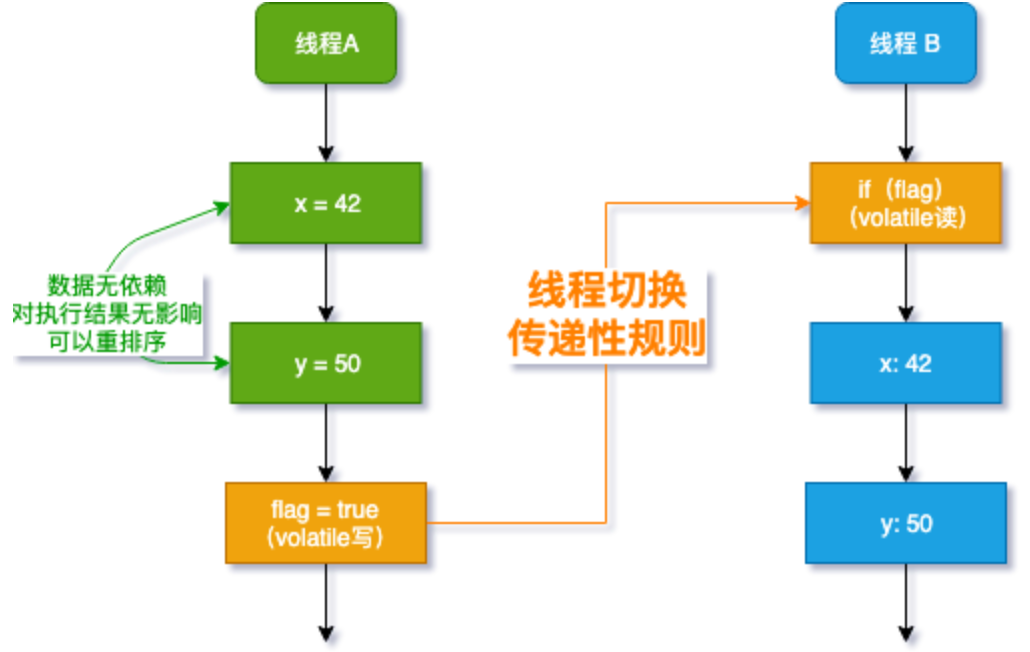
从上图可以看出:
x = 42和y = 50Happens-beforeflag = true,这是规则1- 写变量(代码 3)
flag = trueHappens-before读变量(代码4)if(flag),这是规则2
根据规则3传递性规则,x = 42Happens-before读变量if(flag)。
如果线程B读到了flag是true,那么
x = 42和y = 50对线程B就一定可见了,这就是Java1.5的增强(之前版本是可以普通变量写和volatile变量写的重排序的)
监视器锁规则
对一个锁的解锁happens-before于随后对这个锁的加锁(不会一个锁还没释放完,就开始加锁)
解锁(unlock)操作必然发生在后续的同一个锁的加锁(lock)之前,也就是说,如果对于一个锁解锁后,再加锁,那么加锁的动作必须在解锁动作之后(同一个锁)。
public class SynchronizedExample {
private int x = 0;
public void synBlock(){
// 1.加锁
synchronized (SynchronizedExample.class){
x = 1; // 对x赋值
}
// 3.解锁
}
// 1.加锁
public synchronized void synMethod(){
x = 2; // 对x赋值
}
// 3. 解锁
}
先获取锁的线程,对x赋值之后释放锁,另外一个再获取锁,一定能看到对x赋值的改动!
start()规则
如果线程A执行操作ThreadB.start() (启动线程B),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。
也就是说,主线程A启动子线程B后,子线程B能看到主线程在启动子线程B前的操作
即:如果线程A在执行线程B的start方法之前修改了共享变量的值,那么当线程B执行start方法时,线程A对共享变量的修改对线程B可见
package volatilekeyword;
/**
* 验证happens-before原则之start原则
* @author Chenzf
*/
public class StartExample {
private int x = 0;
private int y = 1;
private boolean flag = false;
public void reader() {
System.out.println("x: " + x);
System.out.println("y: " + y);
System.out.println("flag: " + flag);
}
public static void main(String[] args) {
StartExample startExample = new StartExample();
Thread thread = new Thread(startExample::reader, "Thread1");
startExample.x = 10;
startExample.y = 20;
startExample.flag = true;
thread.start();
System.out.println("main线程结束!");
}
}
输出结果:
main线程结束!
x: 10
y: 20
flag: true
线程1看到了主线程调用thread1.start()之前的所有赋值结果!
join()规则
如果线程 A 执行操作 ThreadB.join() 并成功返回,那么线程 B 中的任意操作 happens-before 于线程 A 从 ThreadB.join() 操作成功返回,和 start 规则刚好相反
主线程 A 等待子线程 B 完成,当子线程 B 完成后,主线程能够看到子线程 B 的赋值操作
package volatilekeyword;
/**
* 验证happens-before规则之join规则
* @author Chenzf
*/
public class JoinExample {
private int x = 0;
private int y = 1;
private boolean flag = false;
public static void main(String[] args) throws InterruptedException {
JoinExample joinExample = new JoinExample();
Thread thread1 = new Thread(joinExample::writer, "线程1");
thread1.start();
thread1.join();
System.out.println("x:" + joinExample.x );
System.out.println("y:" + joinExample.y );
System.out.println("flag:" + joinExample.flag );
System.out.println("主线程结束");
}
public void writer(){
this.x = 100;
this.y = 200;
this.flag = true;
}
}
输出结果:
x:100
y:200
flag:true
主线程结束
总结
- Happens-before重点是解决前一个操作结果对后一个操作可见,Happens-before规则解决了多线程编程的可见性与有序性问题,但还没有完全解决原子性问题(除了
synchronized); start和join规则也是解决主线程与子线程通信的方式之一;- 从内存语义的角度来说,
volatile的写-读与锁的释放-获取有相同的内存效果;volatile写和锁的释放有相同的内存语义;volatile读与锁的获取有相同的内存语义; volatile解决的是可见性问题,synchronized解决的是原子性问题。
内存屏障解决有序性问题
| 能否重排序 | 第二个操作 | 第二个操作 | 第二个操作 | |
|---|---|---|---|---|
| 操作 | 普通读/写 | volatile读 | volatile写 | |
| 第一个操作 | 普通读/写 | - | - | NO |
| 第一个操作 | volatile读 | NO | NO | NO |
| 第一个操作 | volatile写 | - | NO | NO |
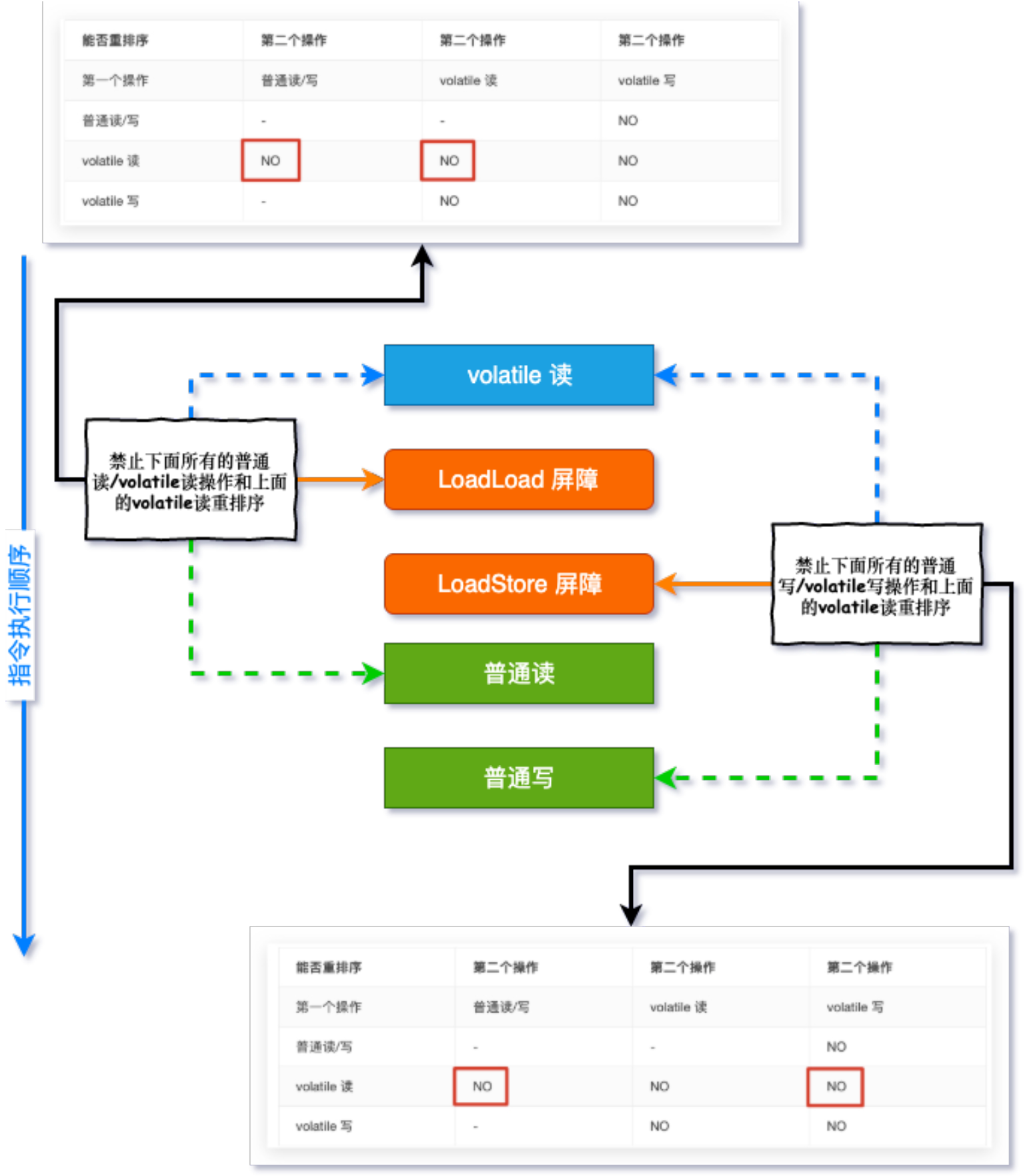
上面的表格是JMM针对编译器定制的volatile重排序的规则,那JMM是怎样禁止重排序的呢?答案是内存屏障!
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序!
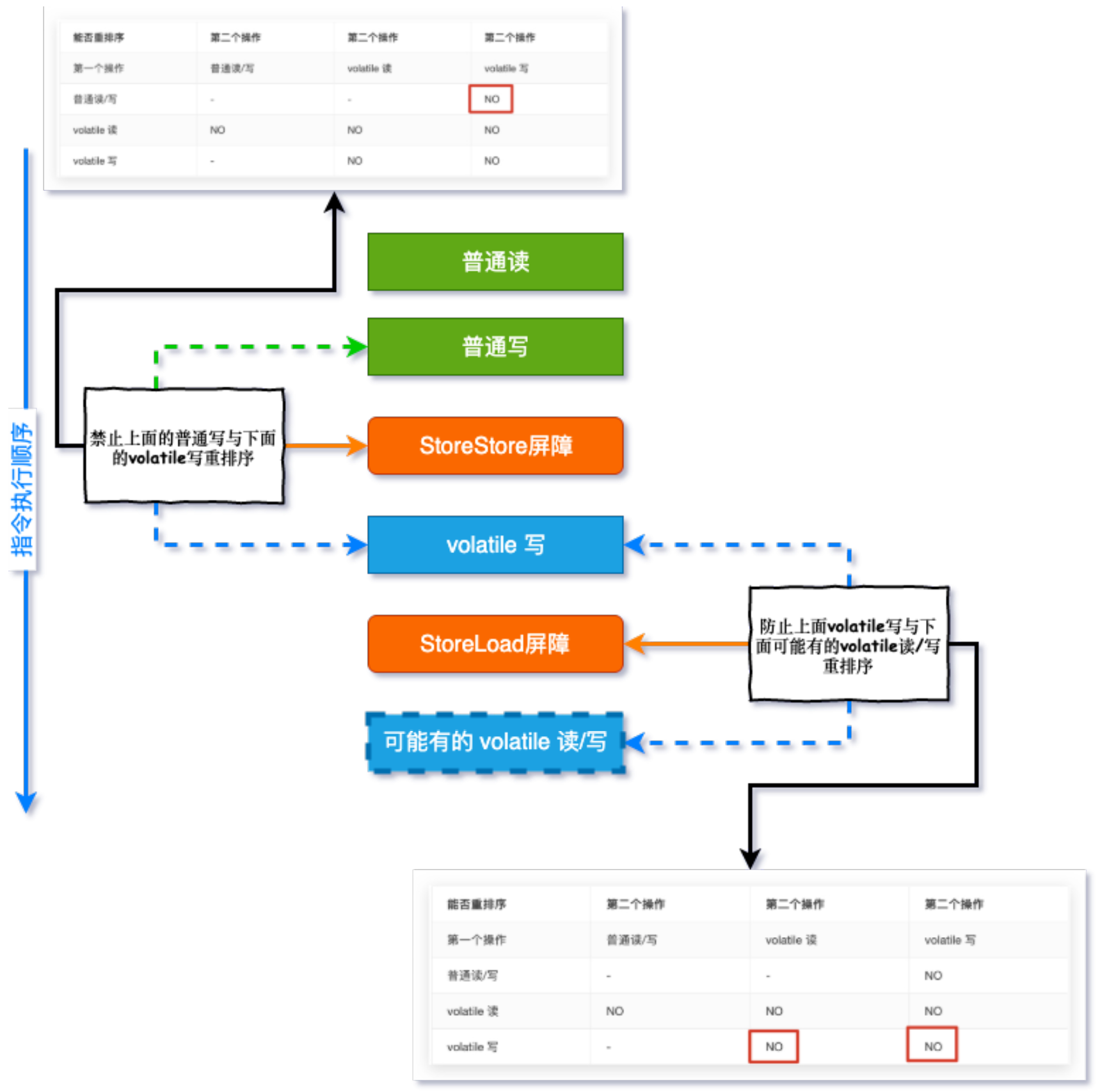
可以将内存屏障想象为一面高墙,如果两个变量之间有这个屏障,那么他们就不能互换位置(重排序)了,变量有读(Load)有写(Store),操作有前有后,JMM就将内存屏障插入策略分为4种:
- 在每个
volatile写操作的前面插入一个StoreStore屏障 - 在每个
volatile写操作的后面插入一个StoreLoad屏障 - 在每个
volatile读操作的后面插入一个LoadLoad屏障 - 在每个
volatile读操作的后面插入一个LoadStore屏障
1和2用图形描述以及对应表格规则为:
3和4用图形描述以及对应表格规则为:
一段程序的读写通常不会像上面两种情况这样简单,这些屏障组合起来如何使用呢?
其实一点都不难,只需要将这些指令带入到文章开头的表格中,然后再按照程序顺序拼接指令就好了:
public class VolatileBarrierExample {
private int a;
private volatile int v1 = 1;
private volatile int v2 = 2;
void readAndWrite(){
int i = v1; // 第一个volatile读
int j = v2; // 第二个volatile读
a = i + j; // 普通写
v1 = i + 1; // 第一个volatile写
v2 = j * 2; // 第二个volatile写
}
}
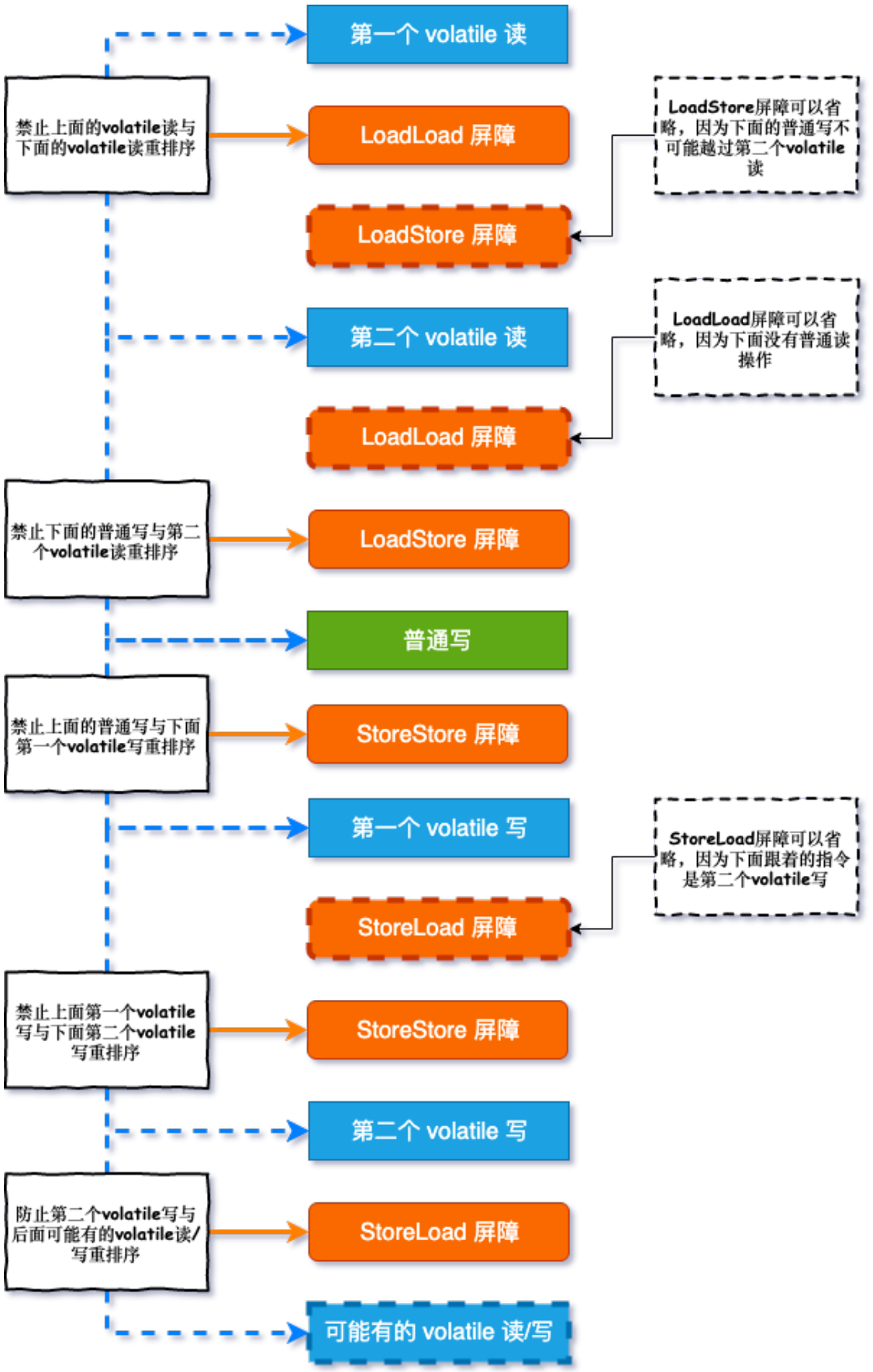
- 黄色方块是将屏障指令带入到程序中生成的全部内容,也就是编译器生成的「最稳妥」的方案
- 显然有很多屏障是重复多余的,右侧虚线框指向的屏障是可以被「优化」删除掉的屏障
以上就是volatile如何通过内存屏障保证程序“不被擅自”排序的解释!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号