并发三大特性
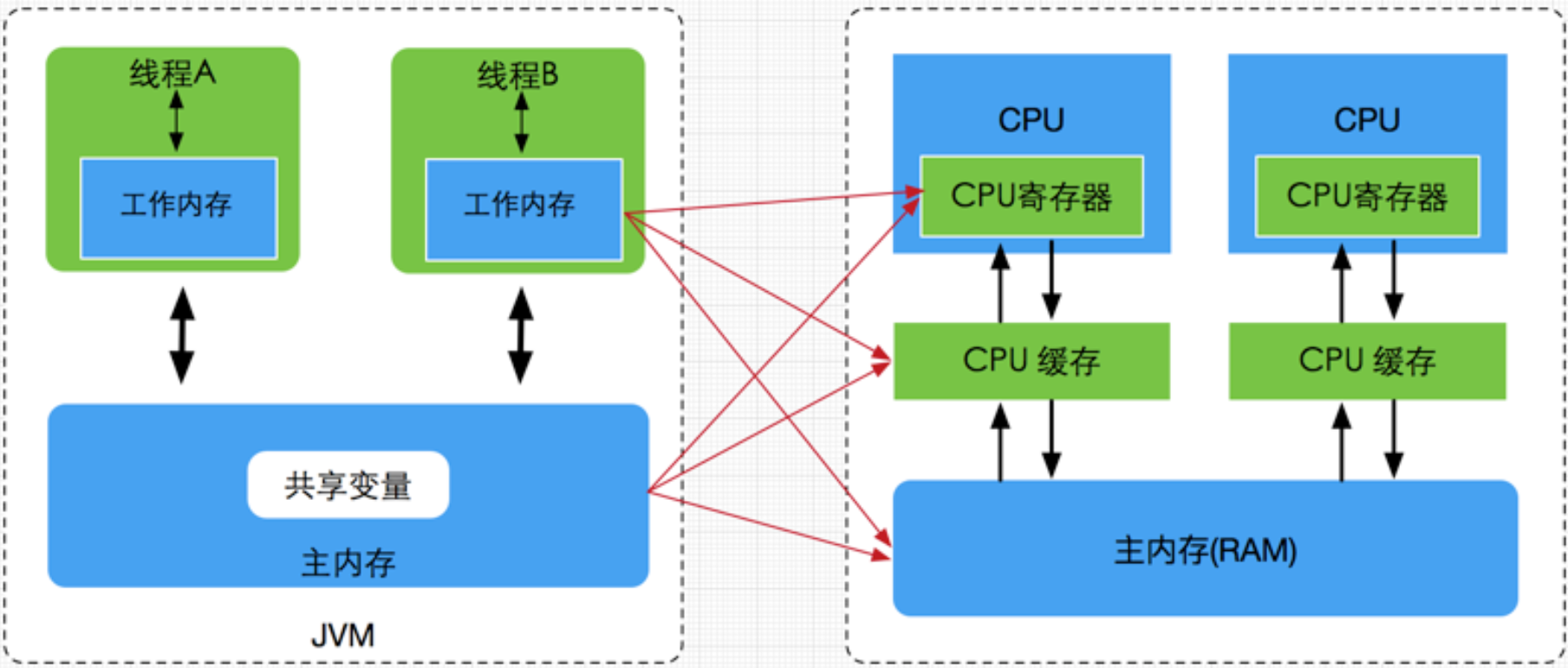
CPU与内存
所有的运算操作都是由CPU的寄存器来完成的,CPU指令的执行过程需要涉及数据的读取和写入操作,CPU所能访问的所有数据只能是计算机的主存(通常是指RAM) 。CPU的处理速度和内存的访问速度差距很大!
Cache模型
由于CPU的处理速度和内存的访问速度差距很大,通过传统FSB直连内存的访问方式,很明显会导致CPU资源受到大量的限制,降低CPU整体的吞吐量。
于是就有了在CPU和主内存之间增加缓存的设计,缓存均衡了与内存的速度差异,现在缓存的数量都可以增加到3级: 最靠近CPU的缓存称为L1,然后依次是L2、L3(当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。)和主内存:
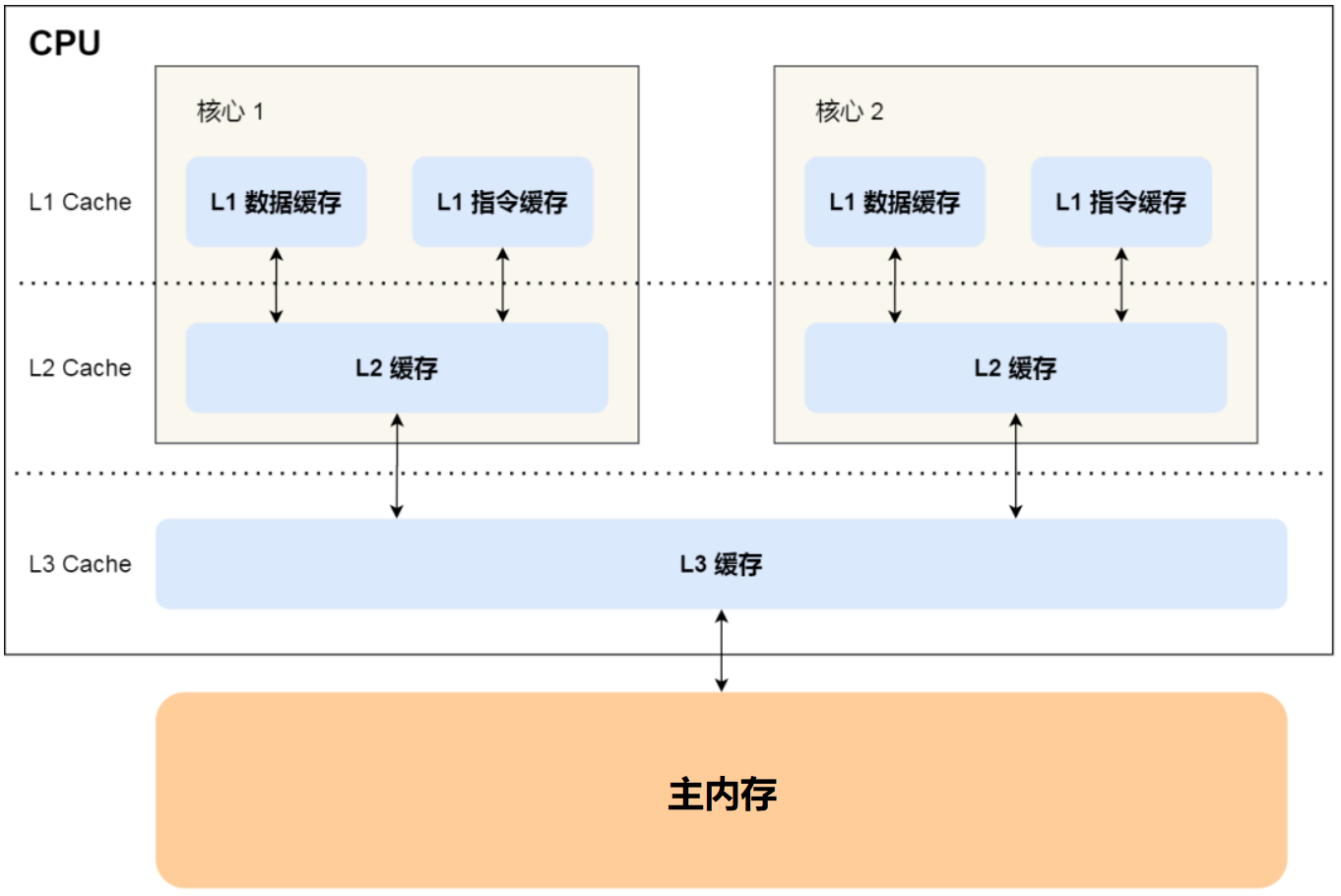
Cache的出现是为了解决,CPU直接访问内存效率低下问题的,程序在运行的过程中
- 会将运算所需要的数据从主存复制一份到CPU Cache中,这样CPU进行计算时就可以直接对CPU Cache中的数据进行读取和写入,
- 当运算结束之后,再将CPU Cache中的最新数据刷新到
主内存当中。
CPU通过直接访问Cache的方式,替代直接访问主存的方式,极大地提高了CPU的吞吐能力。
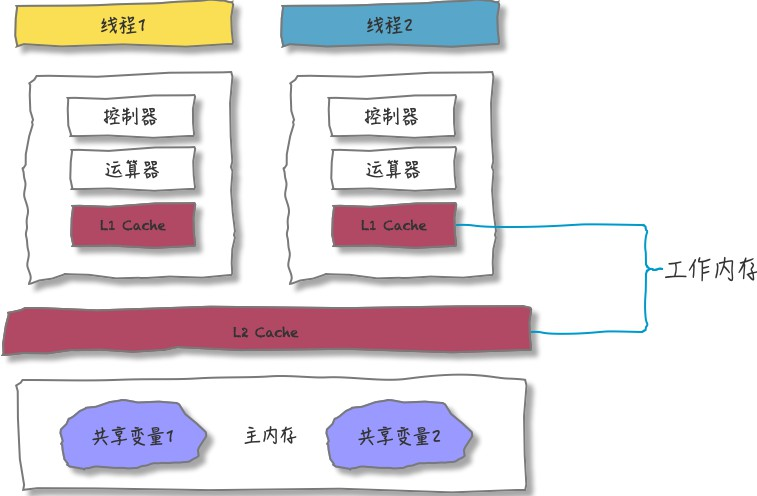
线程读/写共享变量的步骤:
- 从
主内存复制共享变量到自己的工作内存; - 在工作内存中对变量进行处理;
- 处理完后,将变量值
更新回主内存。
CPU缓存不一致性问题
单线程:CPU核心的缓存只被一个线程访问。缓存独占,不会出现访问冲突。
单核CPU,多线程:进程中的多个线程会同时访问进程中的共享数据,CPU将某块内存加载到缓存后,不同线程在访问相同的物理地址的时候,都会映射到相同的缓存位置,这样即使发生线程的切换,缓存仍然不会失效。但由于任何时刻只能有一个线程在执行,因此不会出现缓存访问冲突(不意味着不会出现并发问题)。
多核CPU,多线程:每个核都至少有一个L1缓存。多个线程访问进程中的某个共享内存,且多个线程分别在不同的核心上执行,则每个核心都会在各自的caehe中保留一份共享内存的缓冲。由于多核是可以并行的,可能会出现多个线程同时写各自的缓存的情况,而各自的cache之间的数据就有可能不同,从而出现访问冲突问题。
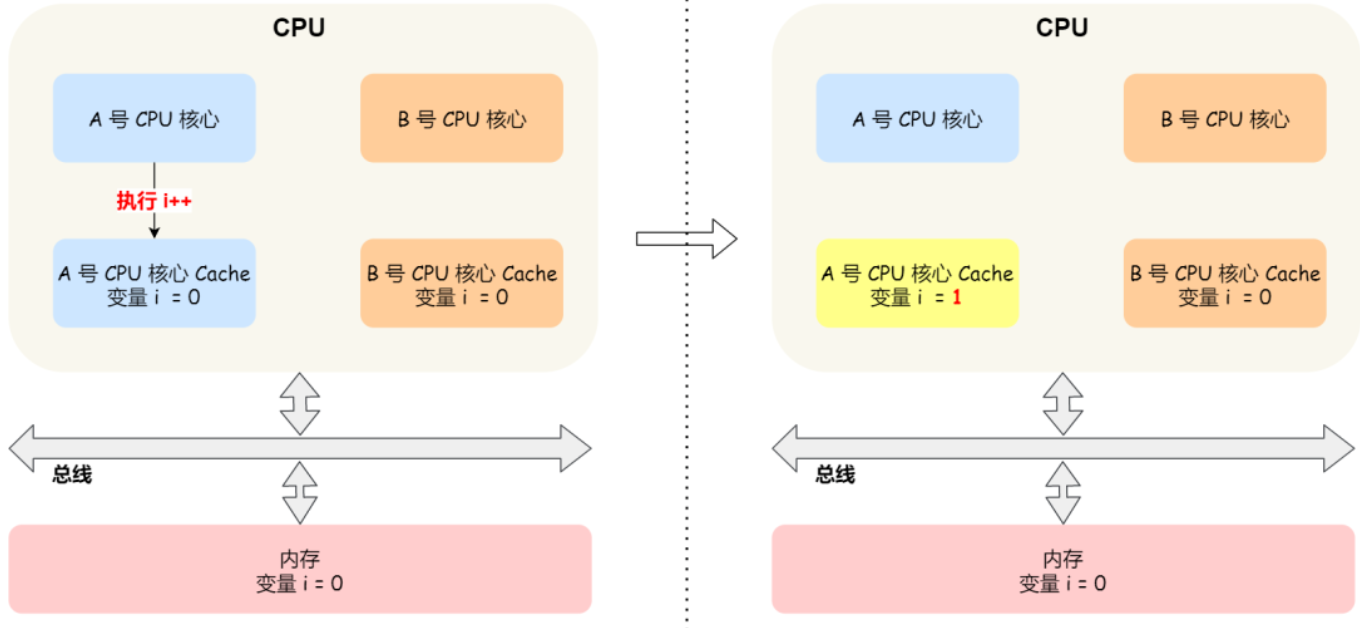
由于缓存的出现,极大地提高了CPU的吞吐能力,但是同时也引入了缓存不一致的问题,比如i++这个操作,在程序的运行过程中,首先需要将主内存中的数据复制一份存放到CPU Cache中, 那么CPU寄存器在进行数值计算的时候就直接到Cache中读取和写入,当整个过程运算结束之后再将Cache中的数据刷新到主存当中,具体过程如下:
- 读取主内存的i到CPU Cache中;
- 对i进行加一操作;
- 将结果写回到CPU Cache中;
- 将数据刷新到主内存中。
i++在单线程的情况下不会出现任何问题,但是在多线程的情况下就会有问题,每个线程都有自己的工作内存(本地内存, 对应于CPU中的Cache),变量i会在多个线程的本地内存中都存在一个副本。如果同时有两个线程执行i++操作, 假设i的初始值为0,每一个线程都从主内存中获取i的值存入CPU Cache中,然后经过计算再写入主内存中,很有可能i在经过了两次自增之后结果还是1,这就是典型的缓存不一致性问题。
为了解决缓存不一致性问题, 通常主流的解决方法有如下两种
-
通过总线加锁的方式
CPU和其他组件的通信都是通过总线(数据总线、控制总线、地址总线)来进行的,如果采用
总线加锁的方式,则会阻塞其他CPU对其他组件的访问,从而使得只有一个CPU(抢到总线锁)能够访间这个变量的内存。这种方式效率低下。 -
通过缓存一致性协议
在缓存一致性协议中最为出名的是Intel的MESI协议,MESI协议保证了每一个缓存中使用的共享变量副本都是一致的:当CPU在操作Cache中的数据时,如果发现该变量是一个共享变量,也就是说在其他的CPU Cache中也存在一个副本,那么进行如下操作:
- 读取操作,不做任何处理,只是将Cache中的数据读取到寄存器;
- 写入操作,发出信号通知其他CPU将该变量的Cache line置为无效状态,其他CPU在进行该变量读取的时候不得不到主内存中再次获取。
Java内存模型JMM
Java的内存模型(Java Memory Mode, JMM)指定了Java虚拟机如何与计算机的主存(RAM)进行工作,是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。Java的内存模型决定了,一个线程对共享变量的写入,何时对其他线程可见,Java内存模型定义了线程和主内存之间的抽象关系:
- 共享变量存储于主内存RAM之中,每个线程都可以访问:
- 主要存储的是Java实例对象,所有线程创建的实例对象,都存放在主内存中,不管该实例对象是成员变量,还是方法中的本地变量(局部变量),当然也包括了共享的类信息、常量、静态变量。
- 由于是共享数据区域,多条线程对同一个变量进行访问,可能会发现线程安全问题。
- 每个线程都有私有的工作内存或者称为本地内存,并且工作内存只存储该线程对共享变量的副本;
- 线程对变量的所有操作,都必须在自己的工作内存中进行,不能直接操作主内存,只有先将数据写入了工作内存之后,才能写入主内存;
- 每一个线程都不能访问其他线程的工作内存或者本地内存。
- 工作内存和Java内存模型一样也是一个抽象的概念,它其实并不存在,它涵盖了缓存、寄存器、编译器优化以及硬件等。
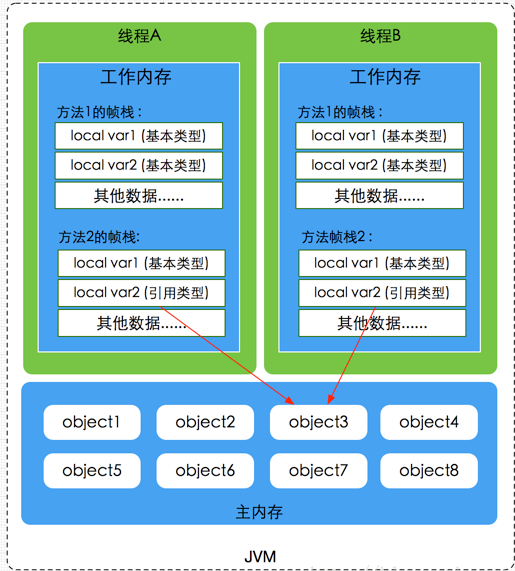
主内存与工作内存的数据存储类型:
- 对于一个实例对象中的成员方法而言,如果方法中包含本地变量是基本数据类型(局部变量),将直接存储在工作内存的帧栈结构中;倘若本地变量是引用类型,那么该变量的引用会存储在工作内存的帧栈中,而对象实例将存储在主内存(共享数据区域,堆)中。
- 对于实例对象的成员变量(共享的),不管它是基本数据类型或者包装类型(Integer、Double等)还是引用类型,还有
static变量以及类本身相关信息,都将会存储在主内存中。
在主内存中的实例对象可以被多线程共享,倘若两个线程同时调用了同一个对象的同一个方法,那么两条线程会将要操作的数据拷贝一份到自己的工作内存中,执行完成操作后才刷新到主内存。
线程对主存的操作指令
JLS定义了线程对主存的操作指令:lock,unlock,read,load,use,assign,store,write。这些行为是不可分解的原子操作,在使用上相互依赖,read-load从主内存复制变量到当前工作内存,use-assign执行代码改变共享变量值,store-write用工作内存数据刷新主存相关内容。
- read(读取):作用于主内存变量,把一个变量值从主内存传到线程的工作内存中,以便随后的load动作使用;
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
- write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
Java内存模型与硬件内存架构的关系
对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没有工作内存(线程私有数据区域)和主内存(堆内存)之分,也就是说Java内存模型对内存的划分对硬件内存并没有任何影响,因为JMM只是一种抽象的概念,是一组规则,并不实际存在。
不管是工作内存的数据还是主内存的数据,对于计算机硬件来说都会存储在计算机主内存中,当然也有可能存储到CPU缓存或者寄存器中,因此总体上来说,Java内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真实物理硬件的交叉。
重排
计算机在执行程序时,为了提高性能,编译器和处理器的常常会对指令做重排,一般分以下3种
-
编译器重排
- 编译器优化的重排:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
-
处理器重排
-
指令并行的重排:现代处理器采用了指令级并行技术,来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序。
-
内存系统的重排:由于处理器使用缓存和读写缓存冲区,这使得
加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
-
其中编译器优化的重排属于编译器重排,指令并行的重排和内存系统的重排属于处理器重排,在多线程环境中,这些重排优化可能会导致程序出现问题。
编译器重排
线程 1 线程 2
1:x2 = a ; 3: x1 = b ;
2: b = 1; 4: a = 2 ;
从程序的执行顺序上看,似乎不太可能出现x1 = 1和x2 = 2的情况,但实际上这种情况是有可能发现的,因为如果编译器对这段程序代码执行重排优化后,可能出现下列情况:
线程 1 线程 2
2: b = 1; 4: a = 2 ;
1:x2 = a ; 3: x1 = b ;
这种执行顺序下就有可能出现x1 = 1和x2 = 2的情况,这也就说明在多线程环境下,由于编译器优化重排的存在,两个线程中使用的变量能否保证一致性是无法确定的。
处理器指令重排
处理器指令重排是对CPU的性能优化,从指令的执行角度来说一条指令可以分为多个步骤完成,如下
- 取指 IF
- 译码和取寄存器操作数 ID
- 执行或者有效地址计算 EX
- 存储器访问 MEM
- 写回 WB
指令流水线执行过程:
指令1:IF ID EX MEM WB
指令2: IF ID EX MEM WB
指令3: IF ID EX MEM WB
可以看出当指令1还未执行完成时,第2条指令便利用空闲的硬件开始执行,这样做是有好处的。如果每个步骤花费\(1ms\),那么如果第2条指令需要等待第1条指令执行完成后再执行的话,则需要等待\(5ms\)。但如果使用流水线技术的话,指令2只需等待\(1ms\)就可以开始执行了,这样就能大大提升CPU的执行性能。
虽然流水线技术可以大大提升CPU的性能,但不幸的是一旦出现流水中断,所有硬件设备将会进入一轮停顿期,当再次弥补中断点可能需要几个周期,这样性能损失也会很大。
因此需要尽量阻止指令中断的情况,指令重排就是其中一种优化中断的手段。
a=b+c; d=e-f的指令流水线执行过程(指令重排前):

在某些指令上存在X的标志,X代表中断的含义,也就是只要有X的地方就会导致指令流水线技术停顿,同时也会影响后续指令的执行,可能需要经过1个或几个指令周期才可能恢复正常,那为什么停顿呢?这是因为部分数据还没准备好,如执行ADD指令时,需要使用到前面指令的数据R1,R2,而此时R2的MEM操作没有完成,即未拷贝到存储器中,这样加法计算就无法进行,必须等到MEM操作完成后才能执行,也就因此而停顿了。
停顿会造成CPU性能下降,因此应该想办法消除这些停顿,这时就需要使用到指令重排了。既然ADD指令需要等待,那就利用等待的时间做些别的事情,如把LW R4,e和 LW R5,f移动到前面执行,毕竟LW R4,e和LW R5,f执行并没有数据依赖关系,对他们有数据依赖关系的SUB R6,R5,R4指令在R4,R5加载完成后才执行的,没有影响:
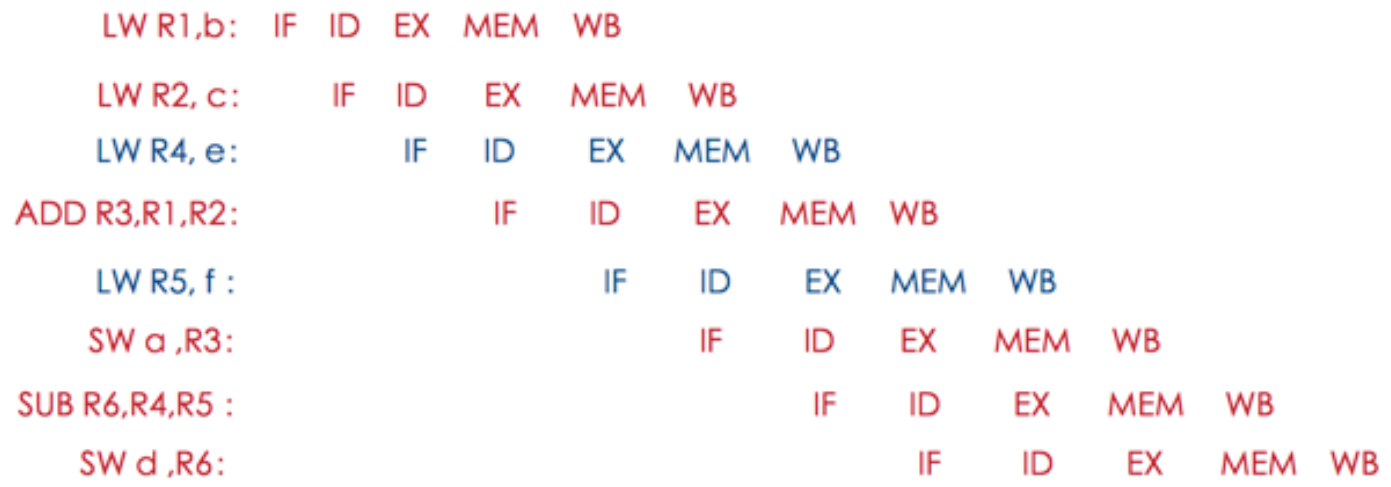
所有的停顿都完美消除了,指令流水线也无需中断了,这样CPU的性能也能带来很好的提升,这就是处理器指令重排的作用。
可见性
可见性是指,当一个线程对共享变量进行了修改,那么另外的线程可以立即看到修改后的最新值!
假设现在主内存中有共享变量X,其初始值为0,线程1先访问变量X;然后,线程2同样按照上面的步骤访问变量X:
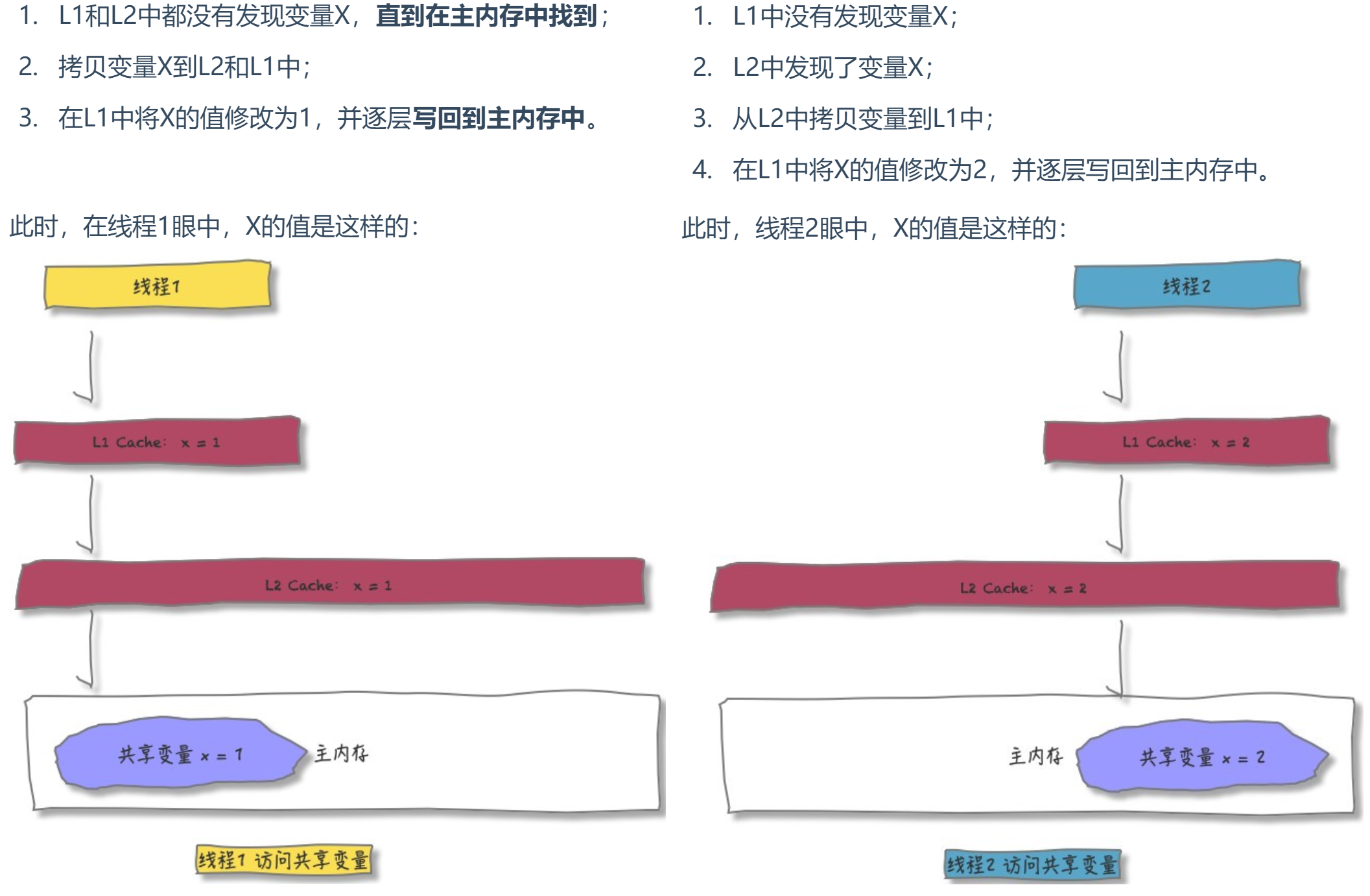
当线程1再访问变量X:
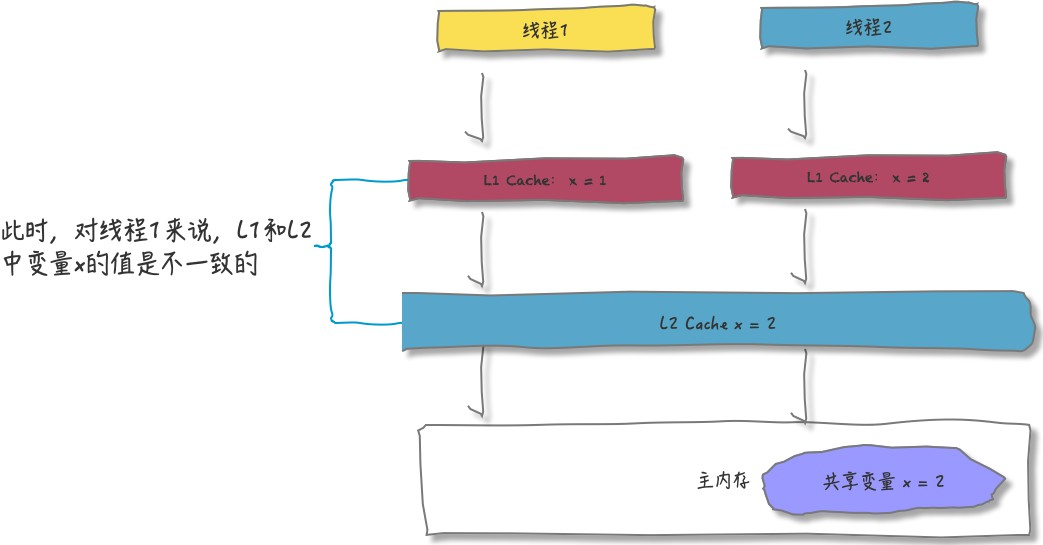
此刻,如果线程1再次将x=1回写,就会覆盖线程2x=2的结果,同样的共享变量,线程拿到的结果却不一样(线程1眼中x=1;线程2眼中x=2),这就是共享变量内存不可见的问题。
注意:
- 所有的实例域,静态域和数组元素都存储在堆内存中,堆内存在线程之间共享,这些被称为共享变量。
- 局部变量,方法定义参数和异常处理器参数不会在线程之间共享,所以他们不会有内存可见性的问题,也就不受内存模型的影响!
- 要想解决多线程可见性问题,所有线程都必须要刷取主内存中的变量
保证可见性方法
在多线程的环境下
-
如果某个线程首次
读取共享变量,则首先到主内存中获取该变量,然后存入工作内存中,以后只需要在工作内存中读取该变量即可。 -
同样如果对该变量执行了
修改的操作,则先将新值写入工作内存中,然后再刷新至主内存中。 -
但是什么时候最新的值会被刷新至主内存中,是不太确定的!
Java提供了以下三种方式来保证可见性:
-
使用关键字
volatile,当一个变量被volatile关键字修饰时,对于共享资源的读操作会直接在主内存中进行(当然也会缓存到工作内存中,当其他线程对该共享资源进行了修改,则会导致当前线程在工作内存中的共享资源失效,所以必须从主内存中再次获取);对于共享资源的写操作当然是先要修改工作内存,但是修改结束后会立刻将其刷新到主内存中。-
线程在【读取】共享变量时,会先清空本地内存变量值,再从主内存获取最新值;
-
线程在【写入】共享变量时,不会把值缓存在寄存器或其他地方(工作内存),而是会把值刷新回主内存。
-
-
通过
synchronized关键字能够保证可见性,synchronized关键字能够保证同一时刻只有一个线程获得锁,然后执行同步方法,并且还会确保在锁释放之前,会将对变量的修改刷新到主内存当中。-
【进入】synchronized块的内存语义是把在synchronized块内使用的变量从线程的工作内存中清除,
从主内存中读取; -
【退出】synchronized块的内存语义是把在synchronized块内对共享变量的修改刷新到主内存中。
-
-
通过JUC提供的显式锁
Lock也能够保证可见性- Lock的
lock方法能够保证在同一时刻只有一个线程获得锁,然后执行同步方法;并且会确保在锁释放(Lock的unlock方法)之前会将对变量的修改刷新到主内存当中。
- Lock的
原子性
原子操作是指不会被线程调度机制打断的操作。这种操作一旦开始,就一直运行到结束,中间不会有任何context switch!
package volatilekeyword;
public class UnsafeCounter {
private long count;
private final long MAX = 10000;
public void counter() {
long start = 0;
while (start++ < MAX) {
count++;
}
}
public long getCount() {
return count;
}
public static void main(String[] args) throws InterruptedException {
UnsafeCounter unsafeCounter = new UnsafeCounter();
Thread thread1 = new Thread(unsafeCounter::counter, "Thread1");
Thread thread2 = new Thread(unsafeCounter::counter, "Thread2");
thread1.start();
thread2.start();
// 可中断方法
thread1.join();
thread2.join();
System.out.println(unsafeCounter.getCount());
}
}
输出结果不是20000!
不能用高级语言思维来理解CPU的处理方式,count++转换成CPU指令则需要三步,通过下面命令解析出汇编指令等信息:
javap -c UnsafeCounter
getfield:获取当前count值,并且放入栈顶;lconst_1:将常量1放入栈顶;ladd:将当前栈顶中两个值相加,并把结果放入栈顶;putfield:把栈顶的结果再赋值给count。
由此可见,简单的count++不是一步操作(读取、计算、赋值),不具备原子性!
由于不是原子性操作,导致count++过程中存在线程切换:
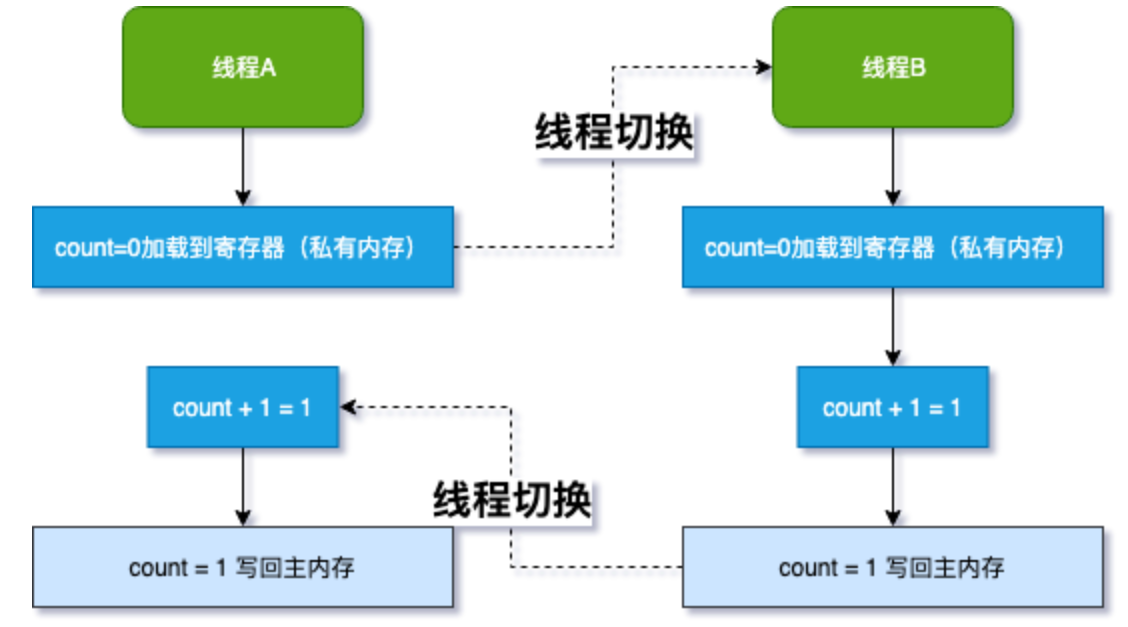
除了JVM自身提供的对基本数据类型读写操作的原子性外,对于方法级别或者代码块级别的原子性操作,可以使用synchronized关键字或者重入锁(ReentrantLock)保证程序执行的原子性:
public synchronized void counter() {
long start = 0;
while (start++ < MAX) {
count++;
}
}
public synchronized long getCount() {
return count;
}
互斥解决原子性问题
原子性问题的源头就是线程切换,但在多核CPU的大背景下,不允许线程切换是不可能的,因此规定:同一时刻,只有一个线程执行——互斥!其含义为:对共享变量的修改是互斥的,也就是说线程A修改共享变量时,其他线程不能修改,这就不存在操作被打断的问题了。
那么如何实现互斥呢?synchronized锁就是一种互斥锁!
线程1在执行monitorenter指令的时候,会对Monitor进行加锁,加锁后其他线程无法获得锁,除非线程1主动解锁。即使在执行过程中,由于某种原因,比如CPU时间片用完,线程1放弃了CPU,但是,由于线程1并没有进行解锁,而synchronized的锁是可重入的,下一个时间片还是只能被他自己获取到,还是会继续执行代码。直到所有代码执行完。这就保证了原子性。
CAS解决原子性问题
但由于synchronized是独占锁(同一时间只能有一个线程可以调用),没有获取锁的线程会被阻塞;另外也会带来很多线程切换的上下文开销!
所以JDK中就有了非阻塞CAS(Compare and Swap)算法实现的原子操作类AtomicLong等工具类!
有序性
有序性是指程序代码在执行过程中的先后顺序,由于Java在编译器以及运行期的优化,导致了代码的执行顺序未必就是开发者编写代码时的顺序!
a = 1;
b = 2;
System.out.println(a);
System.out.println(b);
重排优化后可能就变成了:
b = 2;
a = 1;
System.out.println(a);
System.out.println(b);
在单线程情况下,无论怎样的重排序,最终都会保证程序的执行结果,和代码顺序执行的结果是完全一致的,但是在多线程的情况下,如果有序性得不到保证,那么很有可能就会出现非常大的问题:
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton(); // 转换成CPU指令后变成了3个步骤
}
}
}
return instance;
}
}
其中instance = new Singleton();转换成CPU指令后变成了3个,错误的理解new对象应该是这样的:
- 分配一块内存M;
- 在内存M上初始化Singleton对象;
- 然后M的地址赋值给instance变量。
但编译器擅自优化后可能就变成了这样:
- 分配一块内存M;
- 然后将M的地址赋值给instance变量;
- 在内存M上初始化Singleton对象。
首先new对象分了三步,给CPU留下了切换线程的机会;另外,编译器优化后的顺序可能导致问题的发生:
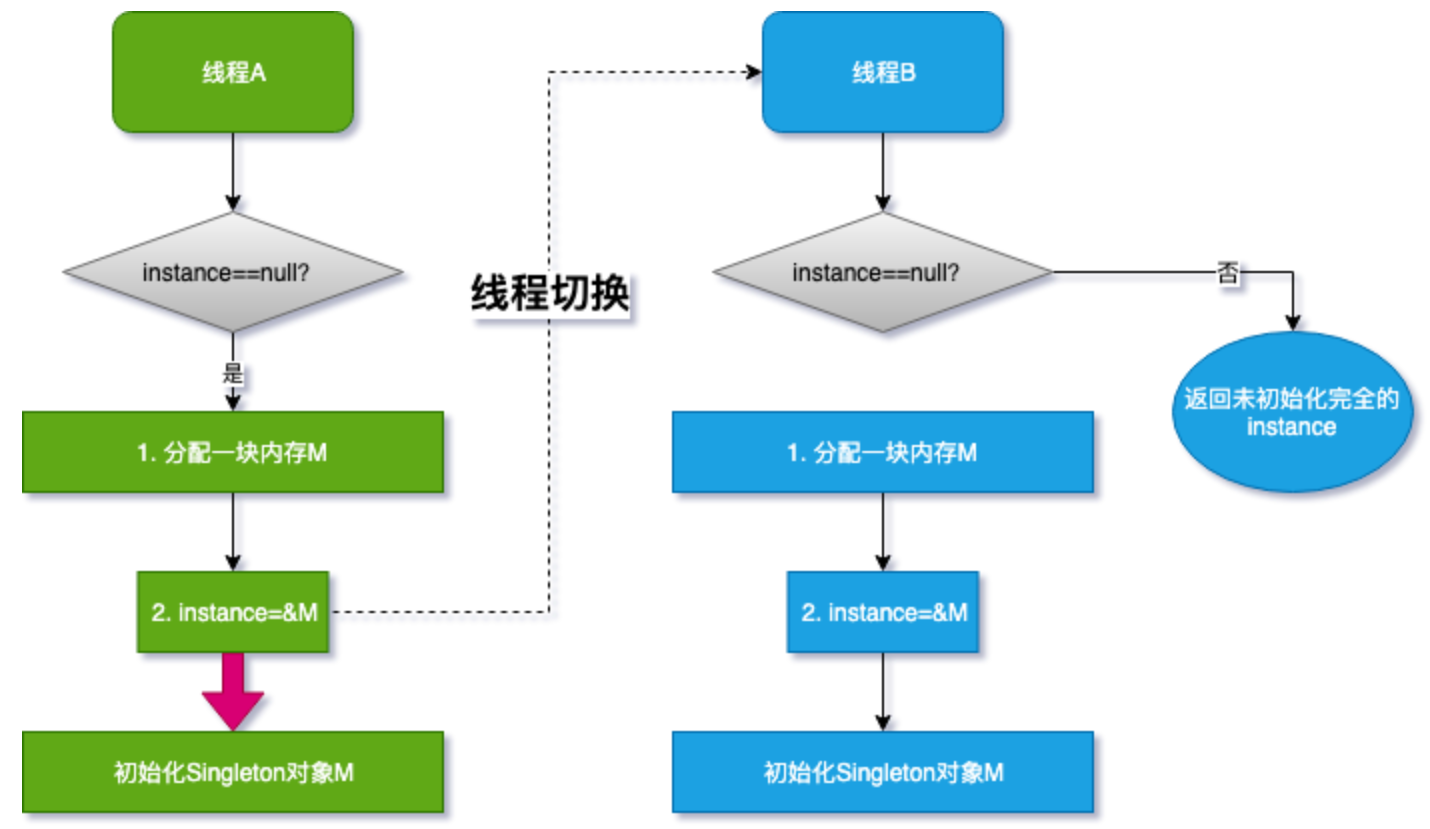
- 线程A先执行getInstance方法,当执行到指令2时,恰好发生了线程切换;
- 线程B刚进入到getInstance方法,判断if语句instance是否为空;
- 线程A已经将M的地址赋值给了instance变量,所以线程B认为instance不为空。线程B直接return instance变量;
- CPU切换回线程A,线程A完成后续初始化内容。
如果线程A执行到第2步,线程切换,由于线程A没有把红色箭头执行完全,线程B就会得到一个未初始化完全的对象,访问instance成员变量的时候就可能发生NPE!
保证有序性方法
volatile关键字会禁止指令重排。synchronized关键字保证同一时刻只允许一条线程操作,可以避免指令重排的影响!
如果将变量instance用volatile(volatile通过内存屏障保证程序不被”擅自”排序)或者final修饰(涉及到类的加载机制),问题就解决了!
public class Singleton {
private volatile static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
instance = new Singleton(); // 转换成CPU指令后变成了3个步骤
}
}
}
return instance;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号