
python爬虫实战:基础爬虫(使用BeautifulSoup4等)

以前学习写爬虫程序时候,我没有系统地学习爬虫最基本的模块框架,只是实现自己的目标而写出来的,最近学习基础的爬虫,但含有完整的结构,大型爬虫含有的基础模块,此项目也有,“麻雀虽小,五脏俱全”,只是没有考虑优化和稳健性问题。
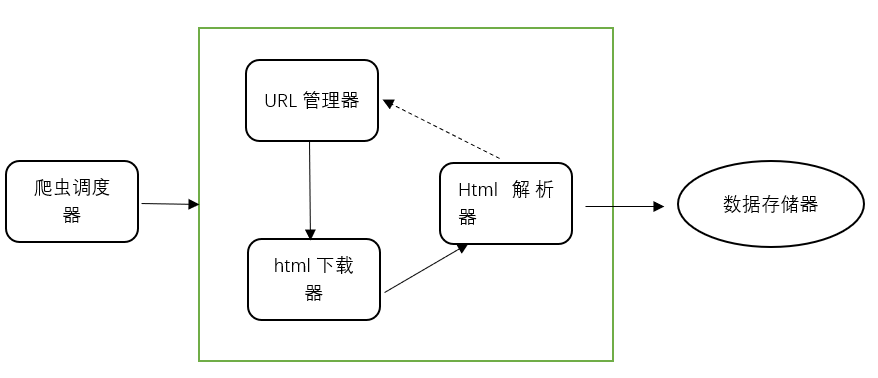 爬虫框架
爬虫框架
爬虫框架包括这五大模块,简单介绍作用:1.爬虫调度器:协调其他四大模块工作;2.URL管理器:就是管理提供爬取的链接,分为已爬取URL集合和未爬取URL集合;3.html下载器:下载URL的整个html网页;4.html解析器:将下载的网页进行解析,获得有效数据;5.数据存储器:存储解析后的数据,以文件或数据库形式存储。
项目准备爬取百度百科的一些名词解释和链接,这是小的项目,许多方法简化处理,做起来简洁有效。下面是具体步骤:
1、URL管理器
根据作用可知,它包括2个集合,已爬取和未爬取URL链接,所以使用python的set()类型进行去重,防止重复死循环。这里在实践时候我存在疑问,后面再讨论。去重方案主要有3种:1)内存去重,2)关系数据库去重,3)缓存数据库去重;明显地,大型成熟爬虫会选择后两种,避免内存大小限制,而现在尚未成熟的小项目,就使用第1种。
class UrlManager(): # URL管理器 def __init__(self): self.new_urls = set() # 未爬取集合(去重) self.old_urls = set() def has_new_url(self): return self.new_url_size() != 0 # 判断是否有未爬取 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url def add_new_url(self, url): # 将新的URL添加到未爬取集合 if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: self.add_new_url(url) def new_url_size(self): # print(len(self.new_urls)) return len(self.new_urls) def old_url_size(self): return len(self.old_urls)
几个函数作用很清晰,它会将新的链接加入未爬取集合,爬取过的URL就存入old_urls集合中。
2、HTML下载器
这里本来用requests包操作,但是我在后面运行程序时出现错误,所以后来我用了urllib包代替,而requests是它的高级封装,按往常也是用这个,具体是函数返回值出问题还是其他原因还没找出来,给出2个方法,需要大家指正。
import urllib.request class HtmlDownloader(object): def download(self, url): if url is None: return None user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' headers = {'User-Agent': user_agent} html_content = urllib.request.Request(url,headers=headers)#urlopen(url) response=urllib.request.urlopen(html_content) if response.getcode() == 200: # print(response.read()) return response.read()#.decode('utf-8') return None
这个是成功的方法,使用urllib打开URL链接,添加请求头可以更好的模拟正常访问,根据状态码返回内容。而存在问题的requests如下:
import requests#使用requests包爬取,结果提示页面不存在 class HtmlDownloader(object): # HTML下载器 def download(self, url): if url is None: return None user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)' headers = {'User-Agent': user_agent} respondse = requests.get(url, headers=headers) # print(url) if respondse.status_code != 200: return None # respondse.encoding = 'utf-8' # print(respondse.content) return respondse.content
测试时候可看出urllib的respondse.read()与requests的content都是bytes类型,从代码阅读上大体一样,经过几次尝试,以为是编解码问题,最后还是没能找出问题,所以用了urllib进行。
3、HTML下载器
这里使用BeautifulSoup4进行解析,bs4进行解析可以很简洁的几行代码完成,功能强大常使用。先分析网页结构格式,写出匹配表达式获取数据。

分析之后标题title = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1')。获取tag中包含的所有文本内容,包括子孙tag中的内容,并将结果作为Unicode字符串返回,词条解释可写出式子匹配summary = soup.find('div', class_='lemma-summary')。
import re from urllib.parse import urljoin from bs4 import BeautifulSoup class HtmlParser(object): def _get_new_data(self, page_url, soup): data = {} data['url'] = page_url title = soup.find('dd', class_='lemmaWgt-lemmaTitle-title').find('h1') data['title'] = title.get_text() summary = soup.find('div', class_='lemma-summary') data['summary'] = summary.get_text() # print(summary_node.get_text()) return data def _get_new_urls(self, page_url, soup): new_urls = set() # print(new_urls) links = soup.find_all('a', href=re.compile('/item/\w+')) for link in links: new_url = link['href'] new_full_url = urljoin(page_url, new_url) new_urls.add(new_full_url) # print(new_full_url) return new_urls def parser(self, page_url, html_cont): if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont, 'html.parser') new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) return new_urls, new_data
这里使用了正则表达式来匹配网页中的词条链接:links = soup.find_all('a', href=re.compile('/item/\w+'))
4、数据存储器
包括两个方法,store_data:将目标数据存到列表中;out_html:数据输出外存,这里存为html格式,也可以根据需要存为csv、txt形式。
import codecs class DataOutput(object):#数据存储器 def __init__(self): self.datas=[] def store_data(self,data): if data is None: return self.datas.append(data) def output_html(self): fout=codecs.open('baike.html','w',encoding='utf-8') fout.write("<html>") fout.write("<head><meta charset='utf-8'/></head>") fout.write("<body>") fout.write("<table>") for data in self.datas: print(data["title"]) fout.write("<tr>") fout.write("<td>%s</td>"%data['url']) fout.write("<td>%s</td>"%data['title']) fout.write("<td>%s</td>" % data['summary']) fout.write("</tr>") # self.datas.remove(data) fout.write("</table>") fout.write("</body>") fout.write("</html>") fout.close()
爬取数据量少的情况下可用以上方法,否则要使用分批存储,避免发生异常,数据丢失。
5、爬虫调度器
终于到最后步骤了,也是关键的一步,协调上面所有“器”,爬虫开始!
from craw_pratice.adataOutput import DataOutput from craw_pratice.ahtmlDownloader import HtmlDownloader from craw_pratice.ahtmlParser import HtmlParser from craw_pratice.aurlManeger import UrlManager class spiderman(object): def __init__(self): self.manage = UrlManager() self.downloader = HtmlDownloader() self.parser = HtmlParser() self.output = DataOutput() def crawl(self, root_url): self.manage.add_new_url(root_url) # 判断URL管理器中是否有新的URL,同时判断抓去了多少个URL while (self.manage.has_new_url() and self.manage.old_url_size() < 100): try: new_url = self.manage.get_new_url() # 从管理器获取新的URL print("已经抓取%s个链接: %s" % (self.manage.old_url_size(), new_url)) html = self.downloader.download(new_url) # 下载网页 # print(html) new_urls, data = self.parser.parser(new_url, html) # 解析器抽取网页数据 print(data) self.manage.add_new_urls(new_urls) self.output.store_data(data) # 存储 except Exception: print("crawl failed") self.output.output_html() if __name__ == "__main__": root_url = 'https://baike.baidu.com/item/Python/407313' spider_man = spiderman() spider_man.crawl(root_url)
至此,整个爬虫项目完成了,效果如图:
这是我成功后的小总结,而过程并不是如此顺利,而是遇到小问题,对程序代码不断debug,比如:
上面说到的requests问题,导致爬取的链接不存在,一直提示页面不存在。后来采取urllib解决。还有第3中urljoin的调用,整个小爬虫项目我用到的是python3.6,已经把urlparse模块封装到urllib里面,所以不采用import parser。
这个项目实践让我学习到爬虫最基本的框架,各个功能都实现模块化,清晰简洁,为之后实现大型成熟的爬虫项目做了铺垫,分享学习心得,希望能学得更好,要继续努力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号