
第一次个人编程作业
https://github.com/chenwenghao/031902504
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 600 | |
| Development | 开发 | 480 | 610 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 50 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 60 | 100 |
| · Coding | · 具体编码 | 180 | 250 |
| · Code Review | · 代码复审 | 60 | 90 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 90 | 100 |
| · Test Repor | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| · 合计 | 570 | 710 |
二、计算模块接口
1.计算模块接口的设计与实现过程。
首先,我将问题简化,先解决从一行的文本中找出关键字的问题,如下(以英文关键字为例):
输入示例:
2 //关键字的个数
fuck
awc
f!%%ucknawcfU cknnwfucawc //需要检测的一行文本
输出:
f!%%uck
awc
fU ck
awc
思路流程图:
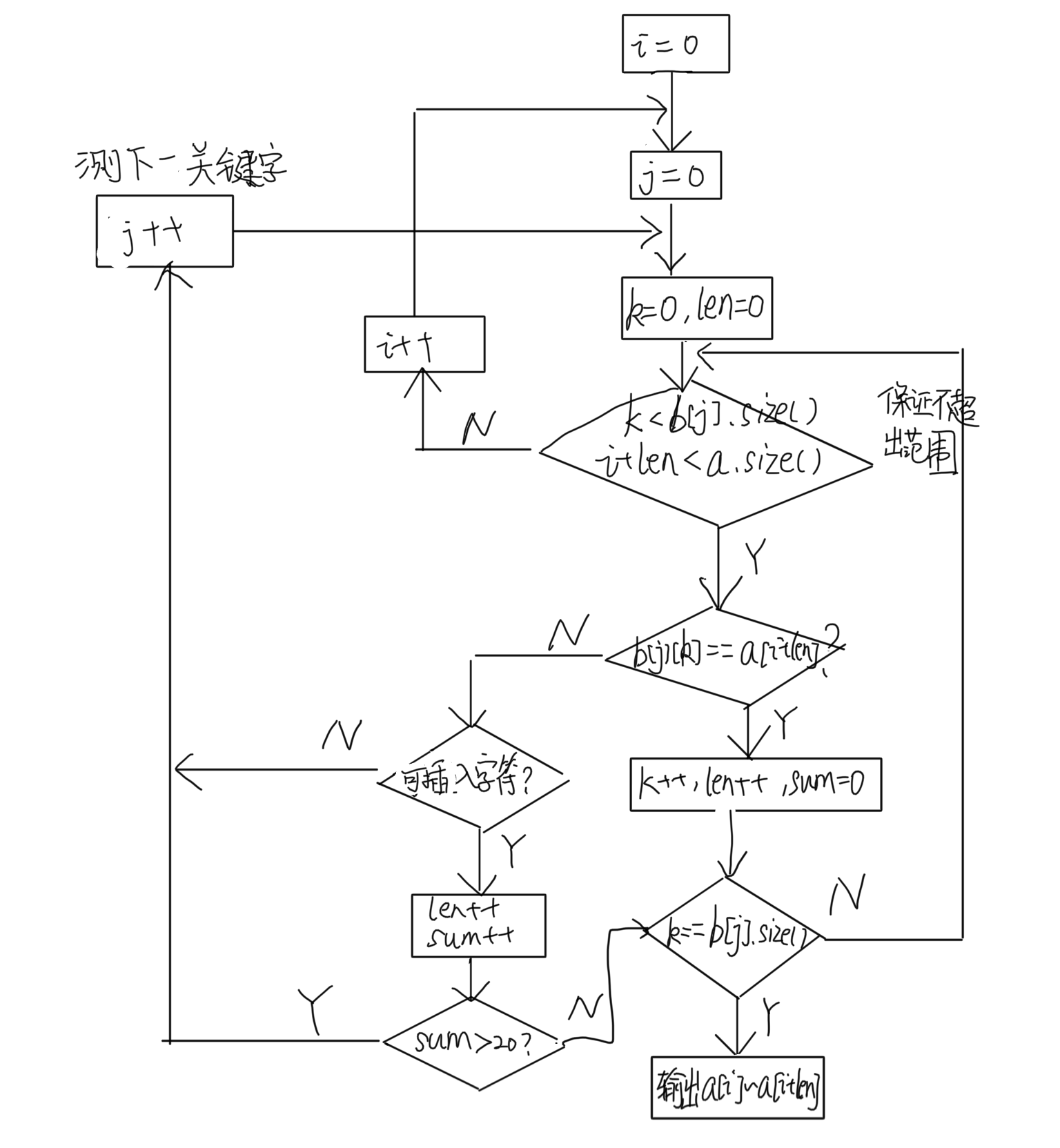
(其中wstring a存储待测文本,wstring b【】存储关键字,len是找到的关键字长度。)
对中文和英文关键字分开判断通过简单的嵌套循环可以解决这一问题,接着我学习了C++如何从txt文件中逐行读取数据,并将想要的答案输出到一个新的文件中:
读取txt文本数据:

答案输出:

2.计算模块接口部分的性能改进。
由于思路比较简单,对计算模块性能上的改进不多,只是简单对条件判断的语句进行改进,删去了冗余的条件判断语句,以下是我的性能分析图:

以下是我程序中消耗最大的函数,占用了47%左右的CPU时间:

3.计算模块部分单元测试展示。
核心代码初步测试(输入是关键字个数和待测文本):
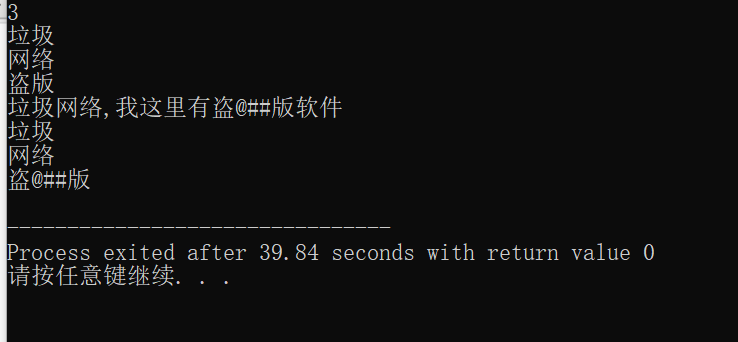
作业给出的样例测试:
输入对应的三个地址:

我的答案:
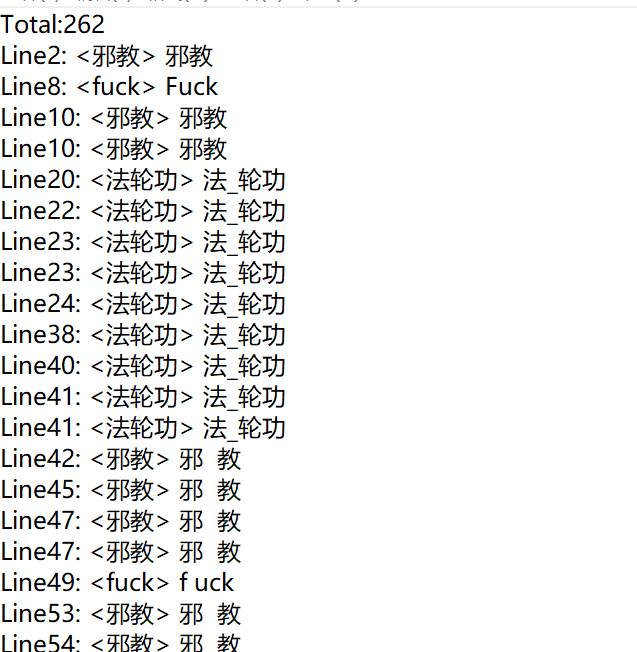
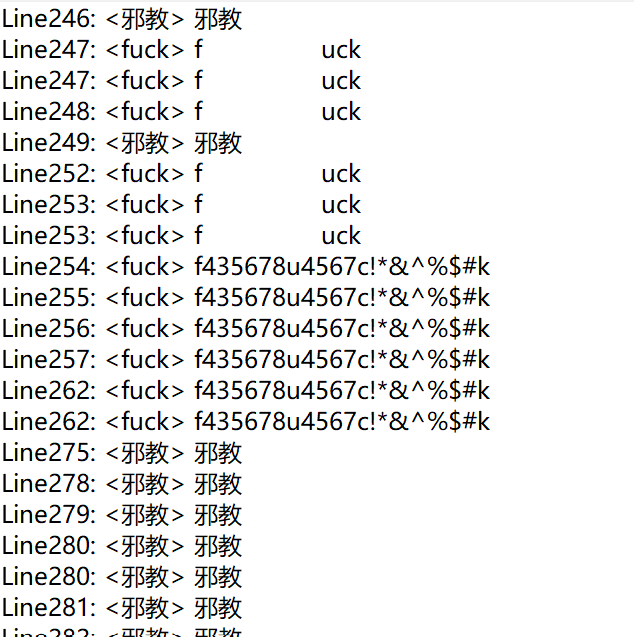
示例给出的答案:

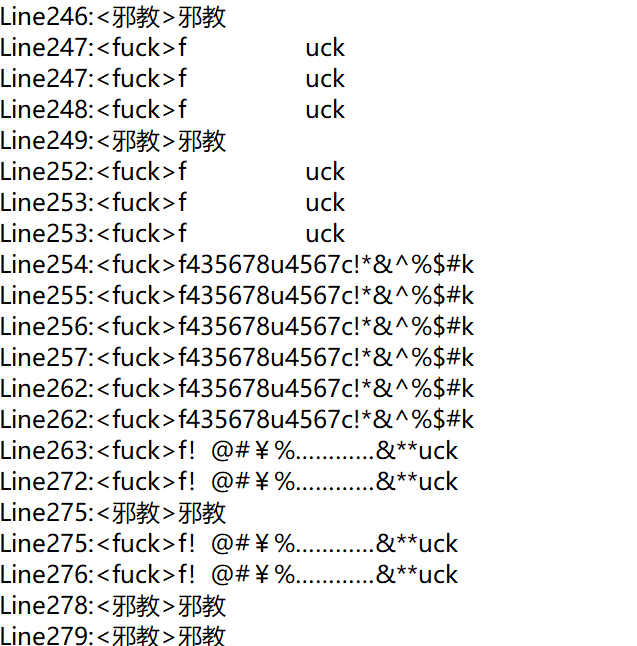
代码并没有完全实现,只找到262个敏感词,与目标有一定的差距,主要是对于同音字和相同偏旁的敏感词没有解决。
自己设计的测试样例
敏感词10个:

待测文本:

答案输出:
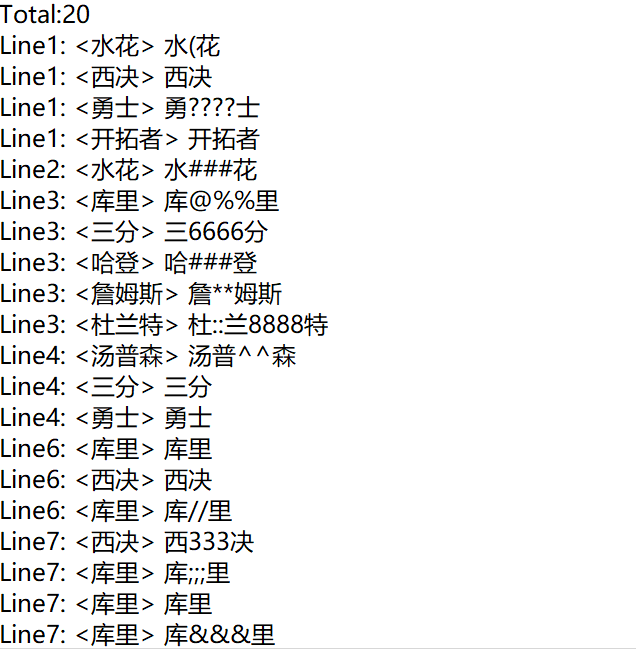
4.计算模块部分异常处理说明。
遇到的困难以及解决方法和思路:
- 输出顺序不正确,一行中先出现的关键字没有先输出,而是错误地按照关键字文本中关键字排列顺序来输出。比如:关键字是fuck,awc;待测文本是awc_!fuck;输出则是:fuck awc(正确的应该是awc fuck);还有不知道如何先输出total行在输出每一行找到的关键字。
解决方法:应该桉顺序遍历待测文本中每个字,然后在每一次循环中去搜寻是否有对应关键字。将找到的关键字以及对应的行号用结构体数组保存,所有的关键字找完之后,就可以先输出total行,再输出结构体数组中储存的数据。 - 用c++读写text文件时遇到困难。
解决方法:学习了读写文件的语句,ofstream和ifstream等。 - 不知道怎么存储和输出中文,用string类型输出会变成符号。
解决方法:用wstring类型来存储数据,用wcin和wcout来输入输出。 - 用VS2019测试text文本读写功能时,出现了中文输出的乱码现象。
解决方法:将VS设置成utf-8编码,并且在main函数开始处加入语句:locale china("zh_CN.UTF-8");并使用locale头文件。
三、心得
1.这次作业对于我的心态和实践能力都是很大的考验,从最初的一头雾水,到同学给我提示,让我有了些思路,再到最后总结,花费了很多时间和精力,但也学习到很多东西,收获颇丰。
2.通过本次编程,我认识到自己掌握的编程语言太少,由于只能较熟练地使用C++,使得作业中有些要求无法实现(比如谐音敏感字的查找);同时我也认识到其他语言(如python)的优势,它们能够帮助我们更快更好地解决问题,后续我会抓紧学习新的语言,并希望自己能够熟练地掌握。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号