
oracle - b-tree算法
不妨先看一个题:
假设有几千几万个文件,该如何进行存储?
这个问题需要考虑几个问题:
- 给出一个文件名,我们如何快速找到文件?
- 这么多的文件,如果存放到一个文件夹,查找的效率非常低,我们如何分文件夹存放?
- 分文件夹之后,给出一个文件名,怎么知道放在哪个文件夹?
1、折半查找
首先我们能想到 “折半查找”,算法要求文件名有序,从小到大或者从大到小排列。
如果文件是放得乱七八糟,没任何规律,根本没办法套用算法公式,那就无所谓快速检索了。
因此我们得到一个基本的要求:要想实现检索,数据必须是有序的。
2、Hash分区
我们可以参考《新华字典》的做法,取汉字的首字母,字母相同的文件,就存放在同一个文件夹。
这种算法就是 hash 算法,没想到自己小学的时候,就已经会 hash 算法吧。
汉字的首字母不是很容易取,所以,算法还可以改进。
例如:一切数据都可以转换为 0 和 1,这样我们就可以截取前面 4 位,产生 0-15 的数字,我们可以根据这个数字进行分区存放。
哈希分区的问题:hash 分区扩容的成本非常高,文件已经分成 16 个分区,发现 16 个分区不够用,要扩展到 32 个,这时候所有的文件要重新确定存放位置。
(这种算法一般用于文件存储)
3、Hash表
hash 分区不方便扩容,如果一开始就创建了非常多的分区,不就不需要考虑分区容量了么?
就比如说,我们选用的 hash 算法用的是 MD5,经过计算会产生 128 位二进制数,这么多的分区总不至于不够用了吧。
是的,这么做就很像 Java 代码中的 HashMap,同样案例还有 mysql 中的 hash 索引。
就像百家姓,找一千人,肯定存在几个姓氏一样的。很明显,hash 算法下,不管弄了多少分区,必定会有一些数据,刚好落在同一个分区中。这种情况,专业名词叫 “哈希碰撞”。
那发生了 “哈希碰撞”,对于同一个区间内的数据,数据该如何去保存呢?
答案就是:链表,以下图为例,有 0、1、2、3 四个分区,896 和 496 刚好落在同一个分区。 要查找 896 这个数字,先通过 hash 算法,确定数据在第 0 分区,接着遍历链表,找到896。

哈希表的问题:链表结构没有对数据进行排序,会牺牲一定的检索性能。
(可能会产生疑问,为什么用链表,而不用数组呢?因为数据库不只有查询,还有删除和修改)
4、平衡树(B-tree)
任何数据都可以转换为 0 和 1,那么就可以比较大小,因此,还可以有这样一个方案:
MIN - m 的文件,存放在一个文件夹,m - n 的文件,存放在另一个文件夹,最后 n - MAX 的文件,再用一个文件夹。
如果有一天,m - n 文件夹存放的文件非常多了,我们还可以进行拆分,分成 m - x 文件夹,和 x - n 文件夹。
这是十分完美的方案,不论有多少文件,都可以进行扩展,而且不会出现某个文件夹,数据特别多的情况。
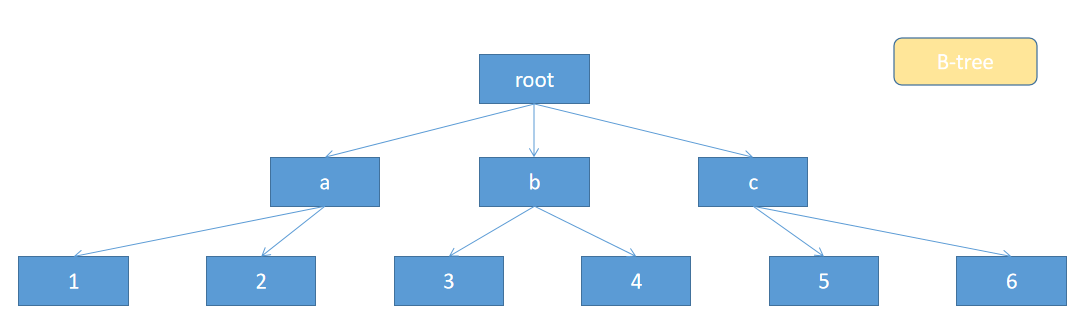
不过仍然存在一点点问题:
观察上面这张图,假设我们要找大于 2 小于 5 的数字, 根据设想,因为数据是有序的,我们只要找到 2,再找 5,再找 2 - 5 中间的数字就好了。
但是试着遍历这棵树,就发现不是这么回事,b 这棵子树,跟 a、c 两棵子树没任何联系, 找到了 2 和 5 这个节点,并不能直接知道 3 在哪里。
5、B+tree
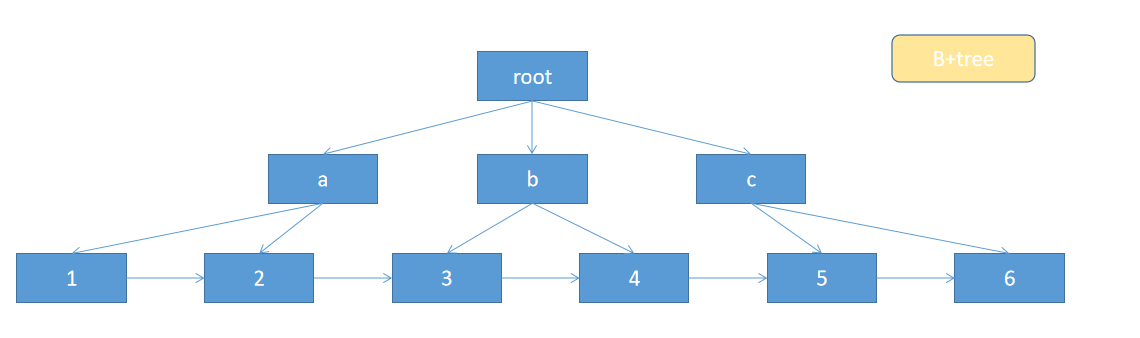
再去优化这棵树,平衡树 + 链表,产生下面这样的结果。
这样,数据检索过程中的树形结构遍历,就转为了链表遍历,解决了前面提到的遍历问题。
6、二叉树
一说到树,很容易想到二叉树,但凡学过计算机,多少有点了解,索引要是能用二叉树实现,那学习门槛得多低啊。
既然想到,就尝试实现一下,以下面这个图为例:比 11 大的,放在右边,比 11 小的,放在左边。
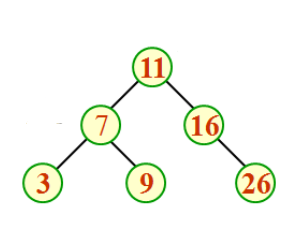
观察上面这个二叉树,能发现一个问题:左子树有 3 个节点,右子树只有 2 个,左右两边数据量不一样。
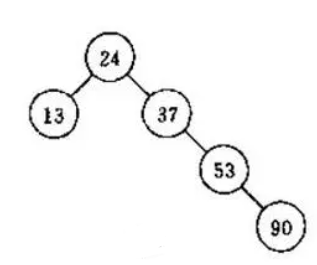
这个发现,听着有点像个大聪明,其实这确实是个大问题:现实生活中的数据,不会平均分布,往往集中在某个范围, 数据分布会变成下面这样,朝着某一边倾倒,某一些子树的高度显著高于其它子树,这样遍历性能就变得不稳定。
7.平衡二叉树、红黑树
1、面试的时候,经常会问:索引能不能用平衡二叉树,或者红黑树?
首先要了解概念:b-tree 就是 “平衡树”,红黑树属于 “平衡二叉树”,两个叉的平衡树自然会差一些。
这个问题经常出现在面试中,我们要认真想一个答案:
只考虑算法本身,红黑树和平衡二叉树,理论上都是可以用来做索引的,但是相比于 b-tree 会更弱势一些, b-tree 的每一个节点,能拥有更多的子节点,这样能有效地降低树的高度,节点的总个数也会降低,最终的检索性能也会更好。
2、换一个问题,普通平衡二叉树和红黑树,谁会更适合做索引呢?
只考虑查询的话,其实都可以,没太大区别,非要说区别就是,普通平衡二叉树,子树高度差不超过一。
发生新增和删除时,节点数量发生变化,要保持树的平衡,需要调整树的结构,这时候,两种树的差别非常大。
普通二叉树通过旋转实现平衡,而红黑树有的时候,有时候可以不旋转,改变节点颜色即可。
(普通二叉树旋转,看起来很容易理解,但是尝试通过代码实现,就会发生很难将算法转换成代码。)
总结
上述的案例,已经解释了b+tree的基本原理,
根据算法特点,可以解释 Oracle 中的很多现象:
- in,>,<,=,between 为什么能用到索引?因为数据是有序的,只需要快速找到一个数据, 在它之后就比它大,之前的就比它小。其中 > 和 < 与数据量相关,结果集很大的时候,直接查全表可能会比索引快;
- 半模糊查询(like 'xxx%')能用到索引,这是因为数据的前面一半存在,这样是可以排序的, 以人名为例,知道你姓钱,按照百家姓排序,你就排在前面;
- not in, <>, != 如果只是判断记录是否存在,走索引可以说得通,但是从查询上看, “不等查询” 的查询结果,要占所有记录的大多数,全表检索效率更高;
- is null,因为 null 值无法计算,你不能往文件夹,放置一个不存在的文件,b-tree 不存储为空的值,所以不走索引;
- is not null,具体走不走索引,还是得看执行计划,原理上看可以走索引,is not null 等于查询索引中的全部数据,但是考虑到非空数据比例很高,查询全表可能更快,具体什么情况,得看 Oracle 设计师怎么想了;
- 调用函数的情况:where to_number(id) = 1, 很明显,这种情况下,索引压根没存储 to_number(id) 之后的值,没办法进行检索;
- 隐式转换:比如 id 是字符串,where id = 1,此时 1 是数字,需要数字转为字符串之后,才能比较, 这样不走索引,因为索引中存储的是原本的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号