
机器学习是什么

一、机器学习是什么
机器学习是计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的学科。
机器学习是专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习是人工智能的核心,从大量现象中提取反复出现的规律与模式,是使计算机具有智能的根本途径。
二、常见概念

属性
被描述的性质叫属性,不同属性值有序排列得到的向量就是数据,也叫实例
例如:人的属性有肤色、眼睛大小、鼻子长短、颧骨高度,属性值可以描述为浅、大、短、低
特征空间
每个属性都代表了一个不同的维度,这些属性共同构成了特征空间
特征向量
每一组属性值的集合都是这个空间中的一个点,因而每个属性实例都可以视为特征空间中的一个向量,叫特征向量。
误差
学习器的预测输出与样本真实输出之间的差异,是机器学习的重要指标之一
- 训练误差
学习器在训练数据集上的误差,也叫经验误差 - 测试误差
学习器在新样本上的误差,也叫泛化误差。
反映了学习器对未知的测试数据集的预测能力,是机器学习中非常重要的概念
拟合
观测结果的数字统计与相应数值组的吻合
- 过拟合
预测规律与训练数据收集过于符合。
例如,刚好看到有肌肉的程序员,以为有肌肉的都是程序员,把训练数据的特征当做整体的特征。
一般是学习时模型包含的参数过多,导致训练误差较低但测试误差较高 - 欠拟合
模型不能在训练集上获得足够低的误差。
例如,把黒猩猩的图像认成了人
测试误差与模型复杂度之间呈现的是抛物线的关系。
- 当模型复杂度较低时,测试误差较高
- 随着模型复杂度的增加,测试误差将逐渐下降并达到最小值
- 当模型复杂度继续上升时,测试误差会随之增加,对拟合的发生
模型
机器学习模型,本质上是一个函数,作用是从一个一个样本\(x\)到样本的标记值\(Y\)的映射,即\(Y=f(x)\)
模型需要在给定样本集合\(\{{x_i|i=1,...,n}\}\)以及对应标签\(<Y_1,Y_2,...,Y_n>\)情况下,用假设已知的函数形式\(Y=f(x_i)\)尽可能拟合客观存在的映射函数,并保证在未知分布上具有尽可能相近的拟合能力
如何得到最优模型?
如果将训练集分成10个子集\(D_{1-10}\),交叉验证需要对每个模型进行10轮训练
- 第1轮使用\(D_{2-10}\)这9个子集,训练出的学习器在\(D_1\)进行测试
- 第2轮使用\(D_1\)和\(D_{3-10}\)这9个子集,训练出的学习器在\(D_2\) 上测试
- ...
直到10个模型测试完成,不同模型中平均测试误差最小的模型就是最优模型
调参
对算法参数进行设定,是机器学习中重要的工程问题,在神经网络与深度学习中的体现尤为明显。
调参过程中,主要问题就是性能和效率之间的折中。
正则化
为了解决过拟合问题,通常有两种办法,第一是减少样本的特征(即维度),第二就是我们这里要说的“正则化”(又称为“惩罚”,penalty)。
正则化是一种为了减小测试误差的行为(有时候会增加训练误差)。
我们在构造模型时,最终目的是让模型在面对新数据时,能有很好的表现。
如果使用比较复杂的模型,比如神经网络去拟合数据时,很空间出现过拟合现象(训练集表现很好,测试集表现较差),这时,我们就需要使用正则化,降低模型复杂度。
预测类型
- 分类问题
输出变量有有限个离散变量,个数为2时叫二分类问题 - 回归问题
输入和输出变量均为连续变量 - 标注问题
输入和输出变量均为变量序列
三、算法分类
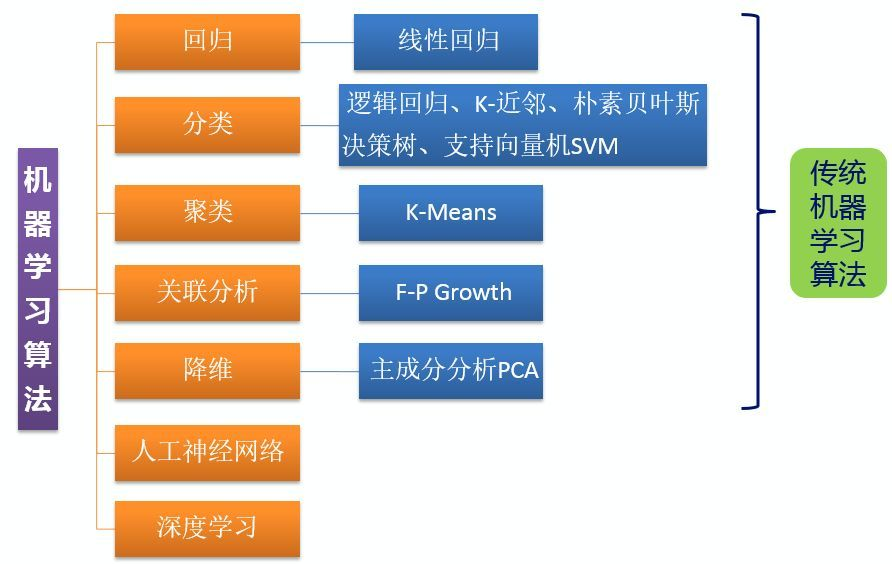
传统机器学习算法主要包括以下五类:
回归
建立一个回归方程来预测目标值,用于连续型分布预测
分类
给定大量带标签的数据,计算出未知标签样本的标签取值
聚类
将不带标签的数据根据距离聚集成不同的簇,每一簇数据有共同的特征
关联分析
计算出数据之间的频繁项集合
降维
原高维空间中的数据点映射到低维度的空间中
四、学习方式(监督与无监督)

-
监督学习
基于已知类别的训练数据进行学习 -
无监督学习
基于未知类别的数据进行学习 -
半监督学习
同时使用已知类别和未知类型的训练数据进行学习
受学习方式的影响,效果较好的算法执行的都是监督学习的任务。
监督学习的两种方法
监督学习的任务就是在假设空间中根据特定的误差准则找到最优的模型,可以分成两类方法
- 生成方法
根据输入和输出数据之间的联合概率分布确定条件概率分布\(P(Y|X)\),表示了输入\(X\)与输出\(Y\)之间的生成关系。
典型算法是朴素贝叶斯 - 判别方法
直接学习条件概率分布\(P(Y|X)\)或决策函数\(f(X)\),这种方法表示了根据输入\(X\)得出输出\(Y\)的预测方法。
典型的算法是逻辑回归
即使是AlphaGo Zero,训练过程也要受围棋胜负规则 的限制,因而也离不开监督学习的范畴。
所以,监督学习是目前机器学习的主流任务。在图像识别领域,高识别训练场的背后是大量被精细标记的图像样本,而对百万的数字图像进行标记需要有耗费大量人力,这就是一种监督学习。
生成方法具有更快的收敛速度和更广的应用范围,判别方法具有更高的准确率和更简单的使用方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号