JS正则表达式实战:核心语法解析
JS中的正则表达式实例集锦:
| 部分 | 语法类型 | 核心含义 |
|---|---|---|
/.../ |
定界符 | 正则表达式的边界标识(JavaScript/Perl 等语言的标准写法),包裹正则主体。 |
\. |
转义字符 | 匹配字面量的点号 .。⚠️ 重点:正则中 . 是通配符(匹配任意单个字符),必须用 \ 转义才能匹配实际的 .。 |
() |
分组符 | 正则的 “分组” 语法,作用是:1. 把括号内的内容视为一个整体;2. 捕获匹配到的内容(可通过 $1/$2 等引用);⚠️ 这里括号内是空的,意味着 “匹配空内容”。 |
$ |
锚点 | 匹配字符串的结束位置,确保 $ 前面的内容必须出现在字符串最后。 |
| [ ] | 表示字符类 | 也叫字符集合。它的作用是:匹配方括号内的任意一个字符。 |
| | |
逻辑“或” |
它告诉正则引擎:匹配左边的模式,或者匹配右边的模式。只要满足其中任意一个条件,就算匹配成功。 |
匹配 / 不匹配示例
javascript
// 示例1:匹配 .txt 结尾的文件(把空分组换成 txt)
const reg1 = /\.(txt)$/;
console.log(reg1.test("note.txt")); // true
console.log(reg1.test("note.txt.bak")); // false(结尾不是 .txt)
// 示例2:匹配 .json 或 .yml 结尾的文件(分组内加或逻辑)
const reg2 = /\.(json|yml)$/;
console.log(reg2.test("config.json")); // true
console.log(reg2.test("docker.yml")); // true
console.log(reg2.test("data.csv")); // false?正则表达式
用法 1:匹配「前面的字符 / 分组」0 次或 1 次(最基础)
这是你之前在 woff2? 中看到的用法,也是最常用的。
- 语法:
字符?或(分组)? - 含义:表示它前面紧邻的那个字符 / 分组是「可选的」—— 匹配 0 次(没有)或 1 次(有)。
- 示例:
-
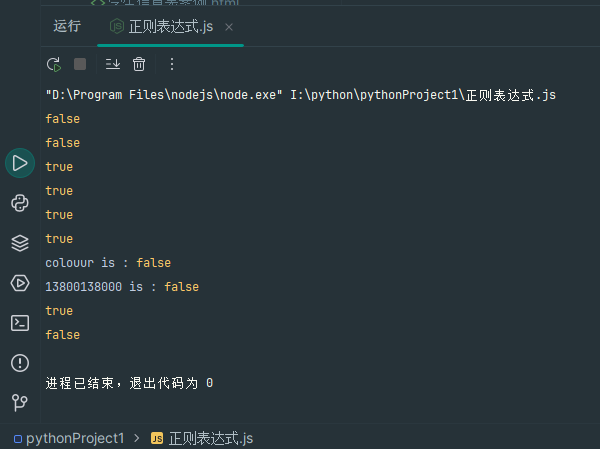
const reg = /^86?1[3-9]\d{9}$/; // 不带区号的 11 位手机号(正常场景) console.log(reg.test('13800138000')); // false console.log(reg.test('19912345678')); // false // 带 86 区号的手机号 console.log(reg.test('8613800138000')); // true console.log(reg.test('8617788990011')); // true // 示例1:匹配 color 或 colour(英式拼写) const reg1 = /colou?r/; console.log(reg1.test('color')); // true(u 出现 0 次) console.log(reg1.test('colour')); // true(u 出现 1 次) console.log('colouur is :',reg1.test('colouur'));// false(u 出现 2 次) // 示例2:匹配手机号(可选带区号 86) const reg2 = /^86?1[3-9]\d{9}$/; console.log('13800138000 is :',reg2.test('13800138000')); // false(86 出现 0 次) console.log(reg2.test('8613800138000')); // true(86 出现 1 次) console.log(reg2.test('88613800138000'));// false(86 多了个 8)![]()
用法 2:将「贪婪匹配」转为「非贪婪匹配」(重要)
正则默认是「贪婪模式」(尽可能多匹配),
?加在*/+/?/{n,m}后,会变成「非贪婪模式」(尽可能少匹配)。 - 语法:
*?/+?/??/{n,m}? - 含义:匹配到满足条件的「最短内容」就停止。
- 示例:
javascript
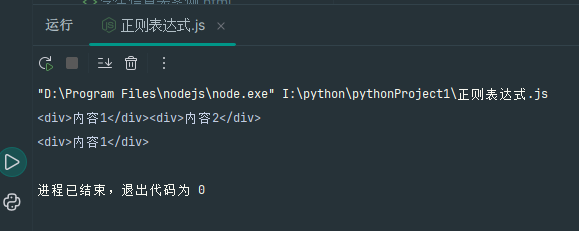
const str = '<div>内容1</div><div>内容2</div>'; // 贪婪匹配(默认):匹配从第一个 <div> 到最后一个 </div> 的所有内容 const regGreedy = /<div>.*<\/div>/; console.log(str.match(regGreedy)[0]); // 输出:<div>内容1</div><div>内容2</div> // 非贪婪匹配(加?):匹配第一个 <div> 到最近的 </div> const regNonGreedy = /<div>.*?<\/div>/; console.log(str.match(regNonGreedy)[0]); // 输出:<div>内容1</div>
用法3:[]的使用示例
let str = 'Is this all there is?';
let part = /[a-h]/g; // 带 g
console.log(str.match(part)); // ['h', 'a', 'h', 'e', 'e']运行结果如下:

带 g:match() 返回所有匹配的字符串组成的数组(但不包含额外信息)。
let str = 'Is this all there is?';
let part = /[a-h]/;
console.log(str.match(part));这段代码去掉了g,运行结果如下:

不带 g:match() 只返回第一个匹配结果(以及额外信息如 index、input 等)。
g 不影响匹配规则本身,只影响“是否找完所有匹配”。
- 匹配哪些字符,由
[a-h]决定(仅小写 a–h)。 g只决定“找一个还是找全部”。
|正则表达式用法:
1. 核心含义
它告诉正则引擎:匹配左边的模式,或者匹配右边的模式。只要满足其中任意一个条件,就算匹配成功。
2. 工作原理(短路逻辑)
正则引擎通常是从左到右进行尝试的:
- 先尝试匹配
|左边的部分。 - 如果左边匹配成功,则直接接受该结果,不再尝试右边的部分(即使右边也能匹配)。
- 如果左边匹配失败,才会去尝试
|右边的部分。
3. 代码示例
示例 A:基础用法
const regex = /cat|dog/;
console.log("I have a cat".match(regex));
// 输出: ["cat"] (匹配到了 cat)
console.log("I have a dog".match(regex));
// 输出: ["dog"] (cat 没匹配到,尝试 dog,成功了)
console.log("I have a bird".match(regex));
// 输出: null (两个都没匹配到)示例 B:
(chenlight注:下面过程中展示的思路很清晰,且明白!)
假设字符串是
"10+20":- 正则:
/\d+|\+/ - 过程:
- 遇到
"10":\d+匹配成功。结果是"10"。 - 遇到
"+":\d+匹配失败(因为不是数字),引擎尝试|后面的\+,匹配成功。结果是"+"。 - 遇到
"20":\d+匹配成功。结果是"20"。
- 遇到

 浙公网安备 33010602011771号
浙公网安备 33010602011771号