python3网络爬虫开发实战 第2版 4.1TEXT文本文件存储的代码错误
先看一下书中代码原文:
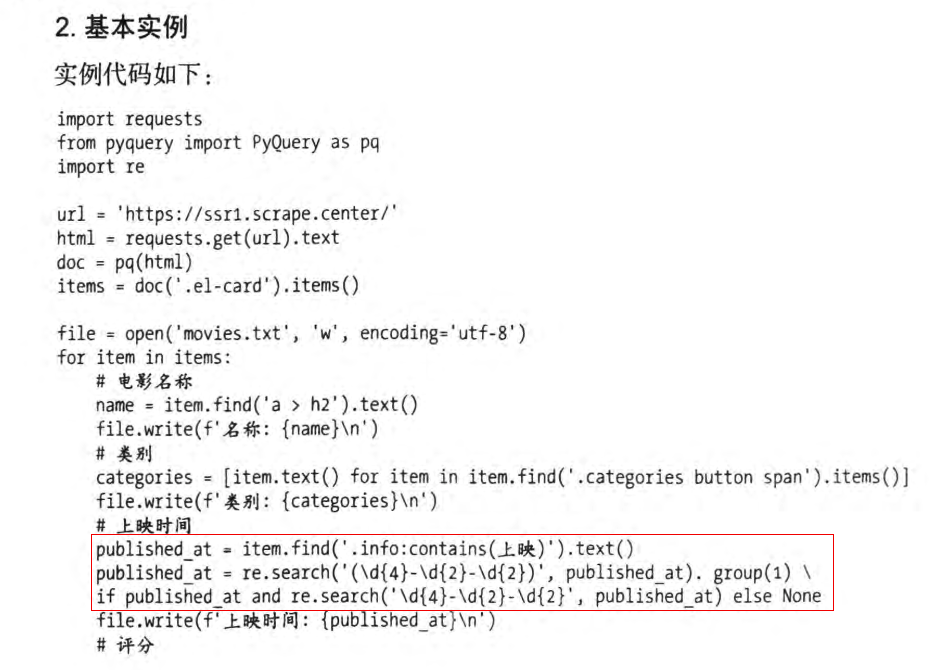

按照原书中代码输入后,错误提示如下:
I:\python\text文本存储.py:19: SyntaxWarning: invalid escape sequence '\d' published_at = re.search('(\d{4}-\d{2}-\d{2})',published_at).group(1) if published_at and re.search('(\d{4}-\d{2}-\d{2})',published_at) else None Traceback (most recent call last): File "I:\python\text文本存储.py", line 13, in <module> file.write(f'名称:{name}\n') ValueError: I/O operation on closed file.
第一个错误 :
问题 1:正则表达式中的转义警告
re.search('(\d{4}-\d{2}-\d{2})', published_at)在普通字符串中,\d 会被 Python 解释为“无效转义序列”,虽然 re 模块仍能正确识别(因为 \d 在正则中是合法的),但会发出 SyntaxWarning。
✅ 解决方法:使用 原始字符串(raw string),即在字符串前加 r:
re.search(r'(\d{4}-\d{2}-\d{2})', published_at)问题 2:文件提前关闭
在 for 循环内部调用了 file.close(),导致第一次写入后文件就被关闭了。
后续再尝试写入就会抛出错误(注意,书中明显是将file.close()写在与file.write()平齐的位置)
ValueError: I/O operation on closed file.✅ 解决方法:将 file.close() 移到循环外面,或者更好的做法是使用 with open(...) as file: 上下文管理器自动处理文件的打开和关闭。
修正后的代码如下:
import requests
from pyquery import PyQuery as pq
import re
url = 'https://ssr1.scrape.center/'
html = requests.get(url).text
doc = pq(html)
items = doc('.el-card').items()
file = open('movies.txt','w',encoding='utf-8')
for item in items:
name = item.find('a >h2').text()
file.write(f'名称:{name}\n')
categories = [item.text() for item in item.find('.categories button span').items()]
file.write(f'类别:{categories}\n')
published_at = item.find('.info:contains(上映)').text()
print(published_at)
published_at = re.search(r'(\d{4}-\d{2}-\d{2})',published_at).group(1) if published_at and re.search(r'(\d{4}-\d{2}-\d{2})',published_at) else None
file.write(f'上映时间:{published_at}\n')
score = item.find('p.score').text()
file.write(f'评分:{score}\n')
file.write(f'{"="*50}\n')
file.close()
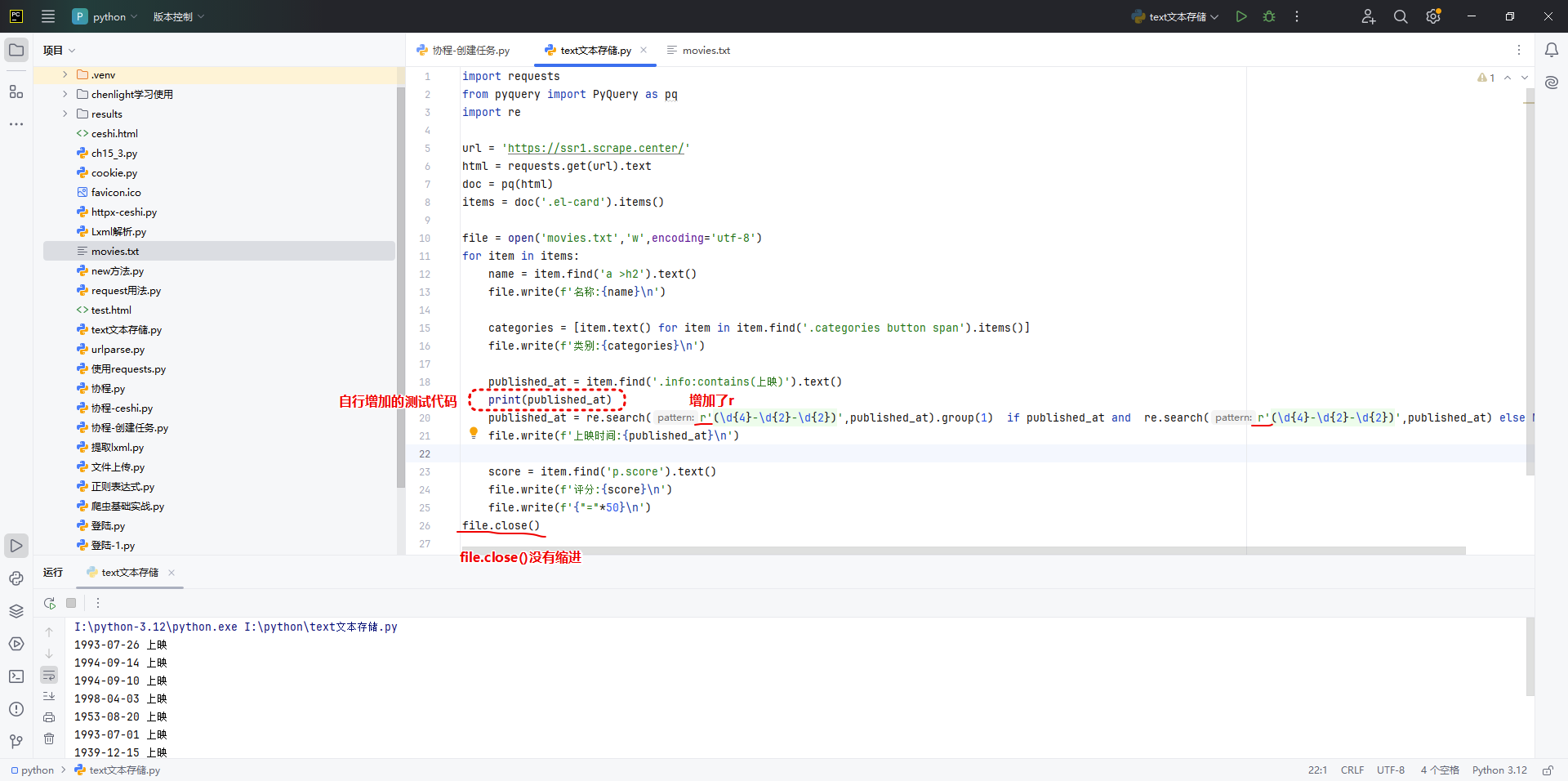
运行效果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号