c++常见关键字总结
前言
本系列是对常见的重要c++关键字的备忘录,也许未注意到某些用法,但会不断完善
const
const的作用:被const修饰的值理论上不能改变,为只读语义,且因为创建后const对象无法改变,需要在定义阶段必须为他赋初值,初值可以任意复杂的表达式
但const并非完全不能改变,在定义变量时加上volatile关键字,可以通过指针间接修改。这是因为加上volatile编译器不会进行优化,以下例子中*pt和a都是从堆栈也就是内存中取值;而不加上volatile,编译器将进行优化,节省访问内存的时间,输出a的值时将直接从符号表取出(在后面会提到volatile关键字,作用是告诉编译器不要对此句进行优化,每次都去内存取值)
volatile const int a = 1;
int* pt = (int*)(&a);
*pt = 100;
默认情况下,const对象仅在文件内有效,多个文件出现了同名的const对象,相当于在不同文件中分别定义了独立的对象
不能使用字面值初始化一个非常量引用.因为引用是变量的别名
int& a = 0; //错
const int& b = 1; //对
指针常量(顶层const)表示指针本身是个常量,一旦指定了对象,便不可改变,且指针必须在定义时初始化
int a = 0;
int b = 1;
int* const pt = &a;
pt = &b; //错
*pt = 1; //对
常量指针(底层const)定义一个指针,该指针不可以修改其所指对象的值
int a = 0;
const int* p1 = &a;
int const* p1 = &a;
*p1 = 10; //错
a = 10; //对
- 函数
当形参为const时,实参可传入const类型,也可传入不为const类型
void fcn( const int i )
{
i = 2; //错
}
int a = 0;
const int b = 1;
fcn( a ); //对
fcn( b ); //对
一个拥有顶层const的形参无法和没有顶层的const的形参区分开,因此当传入区别只是是否为const类型的对象时,这两个函数无法重载。但如果形参是引用或指针且const为底层,则可以区分
//顶层const,两个函数等价
int func1( A );
int func1( const A );
//底层const,两个函数重载
int func1( A* );
int func1( const A* );
- class
const class对象不可以调用非const成员函数,而非const class对象可以调用const成员函数:因为this指针是指针常量(A* const this),class对象无法改变成员变量
const A a;
//func为a中的非const成员函数
a.func(); //错
在class的成员函数参数带有一个隐藏的this指针且该指针是指针常量,若在参数后面跟一个const,这个指针不仅是指针常量,还是常量指针
class A
{
public:
int intFunc() const { return i1 };
private:
int i = 0;
}
类的成员函数返回*this,若返回类型为&类对象且成员函数为const,不可以用该成员函数的返回值对象调用其他要改变类对象的值的函数,因为该成员函数的返回类型为常量对象
class A
{
public:
A& set( char c )
{
//改变类对象的成员的值
return *this
}
A& display() const
{
//展示类对象的成员
return *this;
}
}
//调用
A a;
a.display().set('c'); //错,因为此时display返回的常量对象,而set会修改对象的成员的值
可以对const成员函数进行重载
//对.const成员函数可以重载
void func1() const;
void func1();
//调用非const版本
A a;
a.func1();
const A ca;
ca.func1(); //调用const版本
若const成员函数返回类型是引用类型,则该返回类型必须是const引用
class A
{
public:
int& func1() const { return val; } //错,这里this指针为常量指针,而返回值非常量
private:
int val = 1;
}
构造函数不可以声明为const。因为构造函数是用来初始化对象的,若为const则无法修改成员变量。但若想要修改const成员函数中某些与class状态无关的数据成员,可以使用mutable关键字
class A
{
public:
A() const; //错
A(); //对
}
static
作用:实现多个对象之间的数据共享和隐藏,且使用静态成员还不会破坏隐藏原则
默认初始化为0
static修饰的变量和函数存储在静态区
static修饰的变量和函数只能在当前模块使用,不可被其他模块使用,即使是extern也不行
const和static的区别:
- 常量
const超过作用域后会被释放,定义时必须初始化且后续"无法更改"
函数执行后static所修饰的常量不会被释放 - 成员变量
const只在class对象的生命周期为常量,不能赋值,不能在class外定义.因为不同的class对象对其const成员的值可以不同,所以不能在class中声明时初始化,只能通过构造函数初始化列表初始化
由static修饰的在class中的成员对象想要进行初始化必须为常量,否则只能进行声明。若声明在class中,在class外初始化时不可以带static。无论创造多少个类对象,静态成员只有一个副本 - 成员函数
(const成员函数在之前讲过)
static成员函数不可访问非静态数据成员和调用非静态成员函数,因为没有this指针。是一个callback函数,不可被声明为const、volatile、virtual,不需要经由类对象调用
volatile
volatile与const对立,表明该变量随时可能变化,不会对该关键词修饰的变量进行编译优化。从内存中重新装载,而不是直接从寄存器拷贝,可以提供对特殊地址的稳定访问
对于一个普通变量,为提高存取速率,编译器会先将变量的值存储在一个寄存器中,以后再取变量值时,就从寄存器中取出;而volatile是从内存中重新读取也就是堆栈区
//例子一
int i = 10;
int a = i;
printf("i = %d", a);
// 下面汇编语句的作用就是改变内存中 i 的值
// 但是又不让编译器知道
__asm {
mov dword ptr [ebp-4], 20h
}
int b = i;
printf("i = %d", b);
//debug结果为 a = 10, b = 32;release结果为 a = 10, b = 10
//例子二
volatile int i = 10;
int a = i;
printf("i = %d", a);
__asm {
mov dword ptr [ebp-4], 20h
}
int b = i;
printf("i = %d", b);
//两个版本结果都为 a = 10, b = 10
用处:
- 中断服务程序中修改的供其它程序检测的变量需要加volatile
- 多任务环境下各任务间共享的标志应该加volatile
- 存储器映射的硬件寄存器通常也要加volatile说明,因为每次对它的读写都可能由不同意义
- 在中断服务程序和cpu相关寄存器的定义
可以把一个非volatile对象赋给volatile对象,但是不能把非volatile对象赋给一个volatile对象
指针
指针所指对象为volatile
volatile int* pt;
指针为volatile
int * voliate pt;
extern
extern声明在函数或文件外部定义的全局变量或函数,告诉编译器此变量或函数在模块外,编译器会将这些变量或函数放于重定位表中,将任务交给链接器在链接时完成
用法:
- extern"C"
c++为和c兼容,用到了extern"C":c++编译器会将大括号内的代码当作c语言标准去处理,意味着与C语言的文件进行链接。extern"C"中的符号都是修饰后的符号,也就是说不需要进行符号修饰(若不知道请看静态链接 - 爱莉希雅 - 博客园 (cnblogs.com))
extern "C"
{
static int i;
#include<string.h> //链接可以嵌套
}
单独声明某个函数或变量为c语言的符号
extern "C" int func(int);
extern "C" int var;
也可以定义指向extern"C"函数的指针
//pf为指向C风格函数的指针
extern "C" void (*pf)(int);
extern"C"不仅对函数有效,对返回类型或形参类型的函数指针也有效
//f1为c风格函数,形参是一个指向c风格函数的指针
extern "C" void f1( void(*)(int) );
若想给c++函数传入传入一个指向c的指针则需要用到类型别名typedef
extern "C" typedef void FC(int); //FC为c风格指针
void f2(FC *);
通过extern"C"对函数进行定义,可以令c++函数被c使用
extern "C" double func( double para1 )
{
//...
}
有时候我们会碰到头文件声明了c语言的函数或全局变量,但是这个头文件可能会被c++包含,导致认为这些函数或全局变量是c++版本的,而c语言并不支持extern"C",这个时候我们就需要用到c++的宏"__cplusplus"
//memset为重复的函数
#ifdef __cplusplus
extern "C"
{
#endif
void* memset( void*, int, size_t );
#ifdef __cplusplus
}
#endif
//c++中等价于
extern "C"
{
void* memset( void*, int, size_t );
}
//c中等价于
void* memset( void*, int, size_t );
-
当extern不在跟"C"时,表示声明在函数或文件外部定义的全局变量或函数,告诉编译器此变量或函数其他模块中
在使用extern时候要严格对应声明时的格式
//以下例子会报错,因为arr定义为数组,而在B中被声明为指针类型,指针并不等价于数组 //A模块 char arr[6]; //B模块 extern char* arr; //不合法。报错 //修改 extern char arr[];
extern不可和static搭配使用。我们知道static修饰的变量或函数定义只对当前模块有效,而extern是声明其他模块的变量或函数,因此这两个家伙可谓是水火不容
extern static int i = 2; //不合法
extern可以和const搭配使用,声明该常量作用于其他模块
//A
const int = 2;
//B
extern const int i; //合法
constexpr
字面值:一个不能改变的值,如数字、字符、字符串等。单引号内的是字符字面值,双引号内的是字符串字面值
字面值类型:类型简单、值显而易见。算数类型、引用、指针,自定义类不是
文本类型:可在编译时确定其布局的类型。以下均为文本类型
- void
- 标量类型
- 引用
- Void、标量类型或引用的数组
- 具有普通析构函数以及一个或多个 constexpr 构造函数且不移动或复制构造函数的类。 此外,其所有非静态数据成员和基类必须是文本类型且不可变
常量表达式:值不会改变且在编译时就可以得到计算结果的表达式(编译阶段有个叫生成中间语言的步骤)。字面值属于常量表达式,而非常量表达式只能在运行期计算出结果
用处:在编译阶段计算出结果,极大地提高了执行效率。因为表达式在编译阶段计算出了结果,就可以不用再每次运行时来计算,这肯定是节约了时间
const int a = 20; //是
const int b = a + 1; //是
int c = 1; //不是,c为常量,但是其值可以改变
const int d = getsize(); //不是,因为其值在运行期才可获得
constexpr:系统很难分辨一个初始值是否为常量表达式,但用constexpr类型声明的变量可以由编译器来验证变量的值是否是一个常量表达式,使这些常量表达式在编译期就可以计算得到结果。可以得出constexpr 只能定义编译期常量
作用范围:可作用于变量、函数(包括模板函数)、class的构造函数
将⼀个函数标记为constexpr的同时,也将它标记为const。如果将⼀个变量标记为 constexpr,则同样它是const的。但相反并不成⽴,⼀个const的变量或函数,并不是 constexpr的
当满足以下两个条件时,引用可以被声明为 constexpr:引用的对象是由 constant(常数)常数表达式初始化的,初始化期间调用的任何隐式转换也是 constant(常数)表达式
注意:即使一个常量表达式被constexpr修饰,拥有在编译阶段计算得出结果的能力,但这并不代表它一定就能在编译阶段被执行,是否执行由编译器说了算
优点:
- 为不能修改数据提供保障
- 有些场景,编译器可以在编译期对constexpr的代码优化,提高效率
- 相⽐宏来说,没有额外的开销,但更安全可靠
形式:使用 constexpr 变量时,变量必须经过初始化且初始值必须是一个常量表达式
constexpr int n = 1 + 2; //n为整型常量.若将constexpr去掉,第二行会报错,因为去掉后n为变量非常量
int array[n] = { 1,2,3 };
- 指针
将constexpr作用于指针,会将指针设定为指针常量,而非常量指针,也就是说constexpr只对指针生效,和所指对象无关
const int* p = nullptr; //p为常量指针
constexpr int* q = nullptr; //q为指针常量
constexpr指针不可以指向定义在函数体内的局部变量,因为这些变量并非存放在固定地址,进入函数作用域会初始化它们,离开函数作用域则销毁它们;相对的,对于那些定义在函数体之外的变量和局部静态对象,因为其生命周期是从初始化到程序终止,其地址并不会改变,所以constexpr指针可以指向他们
- 函数
constexpr函数是在使用需要它的代码时,可在编译时计算其返回值的函数
constexpr函数规则:
- 只接受并返回文本类型,返回值不能是void
- 函数体不能声明变量或定义新的类型
- 在形参实参结合后,return语句中的表达式为常量表达式
- 可以是递归的
- 正文不能包含任何 goto 语句或 try 块
要想constexpr能在编译期通过,函数的返回类型和形参类型都必须为字面值类型,且函数中有且只有一条return语句,函数体内可以有其他语句,但只能包含在运行期不执行任何操作的,可以包含 using 指令、typedef 语句以及 static_assert 断言、空语句、null语句
如果其参数均为合适的编译期常量,则对这个constexpr函数的调用就可用于期望常量表达式的场合.如果参数的值在运行期才能确定,或者虽然参数的值是编译期常量,但不匹配这个函数的要求,则对这个函数调用的求值只能在运行期进行
允许constexpr的函数返回值不为一个常量,也就是说函数返回值不一定返回常量表达式
在初始化时,编译器把对constexpr函数的调用替换成其结果值,为了能在编译阶段随时展开,constexpr函数被指定为inline函数
constexpr函数可以多次定义,一般定义在头文件中
例子:
constexpr int func() { return 1; }
constexpr int a = func(); //a为常量表达式
//当我们为如下实例的func1传入为常量表达式的实参时,函数的返回值为常量表达式;若非常量表达式,则返回值也是非常量表达式
constexpr func1( size_t s ) { return a * s; }
int arr[func1(2)]; //对,func1(2)为常量表达式
int i = 1;
int arr[func1(i)]; //错,func1(i)不是常量表达式
- class
聚合类(代表类struct):
- 所有成员为public
- 没有定义任何构造函数
- 没有类内初始值
- 没有基类、虚函数
字面值常量类:除算术类型、引用和指针外,某些类也是字面值类型,这些类可能含有constexpr成员函数,这样的成员必须符合constexpr函数的所有要求
- 数据成员都必须为字面值类型
- 类至少包含一个constexpr构造函数,constexpr构造函数必须有⼀个空的函数体,即所有成员变量的初始化都放到初始化列表中。 对象调⽤的成员函数必须使用constexpr 修饰
- 若一个数据成员含有类内初始值,则内置类型成员的初始值必须是常量表达式;若成员属于某类类型,则初始值必须使用自己的constexpr构造函数
- 类必须使用默认的析构函数
之前我们说过构造函数不能为const,但字面值常量类的构造函数可以为constexpr
constexpr构造函数限制:
- 不能是虚函数
- 主体可以定义为 default 或 delete。否则必须既符合构造函数的要求不能包含return语句,又符合constexpr函数的要求,也就是说constexpr构造函数体一般为空
- 必须初始化所有数据成员,初始值或者使用constexpr构造函数,亦或是常量表达式
- 满足constexpr函数规则
nullptr
nullptr意为空指针,而空指针不指向任何对象,得到空指针最直接的方法是用特殊的字面值nullptr初始化指针
nullptr可以被转换成任意类型的指针
为什么引入nullptr? 在这之前我们可以用NULL定义为空指针,但在c和c++中NULL的含义并不相同,NULL不是关键字,而是一个宏定义,这意味着如果我们想要用NULL定义空指针,需要#include cstdlib
//在c中,定义NULL习惯被定义为void*指针值为0,也允许NULL定义为整型0
#define NULL (void*)0
//在c++中,明确定义NULL为整型0
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ( (void*)0 )
#endif
#endif
我们知道c++是兼容c的,那为什么这里没有完全兼容? 根本原因与c++的重载函数有关,如果支持void*隐式转换,会带来二义性
void foo( int i );
void foo( char* pt );
foo(NULL); //应该调用谁?
void fun(int* pt);
void fun(int);
foo(NULL); //本来是想调用第一个函数,但却调用的第二个函数
而nullptr可以隐式地被转换成任意指针类型,但不能转换为int这种类型
不可以用int赋值给指针,即使为0也不可以
//以下三种方式都可以定义为空指针,预处理器会将0和NULL预处理变量替换为实际值
int* pt1 = nullptr;
int* pt2 = 0;
int* pt3 = NULL; //需要#include cstdlib
//错误行为
int zero = 0;
pt1 = zero;
虽然以上三种方式都可以定义空指针,但最好是使用nullptr来定义,尽量避免NULL
define
#define 定义一个标识符来表示一个文本,是一个预处理指令,被称为宏定义
定义的标识符不占内存,只是一个临时的符号,也就是预编译(预编译相关的看这静态链接 - 爱莉希雅 - 博客园 (cnblogs.com))后这个符号就不存在了。一经定义,程序中就可以直接用标识符来表示这个文本
宏所表示的文本可以是数字、字符、字符串、表达式
可以定义在函数内,但一般与#include一起定义
作用域为自 #define 那一行起到源程序结束,如果要终止其作用域可以使用 #undef 命令
define num1 400 //num1常量的值为400
宏定义的好处? 既然宏定义是个常量,那为什么我不直接使用常量呢?定义宏岂不多此一举?
- 方便程序修改
- 易于维护
- 不分配内存,给出的为立即数,使用了多少次就进行多少次替换
可以将一个程序中使用频率次数较高的常量定义为宏,如此每次修改的常量的值时,不需要一个一个修改,只用修改一次宏定义常量就完事儿。另外,当常量较长时可以定义较短的标识符,来提高效率
宏定义如何执行? 之前说过预编译阶段会处理宏定义,那么是怎么处理的呢?预编译阶段只是会简单地替换文本而已,又称为宏展开,并没有类型检查,
typedef
类型别名:一个名字,某种类型的同义词。可以让复杂的类型名字变得简单明了易用
typedef 声明在其范围内引入一个名称,该名称为给定的类型的同义词,其作用和define差不多都是可以为已由语言定义的类型和对你已声明的类型构造更短或更有意义的名称,但区别较大.typedef在语法上是一个存储类的关键字(如auto、extern、mutable、static、register)
define:
- 只是简单的文本替换,没有类型检查
- 在编译的预处理阶段起作用
- 防止头文件重复引用
- 不分配内存,给出的为立即数,使用了多少次就进行多少次替换
typedef:
- 有对应的数据类型,要进行判断
- 在编译、运行期起作用
- 在静态存储区分配空间,在运行时内存中只有一个拷贝
形式:typedef 类型 别名
四个用法:
系统默认的所有基本数据类型都可以利用 typedef 定义别名,还可以使用这种方法来定义与平台无关的类型,跨平台极其方便只需修改typedef
typedef int num;
//支持long long
typedef longlong n;
//支持long,不支持long long
typedef long n;
//支持int,不支持long
typedef int n;
为自定义数据类型(结构体,枚举,共用体)定义别名
struct A;
struct A a; //调用。需要多写一个struct麻烦
typedef struct coordinate
{
//...
}A; //typedef coordinate A;
A a; //调用,无需struct
//需要注意的
typedef struct elysia
{
E ptE; //报错,因为现在结构体elysia并没有构建完成,编译器还不知道E的类型
}*E;
//可行的方案
typedef struct elysia
{
struct elysia* ptE;
}*E;
为数组定义别名
//下面两种定义表示的含义不同,第一种会将类型的有关信息记录下来,待以后定义该类型定义对象时使用;第二种则是直接分配空间
typedef int array[5];
int array[5];
为指针定义别名
typedef int* ptI;
ptI a; //a为int*指针
int* (*a[10])(int, char*);
typedef int*(*pFun)(int,char);
pFun c[10];
使用 typedef 声明的名称将占用与其他标识符相同的命名空间,其他标识符的隐藏名称规则也适用于 typedef 声明的名称的可见性
typedef int a;
int a; //重复定义
typedef int a;
int fun()
{
int a; //合法的
}
inline
inline告诉编译器用函数定义中的代码替换每个函数调用实例,也就是将内联函数编译完后 直接将函数体插入被调用的地方
inline int inlineFunc( int par1, int par2 ) { return par1 < par2 ? par1 : par2; }
//在调用inline函数的地方进行替换
std::cout << inlineFunc(5, 6);
std::cout << par1 < par2 ? par1 : par2;
inline只是向编译器发出了一个内敛请求,具体是否施行,根据编译器决定。因为若inline函数是个递归的,编译时无法证明它会不会无穷递归,将此函数进行inline会引起无穷的编译;且让inline作为提示在实现中也有优势,这可以使写编译器的人更容易处理"病态"情况,遇见它们就简单地不做inline处理
为什么要引入inline?因为在class中跨越保护屏障是有代价的,项目中某些class与实时处理有关,无法接受函数调用的开销,所以我们需要实现在跨越保护屏障时不付出任何代价这一目的,就引入了inline,具体做法是在类中对公有的函数进行声明,定义时修饰为inline
class A
{
public:
void func1();
};
inline void A::func1() { };
inline函数在整个程序中必须具有唯一的定义。若在其他编译单元定了同样的函数类型,会引起系统混乱。为什么会有这样的要求呢?因为inline函数通常和类一起定义在头文件中,而类声明在整个程序中也具有唯一性
inline的功能看着和define很类似,都是替换,但是inline比define优秀不少。让我们来看一个例子
//以下a的累加次数取决于其与谁做比较
#define fun( a, b ) f( (a) > (b) ? (a) : (b) )
int a = 5, b = 0;
fun( ++a, b ); //a累加两次
fun( ++a, b+10 ); //a累加一次
define定义这样的函数有两个很讨人厌的地方,必须为宏中所有实参加上小括号和函,而却很多时候不是向你想象的地方发展
幸运的是我们很快就能从泥沼脱身,我们可以用inline函数代替define定义的函数
这就引出一个话题,define和inline有何区别?
define
- 定义预编译时处理的宏,只是简单的字符串替换,无类型检查,不安全
inline
- inline函数先编译完后生成函数体,再直接插入被调用的地方,减少压栈,跳转,和返回的开销,相较于函数调用它的开销更小
- 会进行类型检查
- 对编译器发生请求,但编译器根据情况决定是否接受这个请求
看起来inline函数很香,但是inline函数也有限制:
- 不能存在任何形式的循环语句
- 不能存在过多的条件判断语句
- 函数体不能过于臃肿
- 内联函数声明必须存在于调用语句前
尽量使用inline函数替换#define宏定义函数;inline函数多用于优化规模较小、流程直接、频繁调用的函数
inline函数不可带有virtual。因为内联函数是指在编译期间由被调⽤函数体本身来代替的调⽤指令,但虚函数的多态特性需要在运行时根据对象类型才知道调用哪个虚函数,所以没法在编译时进⾏展开
auto
auto关键字指示编译器使用已声明变量的初始化表达式或 lambda 表达式参数来推导其类型
在平时编写程序时,有时并不知道表达式是什么类型,或者表达式类型长度过于长,多次编写费时费力,这时如果有助手能帮我们自动推导表达式的话那可再好不过了,auto就扮演着这样一名角色
auto i = 0; //推导为int
float a = 1.1;
auto j = a; //推导为float
auto k = a + i; //推导为float
可以使用说明符和声明符(如 const、volatile)、指针 (*)、引用 (&) 以及右值引用 (&&) 来修改 auto 关键字。但需记住auto声明的变量必须初始化
auto可以在一条语句声明多个变量,因为在一条语句只含有一个基本数据类型,所以该语句中所有变量的初始数据类型必须相同,切记&和*属于某个声明符,而非基本数据类型
auto i = 0, *p = &i; //合理
auto a = 0, b = 1.1; //不合理
当编译器推断出的auto类型与初始值类型并不完全相同时,编译器会适当地改变结果类型使其更符合初始化规则
auto并不代表一个数据类型,它只是一个占位符,不能对其使用以类型为操作数的操作符(sizeof)
std::cout << sizeof(auto) << std::endl; //此处不允许使用“auto”
引用
auto初始化引用时,初始化的依据是引用对象的类型
int i = 0, &r = i;
auto j = r; //j为int
auto一般忽略顶层const,保留底层const。若希望推断出的为顶层const,需明确指出。设置类型为auto引用时,初始值的顶层const仍然保留
const int ci = i, &cr = ci;
auto b = ci; //b为int,忽略顶层const
auto c = cr; //c为int
auto d = &i; //d为int指针
auto e = &ci; //e为const int的指针,对常量对象取地址为底层const
//明确指出const
const auto f = ci; //f为const int
//引用设为auto
auto& g = ci; //g为const int
auto& h = 1; //不合理。不能为非常量引用绑定字面值
const auto& j = 1; //合理
若表达式为数组,用auto&推导结果为数组类型
int array[3] = { 1, 2, 3 };
auto& Type = array;
std::cout << typeid(Type).name() << std::endl; //输出int [3]
指针
初始化数组时,auto推导类型为指针
int arr[3] = { };
auto Type = arr;
std::cout << typeid(Type).name() << std::endl; //输出int * __ptr64类型
在动态分配时,我们也可以使用auto,但只支持单个括号初始化器"()",不支持"{}"
int i = 0;
auto pti = new auto(i);
auto pt = new auto{i};
虽然可以用空括号对数组中元素进行值初始化,但不能用auto配合"()"或"{}"分配数组
int* pta = new int[10](); //合理
auto ptarr = new auto [10](); //不合理
函数和模板
函数和模板形参不可声明为auto
不可对函数返回语句为"{}"的初始化器进行推导
class
auto 不能作用于class中没有static修饰的成员变量
class A
{
const auto x = 1;
};
decltype
decltype类型说明符会自动推导表达式的类型,但不会计算表达式的值
也许你会疑惑,既然auto已经可以自动推导类型了,为什么还会多出个decltype?答案是有些场景下单一个auto不够用,程序员更多是在编写模板库时一起使用auto和decltype
decltype与auto的重要区别是decltype结果类型与表达式形式相关
语法: decltype( expression )
返回值:expression的类型
int var = 1;
decltype(var) j = 1; //j类型为int
const、引用、指针
decltype处理顶层const和引用与auto不同。若decltype使用的表达式为变量且含有const和引用,则不会忽略const和引用
const int ci = 0, &cj = ci;
decltype(ci) x = 0; //x为const int
decltype(cj) y = x; //y为const int&
decltype使用的expression不是变量,则返回expression对应的类型.若expression为解引用操作,将得到引用类型
int i = 1;
int* p = &i, & r = i;
decltype(r + 0) b; //返回类型不再是引用而是int
decltype(*p) c; //c为int&
struct A{ double x; }
const A* a = new A();
decltype((a->x)); //类型为const double&
对于decltype使用的expression,若expression加上多对括号(),编译时将会将其看作一个表达式,推导结果是引用类型;不加则推导结果时该变量的类型
decltype((i)) d; //d为int&
decltype(i) e; //e为int
若我们知道函数返回的指针将要指向哪个数组,则可以使用decltype声明返回类型。但decltype不负责将数组类型转换成对应的指针类型,因此若expression为数组,则结果是数组
int odd[] = {1};
int even[] = {2};
decltype (odd)* arrPtr( int i ) //为int [5]类型
{
return (i % 2) ? &odd :&even;
}
右值引用
const int&& fx();
decltype(fx()); //类型为const int&&
函数
配合auto使用追踪函数的返回值类型,但不可以对decltype(auto)进行修饰,如const、&等
auto func( int a, int b ) -> decltype( a + b )
{
return a + b;
}
decltype( auto ) func1( int a, int b ) { return a + b; }
模板
配合auto使用追踪模板函数的返回值类型
template<typename T, typename U>
auto func(T x, U y) -> decltype( x * y )
{
return x * y;
}
template<typename T, typename U>
decltype(auto) func(T x, U y)
{
return x * y;
}
overload和override
overload
overload为重载,表现形式是函数的名称相同但参数形式不同
规则:
- 不同的参数形式指的是不同的参数类型,不同的参数个数,不同的参数顺序
- 不可通过返回类型、异常、访问权限进行重载
- 函数的异常类型和数目不会对重载产生影响
override
override是重写一个函数以实现不同功能,用于子类继承父类时,重写父类函数
规则:
- 被重写的函数不可为private
- static函数不可被重写为非static
- 重写的访问修饰符一定要大于等于被重写函数的访问修饰符(public > protected > default > private )
使用override也就是多态,目的是为了避免父类含有大量重载函数导致臃肿,而难以维护
override和overload的本质区别是,使用了override修饰符的函数,此函数始终只有一个被你使用的版本
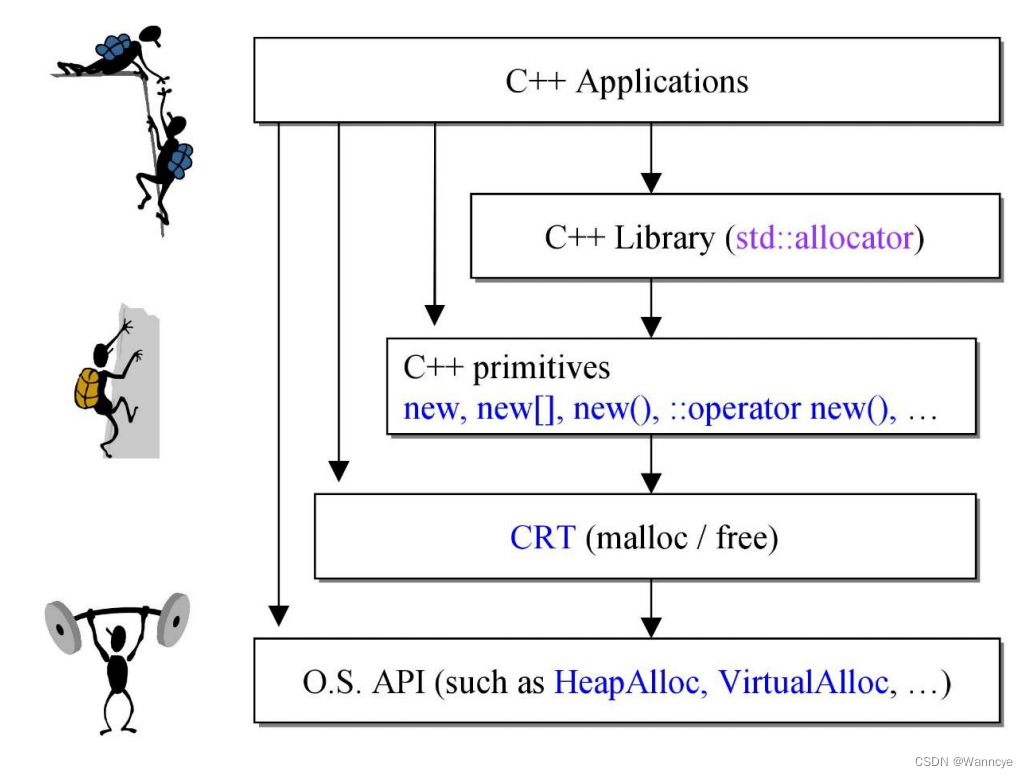
operator new和malloc
new和malloc的关系图
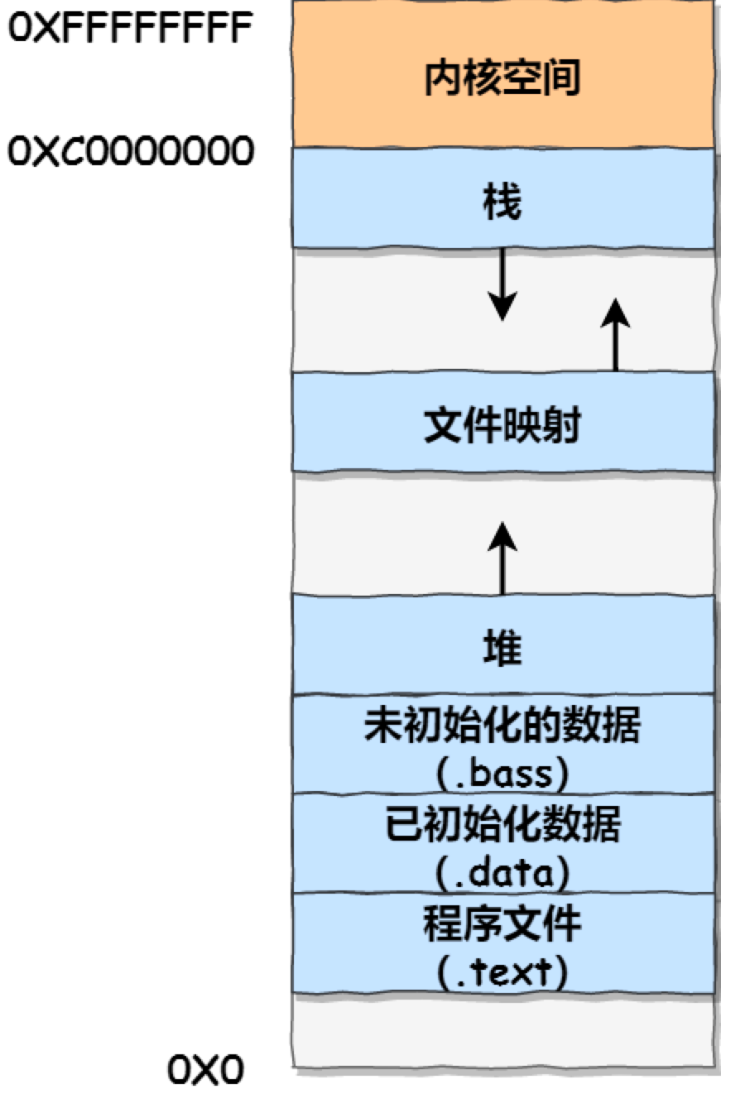
Linux的进程内存空间图:
malloc
头文件:stdlib
原型: extern void* malloc( unsigned int num_bytes )
返回值:若成功,则返回指向新分配内存的指针;若失败,返回NULL
ANSI C以前,没有void*这种类型,malloc函数的返回值定义为char*,char*是不能被赋予指向其他类型变量的指针的。所以在使用malloc函数时通常需要对其返回值进行强制类型转换
在ANSI C中,malloc函数的返回值为void*。void*类型是可以直接赋值给其他任何类型的指针。所以,强制类型转换操作现在已经不再需要
然而在c++中,任何类型的指针都可以赋给void*,而void*却不可以赋给其他类型的指针,所以在c++中使用malloc函数的时候,强制类型转换是必须的
malloc在堆上分配内存.操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的delete或free语句才能正确的释放本内存空间。我们常说的内存泄露,最常见的就是堆泄露(还有资源泄露),它是指程序在运行中出现泄露,如果程序被关闭掉的话,操作系统会帮助释放泄漏的内存
malloc申请内存时,会用两种方式去向操作系统申请堆内存:
-
通过 brk() 系统调用从堆分配内存,如果用户分配的内存小于 128 KB,则通过 brk() 申请内存。通过 brk() 函数将「堆顶」指针向高地址移动,获得新的内存空间。这种方式释放的内存不会归还操作系统(具体内容还请看后面讲的free)
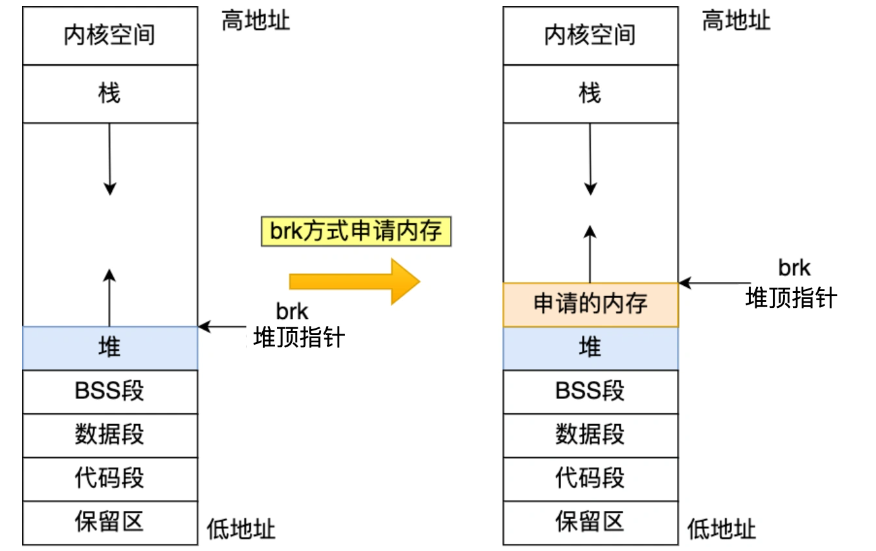
缺点:造成越来越多的碎片化内存。假设我们再一块连续的内存上分配了10kb和20kb的内存空间,若释放后这两个空间后,我们又可以分配30kb以下的内存空间,但若是大于30kb且后面空间是被使用了的,这会导致操作系统去其他地方申请内存,而这30kb的空间则被浪费了,随着频繁地申请内存空间,堆中将产生越来越多无法使用的碎片,导致内存泄漏,而且这种泄露是无法检测出来的
-
通过 mmap() 系统调用在文件映射区域分配内存,如果用户分配的内存大于 128 KB,则通过 mmap() 申请内存。通过 mmap() 系统调用中「私有匿名映射」的方式,在文件映射区分配一块内存,也就是从文件映射区“偷”了一块内存。这种方式释放的内存会归还操作系统
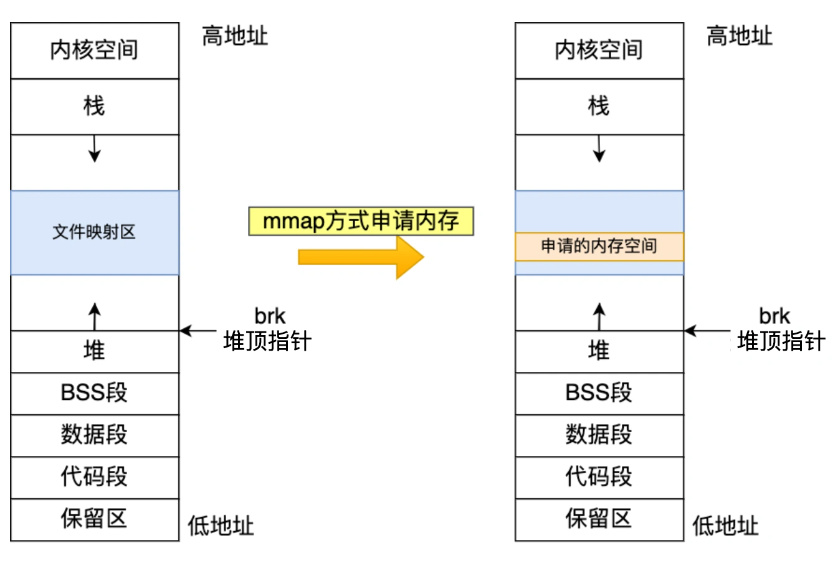
缺点:向操作系统申请内存,需要进入内核态再回到用户态,这样的切换会浪费不少时间,mmap每次释放内存时都会归还给操作系统,造成mmap分配的虚拟地址为缺页状态,若后面再次申请内存,会造成这一块缺页中断,这样会重新建立虚拟内存和物理内存间的映射关系,导致CPU消耗增大
malloc分配的内存并非物理内存,而是虚拟内存。若分配后的虚拟内存没有访问或使用,这样虚拟内存不会映射到物理内存,也就不会占用物理内存;只有在访问已分配的虚拟地址空间的时候,操作系统通过查找页表,发现虚拟内存对应的页没有在物理内存中,就会触发缺页中断,然后操作系统会建立虚拟内存和物理内存之间的映射关系
malloc() 在分配内存的时候,并不会按用户预期申请的字节数来分配内存空间大小,而是会预分配更大的空间作为内存池
//查看malloc(1)实际分配的内存空间
#include <stdio.h>
#include <malloc.h>
#include <unistd.h>
printf("使用cat /proc/%d/maps查看内存分配\n",getpid());
//申请1字节的内存
void *addr = malloc(1);
printf("此1字节的内存起始地址:%p\n", addr);
printf("使用cat /proc/%d/maps查看内存分配\n",getpid());
//将程序阻塞,当输入任意字符时才往下执行
getchar();
//释放内存
free(addr);
printf("释放了1字节的内存,但heap堆并不会释放\n");
getchar();


可以看到此处分配的堆开始地址和进程的堆空间开始地址并不相同,多了670字节,那么这多出的670字节是在描述什么吗?我们知道free函数的参数是指针,我们并没有告诉他分配的内存大小,那他是怎么知道的呢?很显然,这多出的670字节保存了该分配的内存块的描述信息,这样free就知道了该内存空间的大小
free
头文件: stdlib
原型: void free( void* ptr )
返回值:无
molloc申请到的指针 与 free要释放的指针保持一致
因为free释放的其实是指针所指向的内存,并不是指针本身,因此在释放内存后,必须将指针指向NULL,以免后续再对指针进行解引用而导致程序崩溃
针对 malloc 通过 brk() 方式申请的内存,free()将管理区域的标记改为”空块”。这么说来,free()函数在调用后,对应的内存是不会返还给操作系统的(还在空闲链表里呆着),它只是改变一些状态,但是进程结束后都会归还。也就是说,调用了free()之后,对应内存的内容不会马上被破坏,有时候如果再次申请同样大小的内存就可以直接复用,提高效率;针对 mmap() 方式申请的内存,free释放内存后则会归还给操作系统
int main(void)
{
char * p = NULL;
p=(char *)malloc(MAX_BUF_SIZE);
if (p == NULL)
{
/*...*/
}
/*内存初始化*/
memset(p, '\0', MAX_BUF_SIZE);
strcpy(p, "hello");
/*释放内存*/
if (p != NULL)
{
free(p); //p为野指针,依然指向之前所分配的内存的地址
}
if (p != NULL)
{
/*发生错误*/
strcpy(p, "world");
}
return 0;
}
#include<stdio.h>
int* p;
p = (int*)malloc(100 * 1024);
p++; //改变了 p 的首地址;
free(p); //程序崩溃
new
如果该类没有定义构造函数(由编译器合成默认构造函数)但有虚函数,那么class c = new class;和class c = new class();一样,都会调用默认构造函数
如果该类没有定义构造函数(由编译器合成默认构造函数)也没有虚函数,那么class c = new class;将不调用合成的默认构造函数,而class c = new class();则会调用默认构造函数
如果该类定义了默认构造函数,那么class c = new class;和class c = new class();一样,都会调用默认构造函数
对于重载版本
定义:重载三个版本
#ifndef __NOTHROW_T_DEFINED
#define __NOTHROW_T_DEFINED
namespace std
{
struct nothrow_t {
explicit nothrow_t() = default;
};
#ifdef _CRT_ENABLE_SELECTANY_NOTHROW
extern __declspec(selectany) nothrow_t const nothrow;
#else
extern nothrow_t const nothrow;
#endif
}
#endif
//抛出异常
void* __CRTDECL operator new(size_t const size)
{
for (;;)
{
if (void* const block = malloc(size))
{
return block;
}
if (_callnewh(size) == 0)
{
if (size == SIZE_MAX)
{
__scrt_throw_std_bad_array_new_length();
}
else
{
__scrt_throw_std_bad_alloc();
}
}
// The new handler was successful; try to allocate again...
}
}
//不抛出异常,而是返回一个空指针,和malloc相似
void* __CRTDECL operator new(size_t const size, std::nothrow_t const&) noexcept
{
try
{
return operator new(size);
}
catch (...)
{
return nullptr;
}
}
//placement new,返回_P
#ifndef __PLACEMENT_NEW_INLINE
#define __PLACEMENT_NEW_INLINE
inline void *__cdecl operator new(size_t, void *_P)
{return (_P); }
#if _MSC_VER >= 1200
inline void __cdecl operator delete(void *, void *)
{return; }
#endif
#endif
//例子
class A;
A* pa = new A();
//编译器对以上发生如下转化
A* pa;
try
{
void* tpa = operator new( sizeof(A) );
pa = static_cast<A*>(tpa);
pa->A::A();
}
catch( std::bad_alloc )
{
//...
}
执行过程:对于简单数据类型直接调用operator new分配内存;对于复杂数据类型则先调用operator new,再在分配的内存上调用构造函数
使用placement new时不要使用auto或者static,因为它们修饰的内存并非都正确地为每一个对象类型排列
对于内置类型的new,new在自由空间分配内存
因为自由空间分配的内存是无名的,因此new无法为分配对象命名,而是返回一个指向该对象的指针,只能申请单个元素的空间,无法对对象进行初始化
定义:
_NODISCARD _Ret_notnull_ _Post_writable_byte_size_(_Size) _VCRT_ALLOCATOR
void* __CRTDECL operator new(
size_t _Size
);
_NODISCARD _Ret_maybenull_ _Success_(return != NULL) _Post_writable_byte_size_(_Size) _VCRT_ALLOCATOR
void* __CRTDECL operator new(
size_t _Size,
::std::nothrow_t const&
) noexcept;
int* pt = new int; //指向无名对象
delete
对于重载版本
定义:
void __CRTDECL operator delete[](
void* _Block
) noexcept;
void __CRTDECL operator delete[](
void* _Block,
::std::nothrow_t const&
) noexcept;
void __CRTDECL operator delete[](
void* _Block,
size_t _Size
) noexcept;
执行过程:对于简单数据类型直接调用free释放内存;对于复杂数据类型先在要释放的内存上调用析构函数,再调用operator delete
对于内置类型,delete释放的是单个元素的空间
定义:
void __CRTDECL operator delete(
void* _Block
) noexcept;
void __CRTDECL operator delete(
void* _Block,
::std::nothrow_t const&
) noexcept;
void __CRTDECL operator delete(
void* _Block,
size_t _Size
) noexcept;
区别:
- new对malloc进行了封装,更加方便
- new申请分配内存时无需指定内存块大小;malloc需显示指出
- new在自由存储区内为对象动态分配内存空间;malloc在堆中动态分配内存
- new/delete为c++定义的运算符;malloc/free为c run time的标准库函数
- new/delete可以被重载;malloc/free不允许重载
- 不安全,malloc分配内存失败时返回NULL;安全,new分配内存失败时抛出bac_alloc异常
- new/delete需要调用构造/析构函数;malloc/free不会
- new/delete返回定义时的指针类型;malloc/free返回void类型指针,使用时还需要进行类型转换
using 和 namespcae
为了避免在大规模程序的设计中,以及在程序员使用各种各样的C++库时,这些标识符的命名发生冲突,标准C++引入关键字namespace,控制标识符的作用域
命名空间是一个声明性区域,为其内部的标识符(类型、函数和变量等的名称)提供一个范围
命名空间用于将代码组织到逻辑组中,还可用于避免名称冲突,尤其是在基本代码包括多个库时
命名空间范围内的所有标识符彼此可见,而没有任何限制
访问方式:命名空间之外的标识符可通过使用每个标识符的完全限定名(如 std::vector <std::string> vec;)来访问成员,也可通过单个标识符的 using 声明 (using std::string) 或命名空间中所有标识符的 using 指令 (using namespace std;) 来访问成员
//namespace声明
namespace ContosoData
{
class ObjectManager
{
public:
void DoSomething() {}
};
void Func(ObjectManager) {}
}
//访问namespace的三种方式
//使用完全限定名
ContosoData::ObjectManager mgr;
mgr.DoSomething();
ContosoData::Func(mgr);
//使用 using 声明,以将一个标识符引入范围
using ContosoData::ObjectManager;
ObjectManager mgr;
mgr.DoSomething();
//使用 using 指令,以将命名空间中的所有内容引入范围
using namespace ContosoData;
ObjectManager mgr;
mgr.DoSomething();
Func(mgr);
namespace只能在全局范围内定义
反例:
//不合法
void func()
{
namespace A
{
//...
};
namespace B
{
//...
};
}
namespace可以嵌套
namespace A
{
//...
namespace B;
//...
}
namespace是开放的,可以随时把新成员加入已有的namespace
namespace A
{
int a = 1;
}
//添加成员进A
namespace A
{
int b = 2;
}
namespace中的函数可以在namespace外定义
namespace A
{
void func();
}
void A::func()
{
//...
}
无名namespace,namespace中的标识符只能在本模块内访问,类似static
namespace
{
int a = 1;
}
void func()
{
a = 2;
}
可以为namespace定义别名
namespace A
{
//...
}
namespace AA = A;
- using有三种用法:
-
导入namespace,当然不止namespace.通过单个标识符的 using 声明 (
using std::string) 或命名空间中所有标识符的 using 指令 (using namespace std;) 来访问成员导入namespace
//namespace声明 namespace ContosoData { class ObjectManager { public: void DoSomething() {} }; void Func(ObjectManager) {} } //使用 using 声明,以将一个标识符引入范围 using ContosoData::ObjectManager; ObjectManager mgr; mgr.DoSomething(); //使用 using 指令,以将命名空间中的所有内容引入范围 using namespace ContosoData;类字段中的 using 声明
// using_declaration1.cpp #include <stdio.h> class B { public: void f(char) { printf_s("In B::f()\n"); } void g(char) { printf_s("In B::g()\n"); } }; class D : B { public: using B::f; // B::f(char) is now visible as D::f(char) using B::g; // B::g(char) is now visible as D::g(char) void f(int) { printf_s("In D::f()\n"); f('c'); // Invokes B::f(char) instead of recursing } void g(int) { printf_s("In D::g()\n"); g('c'); // Invokes B::g(char) instead of recursing } };通过使用 using 声明所声明的成员可以通过使用显式限定来引用
// using_declaration3.cpp #include <stdio.h> void f() { printf_s("In f\n"); } namespace A { void g() { printf_s("In A::g\n"); } } namespace X { using ::f; // global f is also visible as X::f using A::g; // A's g is now visible as X::g } void h() { printf_s("In h\n"); X::f(); // calls ::f X::g(); // calls A::g } -
using定义别名。虽然typedef也可以定义别名,但typedef主要是c++为了兼容c所支持的,也就是说,并不是适用于所有场景。比如typedef用在模板将会非常难用,这个时候就得使用using,而且using可读性更高
//模板中使用typedef template <typename Val> struct str_map { typedef std::map<std::string, Val> type; }; // ... str_map<int>::type map1; //繁琐 //模板中使用using template <typename Val> using str_map_t = std::map<std::string, Val>; // ... str_map_t<int> map1; //可读性 typedef void (*func_t)(int, int); using func_t = void (*)(int, int); -
用于声明成员时,using 声明必须引用基类的成员
// using_declaration2.cpp #include <stdio.h> class B { public: void f(char) { printf_s("In B::f()\n"); } void g(char) { printf_s("In B::g()\n"); } }; class C { public: int g(); }; class D2 : public B { public: using B::f; // ok: B is a base of D2 using C::g; // error: C isn't a base of D2 };
final
使用 final 关键字指定无法在派生类中重写的虚函数或指定无法继承的类
final 只有在函数声明或类名称后使用时才是区分上下文的且具有特殊含义;否则,它不是保留的关键字(语言已经定义过的,开发者不可再定义)
形式:
function-declaration final;
class class-name final base-classes
//虚函数
class BaseClass
{
virtual void func() final;
};
class DerivedClass: public BaseClass
{
virtual void func(); // compiler error: attempting to override a final function
};
//class
class BaseClass final
{
};
class DerivedClass: public BaseClass // compiler error: BaseClass is marked as non-inheritable
{
};
=default 和 =delete
- c++引入"=default",来显式的要求编译器合成默认的构造函数,大多数时候来说,编译器生成的默认构造函数比开发者定义的构造函数效率更高
引入这个的原因是,如果你定义一个class,而这个class内含另一个class成员,这个成员包含默认构造函数,而你定义的class的构造函数并未考虑到这种情况,编译器不会再合成一个nontrivial默认构造函数(c++ 面向对象 class类总结 - 爱莉希雅 - 博客园 (cnblogs.com)),因为它认为你想自己大展身手,对于这类情况我们就需要显示的要求编译器合成默认的构造函数
//反例
//假设B包含A
class A
{
public:
A(int);
//...
};
class B
{
public:
A a; //不会合成默认的构造函数
char* str;
//...
};
void func()
{
B b; //报错
if (str)
{
//...
}
}
//如下即可
class A
{
public:
A() = default;
A(int);
//...
};
=default只适用于class的特殊成员函数,如构造函数,拷贝构造,析构函数等
- "=delete"可以要求让编译器不为我们生成指定的成员函数。因为有些情况,编译器合成的成员函数可能会让你的代码走向不是你预期的方向
在以前,要明确拒绝编译器合成的特殊成员函数,比较麻烦,需要定义一个基类专门阻止拷贝(c++ 面向对象 class类总结 - 爱莉希雅 - 博客园 (cnblogs.com))
class A
{
public:
A() = delete;
A(int);
//...
};
noexcept
使用noexcept来指定某个函数是否可能会引发异常
参数:类型 bool 的常数表达式
形式:
noexcept-specifier:
noexcept
noexcept-expression
throw ( )
noexcept-expression:
noexcept ( constant-expression )
noexcept-expression 是一种异常规范:一个函数声明的后缀,代表了一组可能由异常处理程序匹配的类型,用于处理退出函数的任何异常
当 constant_expression 生成 true 时,一元条件运算符 noexcept(constant_expression) 及其无条件同义词 noexcept 指定可以退出函数的潜在异常类型集为空。 也就是说,该函数绝不会引发异常,也绝不允许在其范围外传播异常。 当 constant_expression 生成 false 或缺少异常规范(析构函数或解除分配函数除外),noexcept(constant_expression) 指出可以退出函数的潜在异常集是所有类型的集合
#include <type_traits>
template <typename T>
T copy_object(const T& obj) noexcept(std::is_pod<T>)
{
// ...
}
reference
(25条消息) C++中如何修改const变量_heyabo的博客-CSDN博客
谈谈C++的auto,decltype(auto)及在模板中的应用 - 知乎 (zhihu.com)
(25条消息) nullptr详解_KFPA的博客-CSDN博客_nullptr
浅谈malloc()与free() - 知乎 (zhihu.com)
C++:带你理解new和delete的实现原理 - 掘金 (juejin.cn)
C/C++中volatile关键字详解 - chao_yu - 博客园 (cnblogs.com)
C语言中文网:C语言程序设计门户网站(入门教程、编程软件) (biancheng.net)
C# 文档 - 入门、教程、参考。 | Microsoft Learn
知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具 (zsxq.com)
详解c++的命名空间namespace - 知乎 (zhihu.com)
c++primer 5th
effective c++ 3th
深度探索c++对象模型
c++语言的设计和演化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号