

对监督和无监督学习的谱方法特征选取
参考论文为"Spectral feature selection for supervised and unsupervised learning " 作者 为 Zheng Zhao ;Huan Liu
这篇文章的好处在于提出了一种基于"谱图理论"(spectral graph)的特征选取框架,像Laplacian score 和 ReliefF 都属于这个框架的一个特殊情况而已。而这个框架的假设,依然是本着原数据是大爷的道理,假设一个好的特征应该与原来(训练)数据构成的图有着相似的结构。当然一个特征毕竟是有限的(比如用性别来区分人有没有钱),可是这个特征与训练数据的相关性越大,我们就觉得这个特征越好,越可取。
先来看一下这个算法框架
- 构建数据的相似性矩阵S,以及由此基础推出的图的表示G,和W,D,L
- 计算
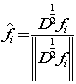 以及
以及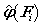
- 对
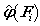 排序
排序
这个算法的架构非常的简单,连一个循环都都没有,重点是在建模上。
现在开始慢慢把这个框架扒皮。
算法推倒
先用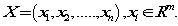 来表示一个训练集,我们用
来表示一个训练集,我们用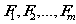 来表示m个特征,每个特征的对应的数据向量为
来表示m个特征,每个特征的对应的数据向量为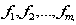 对于监督学习
对于监督学习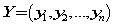 用来表示每个数据所对应的类。
用来表示每个数据所对应的类。
给定以上数据,可以由不同的规则来定义一个代表数据实例之前关系的实对称举着 ,
,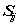 表示两个实例之间的关系(距离),下面是两种常用的规则
表示两个实例之间的关系(距离),下面是两种常用的规则
对于无监督学习,可以用RBF核函数:

对于监督学习:

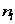 表示l类中实例的个数。所以我们可以通过
表示l类中实例的个数。所以我们可以通过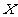 得到其无向图
得到其无向图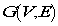 ,对于图G我们定义它的相邻矩阵(adjacency matrix)W,
,对于图G我们定义它的相邻矩阵(adjacency matrix)W,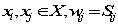 .定义向量
.定义向量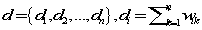
图G的degree matrix D为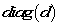 。Laplacian matrix
。Laplacian matrix
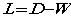
Normalized Laplacian matrix

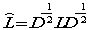
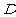 与
与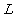 满足如下性质
满足如下性质
定理1:给定图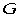 的
的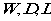 有
有
- 令
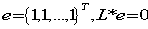
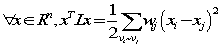
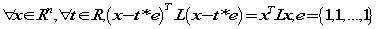
第一步衡量实例之间的相似性解决了,下一步就是求特征的权重(score)
由性质2可以知道laplacian matrix 可以衡量一个向量各个数值之间的加权平方和,可以用来度量一个组数据之间的离散程度。这正是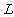 矩阵有用的地方。
矩阵有用的地方。
既然这样,因为有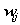 ,我们直接用
,我们直接用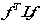 就可以算向量
就可以算向量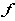 与原数据之间的离散程度,这个式子越小,与元数据差别就越小。但是还要归一化一下由式子(5),所以有
与原数据之间的离散程度,这个式子越小,与元数据差别就越小。但是还要归一化一下由式子(5),所以有
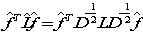
So
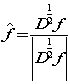
所以可以定义一个简单的

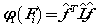
当然这个间断的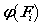 并不能满足我们日益增长的需求,Smola 和Kondor用傅里叶变换对
并不能满足我们日益增长的需求,Smola 和Kondor用傅里叶变换对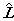 进行了扩展,
进行了扩展,
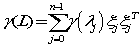
这里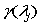 是一个单调增函数,是用来惩罚高频分量
是一个单调增函数,是用来惩罚高频分量
比如说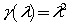 ,可以有如下形式种特征打分函数
,可以有如下形式种特征打分函数
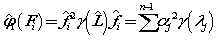
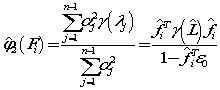
可以证明Laplacian score 方法只不过是spec 方法的特殊情况,且laplacian 的打分函数,是10式
总结
Spectral feature selection 是一个方法框架,在这个框架的下可以处理监督 与非监督学习的情况,并可以看书laplacian score方法只是这种方法的一种特殊情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号