大数据面试题V3.0 -- HBase面试题(约2.8w字)
HBase面试题(约2.8w字)
-
介绍下HBase
HBase是一个分布式的,面向列的开源数据库。它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。
另一个不同的是HBase基于列的而不是基于行的模式。HBase使用和 BigTable非常相同的数据模型。
用户存储数据行在一个表里。一个数据行拥有一个可选择的键和任意数量的列,一个或者多个列组成ColumFamily,一个Fammily下的列位于一个HFile中,易于缓存数据。
表是稀松存储的,因此用户可以给行定义各种不同的列。在HBase中数据按主键排序,同时表按主键划分为多个Region。 分布式环境中HBase运行在HDFS之上,以HDFS作为其基础存储设施。
HBase上层提供了访问数据的Java API层,供应用访问存储在HBase的数据。
在HBase的集群中主要由Master和Region Server组成,以及Zookeeper -
HBase优缺点
一、Hbase的优点 HDFS有高容错,高扩展的特点,而Hbase基于HDFS实现数据的存储,因此Hbase拥有与生俱来的超强的扩展性和吞吐量。 HBase采用的是Key/Value的存储方式,这意味着,即便面临海量数据的增长,也几乎不会导致查询性能下降。 HBase是一个列式数据库,相对于于传统的行式数据库而言。当你的单张表字段很多的时候,可以将相同的列(以regin为单位)存在到不同的服务实例上,分散负载压力。 二、Hbase的缺点 架构设计复杂,且使用HDFS作为分布式存储,因此只是存储少量数据,它也不会很快。在大数据量时,它慢的不会很明显! Hbase不支持表的关联操作,因此数据分析是HBase的弱项。常见的 group by或order by只能通过编写MapReduce来实现! Hbase部分支持了ACID 三、Hbase的总结 适合场景:单表超千万,上亿,且高并发! 不适合场景:主要需求是数据分析,比如做报表。数据量规模不大,对实时性要求高! https://blog.csdn.net/weixin_42796403/article/details/112790756
-
说下HBase原理
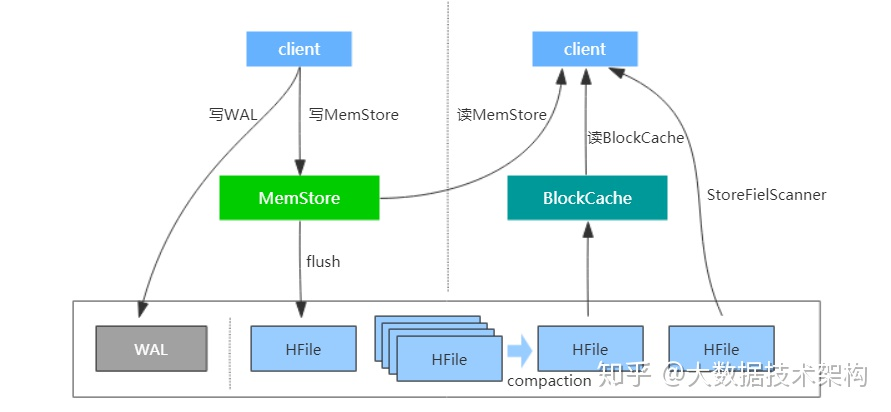
随着时间推移,写入的HFile会越来越多,查询数据时就会因为要进行多次io导致性能降低,
为了提升读性能,HBase会定期执行compaction操作以合并HFile。
此外,HBase在读路径上也有诸多设计,其中一个重要的点是设计了BlockCache读缓存。
这样以后,读取数据时会依次从BlockCache、MemStore以及HFile中seek数据,
再加上一些其他设计比如布隆过滤器、索引等,保证了HBase的高性能。 -
介绍下HBase架构
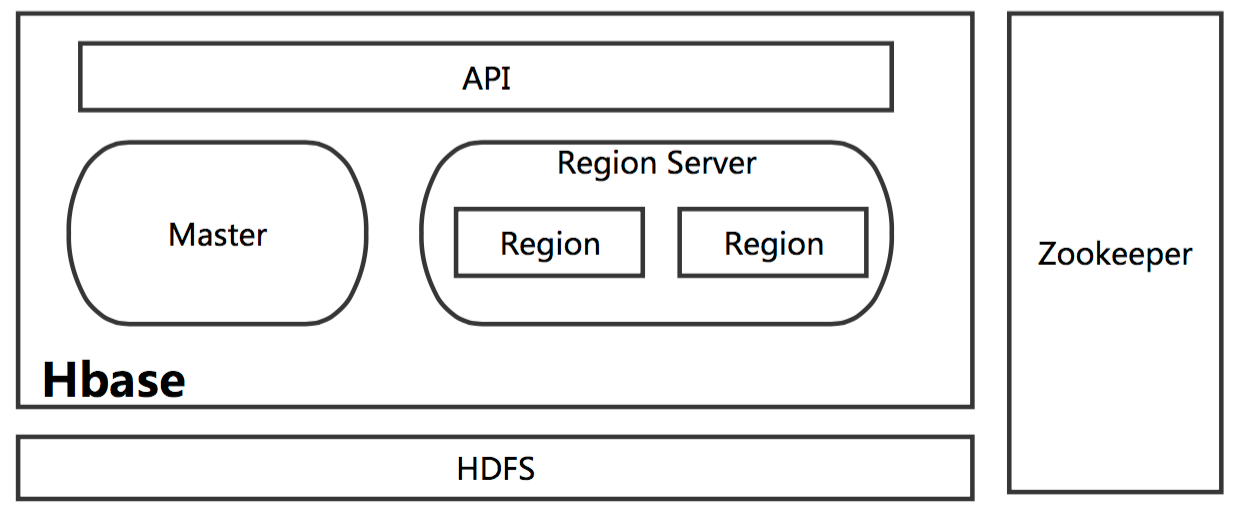
- Master
HBase Master用于协调多个Region Server,侦测各个Region Server之间的状态,并平衡Region Server之间的负载。 - HBase Master还有一个职责就是复杂分配Region给Region Server。HBase允许多个Master结点共存,但这需要zk的帮助。
- 不过当多个Master结点共存时,只有一个Master是提供服务的,其他的Master结点处于待命的状态。
- 当正在工作的Master结点宕机时,zk会选举另一个Master来接管HBase集群。更多参考:HMaster是什么?
- Region Server
一个Region Server包含多个Region。Region Server的作用只是管理表格,以及实现读写操作。 - Client直接连接Region Server,并通信获取HBase中的数据。对于Region而言,则是真实存放HBase数据的地方,也就是说Region是HBase可用性和分布式的基本单位。
- 如果当一个表格很大,并由多个CF组成时,那么表的数据将存放在多个Region之间,并且在每个Region中会关联多个存储单元(Store).
- Zookeeper
对于 HBase 而言,Zookeeper的作用是至关重要的。首先Zookeeper是作为HBase Master的HA解决方案。 - 也就是说,是Zookeeper保证了至少有一个HBase Master 处于运行状态。并且Zookeeper负责Region和Region Server的注册。
- 其实Zookeeper发展到目前为止,已经成为了分布式大数据框架中容错性的标准框架。不光是HBase,几乎所有的分布式大数据相关的开源框架,都依赖于Zookeeper实现HA。
- Master
-
HBase读写数据流程
Hbase的读取数据流程 1 客户端发起读取数据的请求, 首先会先连接zookeeper 2从zookeeper中获取一个 hbase:meta表 被那个RegionServer所管理着 hbase:meta: hbase的元数据表, 在这个表中存储了自定义的表相关元数据, 包含: 表名, 表有那些列族, 表有几个Region构成的, 每个Region被那个RegionServer管理meta表只有一个Region,
而这个Region必然会被某一个RegionServer所管理, 至于被那个RegionServer所管理了呢? zookeeper清楚 从zookeeper中的/hbase/meta-region-server获取hbase:meta表所在的节点: 3 连接meta表对应RegionServer, 从meta表获取当前要读取的这个表对应的Region是那些, 并且这些Region对应的RegionServer是谁当表有多个Region的时候:
如果执行的Get操作获取某一条数据, 只会返回一个RegionServer的地址;如果执行的Scan操作, 会将所有的Region对应RegionServer地址全部返回。 例如:查找TRANFER_RECORD表所在HRegionServer位置: 其中红框中的表示TRANFER_RECORD表所在HRegionServer位置为node3. 4连接要读取表对应的RegionServer, 从RegionServer上开始获取数据即可: 读取顺序: MemStore —> blockCache(缓存) —> StoreFlie(小HFile) —>大HFile 当从后续的文件中读取到数据后, 会将这一部分存储到缓存中 如果执行Scan操作, blockCache基本没有太大意义 整个读取过程, Master是否有参与呢? Master是不参与数据读取操作。 5.写入数据流程 1 由客户端发起写入数据的请求, 首先会先连接zookeeper 2 从zookeeper中获取 hbase:meta表 被那个regionServer所管理 3 连接meta表对应的RegionServer地址, 从meta表获取当前要写入的表对应region被那个RegionServer所管理(一般只会返回一个RegionServer地址, 除非一次性写入多条数据) 4连接对应要写入RegionServer的地址, 开始写入数据, 将数据首先会写入到HLog中,然后将数据写入到对应Region的对应Store模块的MemStore中(有可能会写入到MemStore), 当这两个地方都写入完成后, 客户端认为数据写入完成了 服务端写入过程: 异步操作(可能客户端执行N多次写入后, 服务端才开始对之前的数据进行操作) 5 随着客户端不断的写入操作, memstore中数据会越来越多, 当内存中数据达到阈值(128M / 1h)后, 就会触发flush刷新机制, 将数据<最终>刷新到HDFS上形成StoreFile(小Hfile)文件. 6 随着不断的刷新, 在HDFS上StoreFile文件会越来越多, 当StoreFlie文件数量达到阈值(3个及以上)后, 就会触发compact合并压缩机制, 将多个StoreFlie文件<最终>合并为一个大的HFile文件 7随着不断的合并, 大的HFile也会越来越大, 当大HFile达到一定的阈值(<最终>10GB)后, 就会触发Split分裂机制, 将大HFile进行一分为二,形成两个新的大HFile,
同时管理这个大HFile的Region也会形成两个新的Region, 形成的两个新的Region和两个新的大HFile 进行一对一的管理即可, 原来的Region和原来的大的HFile就会下线删除掉。 ———————————————— https://blog.csdn.net/lijian972/article/details/124227814 -
HBase的读写缓存
-
在删除HBase中的一个数据的时候,它什么时候真正的进行删除呢?当你进行删除操作,它是立马就把数据删除掉了吗?
-
HBase中的二级索引
-
HBase的RegionServer宕机以后怎么恢复的?
-
HBase的一个region由哪些东西组成?
-
HBase高可用怎么实现的?
-
为什么HBase适合写多读少业务?
-
列式数据库的适用场景和优势?列式存储的特点?
-
HBase的rowkey设计原则
-
HBase的rowkey为什么不能超过一定的长度?为什么要唯一?rowkey太长会影响Hfile的存储是吧?
-
HBase的RowKey设置讲究有什么原因
-
HBase的大合并、小合并是什么?
-
HBase和关系型数据库(传统数据库)的区别(优点)?
-
HBase数据结构
-
HBase为什么随机查询很快?
-
HBase的LSM结构
-
HBase的Get和Scan的区别和联系?
-
HBase数据的存储结构(底层存储结构)
-
HBase数据compact流程?
-
HBase的预分区
-
HBase的热点问题
-
HBase的memstore冲刷条件
-
HBase的MVCC
-
HBase的大合并与小合并,大合并是如何做的?为什么要大合并
-
既然HBase底层数据是存储在HDFS上,为什么不直接使用HDFS,而还要用HBase
-
HBase和Phoenix的区别
-
HBase支持SQL操作吗
-
HBase适合读多写少还是写多读少
-
HBase表设计
-
Region分配
-
HBase的Region切分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号