大模型-Qwen3 MLP层-97
激活函数
import torch
from torch import nn
import torch.nn.functional as F
class SiluAndMul(nn.Module):
def __init__(self):
super().__init__()
@torch.compile
def forward(self, x: torch.Tensor) -> torch.Tensor:
x, y = x.chunk(2, -1)
return F.silu(x) * y
这到底是个什么激活函数?
这是SwiGLU(SiLU-GLU)门控激活的最小实现
把线性投影的输出分成两半,一半做门控(通常过 sigmoid/gelu/silu),再与另一半逐元素相乘。
SiLU(又名 Swish;SiLU(z)=z*sigmoid(z))作为门。实践表明,它在大模型 FFN/MLP 中比 GELU 或标准 GLU 更稳、更好。
这段代码:把输入最后一维对半切成 x 和 y,然后返回 SiLU(x) ⊙ y(逐元素乘)
数学形式:
设输入张量为: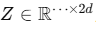 ,把最后一维切成两半
,把最后一维切成两半
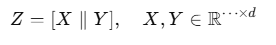
SiLU 定义为:
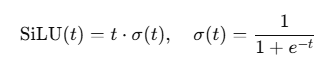
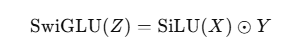
等价写法: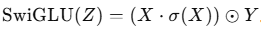
其他对比:
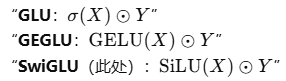
SiLU 的导数:
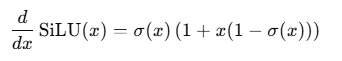
负区间也有非零梯度(不像 ReLU 那样“死区”),这有助于训练。
实现细节:
维度对半:如果最后一维不是偶数,chunk(2, -1)会报错(在 Qwen MLP 中这由线性层输出维度保证)
@torch.compile 首次运行有编译开销;长序列/大批量推理或训练时能摊薄成本并带来提速。
SiluAndMul 就是把线性层拼出来的 [A, B] 沿最后一维一分为二,然后做 SiLU(A) ⊙ B。
它实现了 Transformer 门控 FFN 中常用的 SwiGLU 激活,输出维度减半,既起到门控又做非线性,在大模型里是“好用又高性价比”的选择。
Qwen3MLP
class Qwen3MLP(nn.Module):
def __init__(
self,
hidden_size: int,
intermediate_size: int,
hidden_act: str,
) -> None:
super().__init__()
self.gate_up_proj = MergedColumnParallelLinear(
hidden_size,
[intermediate_size] * 2,
bias=False,
)
self.down_proj = RowParallelLinear(
intermediate_size,
hidden_size,
bias=False,
)
assert hidden_act == "silu"
self.act_fn = SiluAndMul()
def forward(self, x):
gate_up = self.gate_up_proj(x)
x = self.act_fn(gate_up)
x = self.down_proj(x)
return x
就是 Qwen3 模型里 Transformer Block 的 MLP 层(也叫 FFN 层)。
输入 x 形状一般是 [batch, seq_len, hidden_size]
hidden_size 就是 Transformer 模型的主维度,比如 4096
输出形状和输入相同,也是 [batch, seq_len, hidden_size],这样才能和残差连接对齐。
gate_up_proj:
self.gate_up_proj = MergedColumnParallelLinear(
hidden_size,
[intermediate_size] * 2,
bias=False,
)
这是一个 线性层,但输出维度是 2 * intermediate_size
它对应 Transformer FFN 中的两个投影:
W_gate: 产生门控向量
W_up: 产生被门控的候选值
MergedColumnParallelLinear 一次性做投影,把结果拼在一起,最后一维大小 = 2 * intermediate_size
举个例子:
hidden_size = 4096
intermediate_size = 11008
gate_up_proj 输出形状就是 [batch, seq_len, 22016]
act_fn — SwiGLU 激活:
接收 [batch, seq_len, 2 * intermediate_size]
.chunk(2, -1) 切成 [batch, seq_len, intermediate_size] 的两半
x → 过 SiLU
y → 原样保留
输出 = SiLU(x) * y
形状 [batch, seq_len, intermediate_size]
down_proj — 压回 hidden_size
self.down_proj = RowParallelLinear(
intermediate_size,
hidden_size,
bias=False,
)
把 intermediate_size 维度的向量再线性投影回 hidden_size,保证 MLP 输入和输出维度一致,方便 residual 加法。
数学公式:
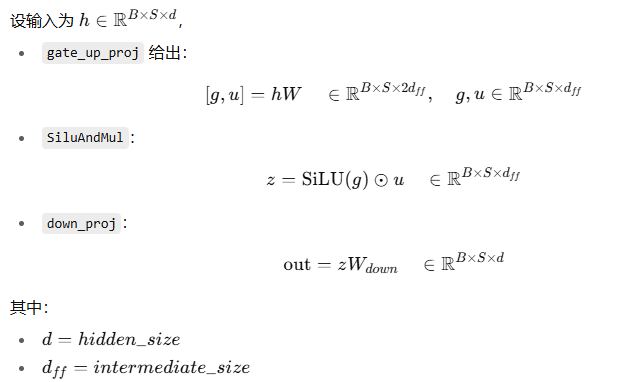

 浙公网安备 33010602011771号
浙公网安备 33010602011771号