MXFP4 gpt-oss 使用的新的数据结构
参考:https://www.cnblogs.com/cavalier-chen/p/18591085
MX数据结构
https://arxiv.org/abs/2310.10537
https://app.funblocks.net/#/aiflow?hid=73c6c8f2db07d2a2a1a25a6499f6b792
FP32、FP16 是如何表示一个浮点数据的?
将一个二进制数位串分割成三个部分:符号位 (Sign)、指数位 (Exponent) 和 尾数位 (Mantissa),也称为有效数位 (Significand) 或小数部分 (Fraction)。
FP32 (单精度浮点数)
FP32,即单精度浮点数,使用32个比特(4个字节)来存储一个数字。
32bit 4byte
符号位 (Sign, S): 1位 (第31位)
0 代表正数
1 代表负数
指数位 (Exponent, E): 8位 (第30位到第23位)
用于表示数字的量级(大小范围)。
尾数位 (Mantissa, M): 23位 (第22位到第0位)
用于表示数字的精度(有效数字)

S: 符号位的值 (0 或 1)。
M: 尾数位的值。这是一个二进制小数。例如,如果尾数位是 1010...,那么它的值就是1×2-1+0×2−2+1×2^−3+… 公式中的 (1 + M) 是因为在规格化表示中,尾数部分默认省略了一个前导的 1(这个隐藏位节省了一位存储空间,提高了精度)。
E: 指数位的无符号整数值。
假设有一个FP32数,其二进制表示为 0 10000001 10100000000000000000000。

代入公式计算:
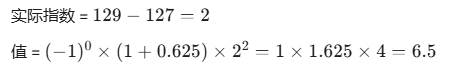
FP16 (半精度浮点数)
FP16,即半精度浮点数,使用16个比特(2个字节)来存储一个数字。它常用于GPU和AI加速器中,因为它可以显著减少内存占用和带宽需求,从而加快计算速度。
符号位 (Sign, S): 1位 (第15位)
指数位 (Exponent, E): 5位 (第14位到第10位)
尾数位 (Mantissa, M): 10位 (第9位到第0位)
其计算公式与FP32完全相同,但各部分的位数和偏置值不同:


总的来说,FP32和FP16都通过科学记数法的方式,将一个数字拆分为符号、指数和尾数三部分进行存储,从而在有限的比特位内表示出非常大或非常小的数。FP32提供更高的精度和更大的范围,而FP16则以牺牲部分精度和范围为代价,换取了更高的计算和存储效率。
MX数据格式
MX数据格式是一种为AI大模型设计的新的浮点数表示方法,旨在提高计算效率和节省硬件资源。
它通过“微缩放(microscaling)”技术,使用共享的指数位来表示一组数据,从而减少了每个单独数值所需的位数。
核心概念:微缩放 (Microscaling)
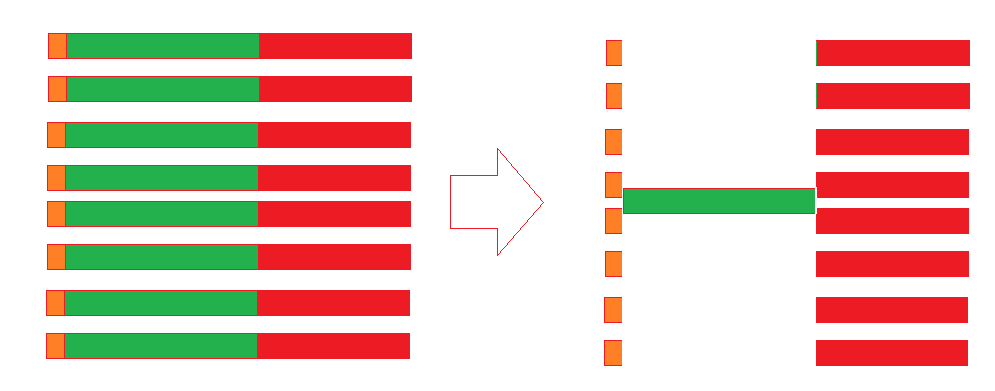
传统浮点数格式(如FP32、FP16)中,每个数字都包含自己的符号位、指数位和尾数位。而MX格式的关键创新在于,它让一组数字(例如一个向量或张量块)共享一个共同的指数。这样一来,每个数字只需要存储自己的符号位和尾数位,从而大大减少了所需的总比特数。
论文中重点介绍了两种MX格式:MXFP6 和 MXFP4。
MXFP6 (6位浮点数):
构成: 它使用1个符号位和5个尾数位来表示每个数。
共享指数: 一组MXFP6数字会共享一个8位的指数。
优势: 相比于8位浮点数(FP8),MXFP6在保持相似的准确性和模型收敛性的同时,可以节省25%的内存和带宽,并可能带来性能提升。
MXFP4 (4位浮点数):
构成: 它使用1个符号位和3个尾数位来表示每个数。
共享指数: 与MXFP6类似,一组MXFP4数字也共享一个8位的指数。
优势: MXFP4进一步压缩了数据,非常适合于对性能要求极高的推理场景。它能显著降低内存占用和带宽需求,从而加快计算速度。
MX数据格式的工作原理:
数据分组: 在计算过程中,一个向量或张量会被分成若干个小组(block)。
寻找最大指数: 在每个小组中,会计算出一个公共的指数。这个指数通常是根据该组数据中绝对值最大的那个数来确定的,以保证组内所有数都能被准确表示而不会溢出。
编码: 组内的每个数字都使用这个共享的指数进行编码,只保留各自的符号位和尾数位。
计算: 在进行矩阵乘法等运算时,硬件会利用这个共享的指数来恢复每个数字的近似值,然后进行计算。
MX数据格式的优势
硬件效率高: 由于共享指数的设计,MX格式可以简化计算单元的设计,节省芯片面积和功耗。
节省内存和带宽: 更少的数据位数意味着更小的模型体积和更低的数据传输开销,这对于越来越庞大的AI模型至关重要。
保持高精度: 尽管位数减少,但通过微缩放技术,MX格式能够在许多AI任务中(如大型语言模型和计算机视觉模型)达到与FP8甚至FP16相当的准确度。
灵活性: MX格式可以与现有的块浮点数(Block Floating Point)技术兼容,并可以灵活地调整分组大小(block size)以适应不同的硬件和模型需求。
总而言之,MX数据格式通过创新的共享指数机制,在AI大模型的计算中实现了效率和精度的平衡,为未来更强大、更高效的AI硬件提供了新的可能性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号