图像生成-Qwen image模型 MS_RoPE-28
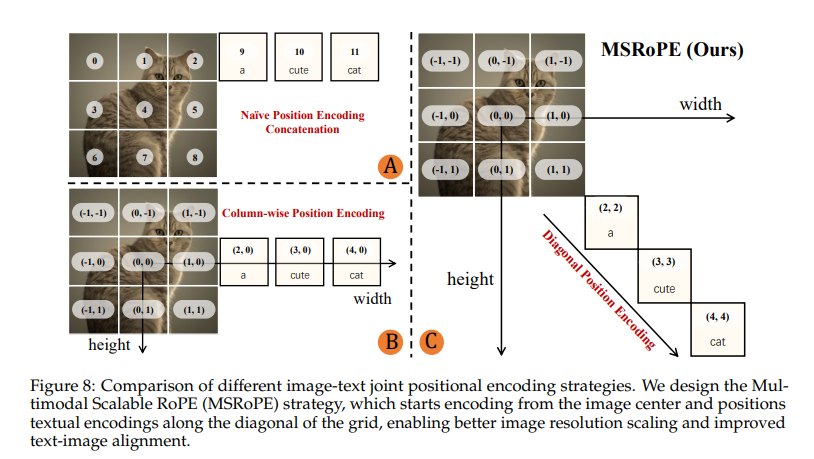

多模态可缩放 对角位置编码
Qwen-Image 骨干网络 (MMDiT) 中最核心的创新之一:多模态可缩放旋转位置编码 (Multimodal Scalable Rotary Position Embedding, MS-RoPE),并提供一个 PyTorch 的概念性代码示例来帮助你理解其实现原理。
如何融合图像的2D空间和文本的1D序列?
在多模态模型中,我们需要让模型同时理解:
图像块 (Image Patches) 的二维空间位置(例如,“左上角”、“中心”)
文本词元 (Text Tokens) 的一维序列顺序(例如,“猫抓老鼠”和“老鼠抓猫”的先后顺序很重要)。
传统方法存在一些问题:
A. 朴素拼接 (Naive Concatenation):简单地将文本拼在图像后面,文本失去了与图像空间位置的关联。
B. 按列/行编码 (Column-wise/Row-wise Encoding):将所有文本词元对齐到图像网格的某一行(例如中间的第0行)。如 image_7904e0.png 的文本所述,这会导致一个严重问题:所有文本词元在其中一个维度上具有相同的坐标(例如,y坐标都为0),这使得模型很难区分它们的相对位置,造成了位置信息的“同构性 (isomorphic)”,不利于学习精确的图文对齐。
Qwen-Image的解决方案:MS-RoPE 对角线编码 (Diagonal Position Encoding)
MS-RoPE
将文本词元“概念化”为放置在图像网格对角线上的元素。
图像的每个块 (patch) 正常获得其在二维网格中的 (y, x) 坐标。例如,一个 3x3 的图像网格,其坐标就是 (0,0), (0,1), ..., (2,2)。
对于文本序列,第 k 个文本词元被赋予一个二维坐标 (k', k'),其中 k' 是一个递增的索引。如 image_7904fe.png (C) 部分所示,a、cute、cat 被赋予了 (2,2), (3,3), (4,4) 这样的对角线坐标。
消除歧义:每个文本词元都在两个维度上拥有独一无二的坐标,彻底解决了行编码带来的歧义性问题。
保持序列性:在对角线上,k' 的递增自然地保留了文本的 1D 顺序关系。
无缝融合:图像和文本的位置编码现在都是二维的,可以被一个统一的旋转位置编码 (RoPE) 模块处理,实现了优雅的多模态融合。
易于扩展:这种方式天然支持图像分辨率的缩放,因为位置编码是基于相对坐标的。
PyTorch 代码示例
下面的代码并非 Qwen-Image 的源码,而是一个概念性的、简化的 PyTorch 实现,旨在清晰地展示 MS-RoPE 如何为图像和文本生成对角线位置ID。
这里的重点是如何生成位置ID (position IDs)
import torch
def get_msrope_pos_ids(image_size=(32, 32), patch_size=2, num_text_tokens=10):
"""
生成 MS-RoPE 的位置ID。
Args:
image_size (tuple): 输入图像的 (height, width)。
patch_size (int): VAE patch 的大小,用于计算网格尺寸。
num_text_tokens (int): 文本序列的长度。
Returns:
torch.Tensor: 形状为 (1, num_total_tokens, 2) 的位置ID张量,
其中 num_total_tokens = num_image_patches + num_text_tokens。
最后一个维度是 (y, x) 坐标。
"""
# 1. 计算图像块网格的尺寸
grid_h = image_size[0] // patch_size
grid_w = image_size[1] // patch_size
num_image_patches = grid_h * grid_w
# 2. 生成图像块的二维位置ID
# 创建一个y坐标网格和一个x坐标网格
y_coords = torch.arange(grid_h, dtype=torch.float32)
x_coords = torch.arange(grid_w, dtype=torch.float32)
# 使用广播机制创建完整的坐标网格
grid_y, grid_x = torch.meshgrid(y_coords, x_coords, indexing='ij')
# 将网格展平为 (num_image_patches, 2) 的形状
image_pos_ids = torch.stack([grid_y.flatten(), grid_x.flatten()], dim=1)
print(f"图像网格尺寸: {grid_h}x{grid_w}")
print(f"生成的图像位置ID (前5个): \n{image_pos_ids[:5]}")
print("-" * 20)
# 3. 生成文本词元的对角线位置ID (MS-RoPE的核心)
# 文本的位置ID从图像网格之外开始,沿着对角线排列
# 这里的起始索引可以根据具体实现调整,为清晰起见,我们从 grid_h 开始
# 这对应了图例中 (2,2), (3,3), (4,4) 的概念
start_idx = grid_h
text_indices = torch.arange(num_text_tokens, dtype=torch.float32) + start_idx
# 创建对角线坐标 (k', k')
text_pos_ids = torch.stack([text_indices, text_indices], dim=1)
print(f"文本词元数量: {num_text_tokens}")
print(f"生成的文本对角线位置ID (前5个): \n{text_pos_ids[:5]}")
print("-" * 20)
# 4. 拼接图像和文本的位置ID
# [num_image_patches, 2] + [num_text_tokens, 2] -> [total_tokens, 2]
total_pos_ids = torch.cat([image_pos_ids, text_pos_ids], dim=0)
# 增加一个 batch 维度,以符合模型输入格式 (B, N, C)
total_pos_ids = total_pos_ids.unsqueeze(0)
return total_pos_ids
# --- 示例使用 ---
# 假设我们有一个256x256的图像,VAE的patch_size=8, 文本有77个token
# 那么图像会被分为 32x32 的网格
pos_ids = get_msrope_pos_ids(image_size=(256, 256), patch_size=8, num_text_tokens=77)
num_total_tokens = (256 // 8) * (256 // 8) + 77
print(f"最终拼接后的位置ID张量形状: {pos_ids.shape}")
print(f"总token数应为: {(256//8)**2 + 77} = {num_total_tokens}")
print("此pos_ids张量将作为后续旋转位置编码(RoPE)模块的输入,用于计算每个token在注意力机制中的位置信息。")
# 在一个完整的模型中,这个 pos_ids 会被传入 RoPE 模块
# (这是一个伪代码,展示其在模型中的位置)
class AttentionWithMS_RoPE(torch.nn.Module):
def __init__(self):
super().__init__()
# self.q_proj, self.k_proj, self.v_proj = ...
# self.rotary_emb = RotaryEmbedding(...) # RoPE的实现
pass
def forward(self, hidden_states, pos_ids):
# ... project hidden_states to q, k, v
# q, k, v = self.q_proj(hidden_states), ...
# 在这里应用旋转编码
# self.rotary_emb 会使用 pos_ids 来计算旋转矩阵并应用到q和k上
# q_rotated, k_rotated = self.rotary_emb(q, k, pos_ids)
# ... compute attention with rotated q and k
# attn_output = torch.nn.functional.scaled_dot_product_attention(q_rotated, k_rotated, v)
# return attn_output
pass
RotaryEmbedding2D:一个实现了 2D 旋转位置编码的模块。这是 MS-RoPE 的核心部分,它接收 2D 坐标并对 query 和 key 向量进行旋转
import torch
import torch.nn as nn
import math
# -------------------------------------------------------------------------------
# 辅助函数:用于生成MS-RoPE的位置ID (来自上一个回答)
# -------------------------------------------------------------------------------
def get_msrope_pos_ids(image_grid_size=(32, 32), num_text_tokens=77):
"""
生成 MS-RoPE 的位置ID。
Args:
image_grid_size (tuple): 图像块网格的 (height, width)。
num_text_tokens (int): 文本序列的长度。
Returns:
torch.Tensor: 形状为 (1, num_total_tokens, 2) 的位置ID张量。
"""
grid_h, grid_w = image_grid_size
# 1. 生成图像块的二维位置ID
y_coords = torch.arange(grid_h, dtype=torch.float32)
x_coords = torch.arange(grid_w, dtype=torch.float32)
grid_y, grid_x = torch.meshgrid(y_coords, x_coords, indexing='ij')
image_pos_ids = torch.stack([grid_y.flatten(), grid_x.flatten()], dim=1)
# 2. 生成文本词元的对角线位置ID
start_idx = grid_h
text_indices = torch.arange(num_text_tokens, dtype=torch.float32) + start_idx
text_pos_ids = torch.stack([text_indices, text_indices], dim=1)
# 3. 拼接
total_pos_ids = torch.cat([image_pos_ids, text_pos_ids], dim=0)
return total_pos_ids.unsqueeze(0) # 增加 batch 维度
# -------------------------------------------------------------------------------
# 核心组件 1: 2D 旋转位置编码
# -------------------------------------------------------------------------------
class RotaryEmbedding2D(nn.Module):
"""
实现了2D旋转位置编码 (RoPE) 的模块
它将特征维度分成两半,一半用y坐标旋转,另一半用x坐标旋转。
"""
def __init__(self, dim):
super().__init__()
# 确保特征维度是偶数
assert dim % 2 == 0
self.dim = dim
# RoPE的核心参数 a_i = 10000^(-2i/d)
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer("inv_freq", inv_freq)
def forward(self, q, k, pos_ids):
"""
Args:
q (torch.Tensor): Query, 形状 (B, H, N, D)
k (torch.Tensor): Key, 形状 (B, H, N, D)
pos_ids (torch.Tensor): MS-RoPE 位置ID, 形状 (B, N, 2) -> (y, x)
Returns:
torch.Tensor, torch.Tensor: 旋转后的 q 和 k
"""
# pos_ids: (B, N, 2) -> y: (B, N), x: (B, N)
pos_y = pos_ids[..., 0]
pos_x = pos_ids[..., 1]
# 计算频率张量 freqs = m * a_i
# freqs_y/x: (B, N, D/2)
freqs_y = torch.einsum("bi,j->bij", pos_y, self.inv_freq)
freqs_x = torch.einsum("bi,j->bij", pos_x, self.inv_freq)
# 将频率张量扩展以匹配 q 和 k 的形状
# (B, N, D/2) -> (B, 1, N, D/2)
freqs_y = freqs_y.unsqueeze(1)
freqs_x = freqs_x.unsqueeze(1)
# 计算 sin 和 cos
cos_y = freqs_y.cos()
sin_y = freqs_y.sin()
cos_x = freqs_x.cos()
sin_x = freqs_x.sin()
# 将 q 和 k 的特征维度分成两半
# (B, H, N, D) -> (B, H, N, D/2)
q_y, q_x = q.chunk(2, dim=-1)
k_y, k_x = k.chunk(2, dim=-1)
# 定义旋转函数
def rotate(x, cos, sin):
# 将 x=(a,b) 旋转为 (a*cos - b*sin, a*sin + b*cos)
x_a, x_b = x.chunk(2, dim=-1) # D/2 -> 2 * D/4
return torch.cat([x_a * cos - x_b * sin, x_a * sin + x_b * cos], dim=-1)
# 对 y 和 x 部分分别应用旋转
q_rotated = torch.cat([rotate(q_y, cos_y, sin_y), rotate(q_x, cos_x, sin_x)], dim=-1)
k_rotated = torch.cat([rotate(k_y, cos_y, sin_y), rotate(k_x, cos_x, sin_x)], dim=-1)
return q_rotated, k_rotated
# -------------------------------------------------------------------------------
# 核心组件 2: 带有 MS-RoPE 的注意力模块
# -------------------------------------------------------------------------------
class AttentionWithMS_RoPE(nn.Module):
def __init__(self, embed_dim, num_heads):
super().__init__()
assert embed_dim % num_heads == 0
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.o_proj = nn.Linear(embed_dim, embed_dim)
# 实例化2D旋转编码模块
self.rotary_emb = RotaryEmbedding2D(self.head_dim)
def forward(self, hidden_states, pos_ids):
"""
Args:
hidden_states (torch.Tensor): 输入张量, 形状 (B, N, C)
pos_ids (torch.Tensor): MS-RoPE 位置ID, 形状 (B, N, 2)
"""
batch_size, seq_len, _ = hidden_states.shape
# 1. 线性投射
q = self.q_proj(hidden_states)
k = self.k_proj(hidden_states)
v = self.v_proj(hidden_states)
# 2. 重塑以适应多头注意力
# (B, N, C) -> (B, N, H, D) -> (B, H, N, D)
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 3. 应用 MS-RoPE (核心步骤)
q, k = self.rotary_emb(q, k, pos_ids)
# 4. 计算缩放点积注意力
# 使用 PyTorch 2.0 内置函数,简洁高效
attn_output = F.scaled_dot_product_attention(q, k, v)
# 5. 重塑回原始形状
# (B, H, N, D) -> (B, N, H, D) -> (B, N, C)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.view(batch_size, seq_len, -1)
# 6. 输出投射
return self.o_proj(attn_output)
# -------------------------------------------------------------------------------
# 演示如何使用
# -------------------------------------------------------------------------------
if __name__ == "__main__":
import torch.nn.functional as F
# --- 模型参数 ---
BATCH_SIZE = 2
IMAGE_GRID_SIZE = (16, 16) # 假设图像被编码成16x16的网格
NUM_TEXT_TOKENS = 20
EMBED_DIM = 128
NUM_HEADS = 8
# --- 准备输入数据 ---
num_image_patches = IMAGE_GRID_SIZE[0] * IMAGE_GRID_SIZE[1]
total_tokens = num_image_patches + NUM_TEXT_TOKENS
# 随机的输入特征
dummy_hidden_states = torch.randn(BATCH_SIZE, total_tokens, EMBED_DIM)
# 生成 MS-RoPE 位置 ID
pos_ids = get_msrope_pos_ids(image_grid_size=IMAGE_GRID_SIZE, num_text_tokens=NUM_TEXT_TOKENS)
# 扩展到与 batch size 一致
pos_ids = pos_ids.repeat(BATCH_SIZE, 1, 1)
print(f"输入 hidden_states 形状: {dummy_hidden_states.shape}")
print(f"输入 pos_ids 形状: {pos_ids.shape}")
print("-" * 30)
# --- 实例化并运行模型 ---
attention_block = AttentionWithMS_RoPE(embed_dim=EMBED_DIM, num_heads=NUM_HEADS)
# 前向传播
output = attention_block(dummy_hidden_states, pos_ids)
print("模型成功运行!")
print(f"输出 output 形状: {output.shape}")
# --- 验证输出形状 ---
assert output.shape == dummy_hidden_states.shape
print("输出形状与输入形状一致,验证通过。")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号