图像生成-FUDUKI解读-一张图片引发的思考-22

图片生成领域,你能从这张图片中受到什么启发吗?
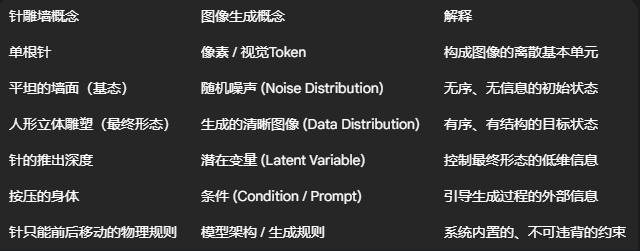
深圳“世界之窗”拍摄的针雕艺术墙照片,对于学习图像生成的人来说,是一个非常深刻和具象化的物理比喻。
它几乎完美地映射了现代生成模型,特别是扩散模型(Diffusion Models)和流模型(Flow Matching)中的几个核心思想。
从这张图中汲取灵感,将其“翻译”成图像生成的语言
离散单元构成连续的整体 (像素/Token -> 图像)
针雕墙的启示:这面墙由成千上万个独立的、离散的“针”(或圆柱)组成。单独看,每一根针只是一个点。但当它们以不同的深度组合在一起时,我们的眼睛就能感知到一个连续、平滑的人形轮廓。
像素网格:这最直接地对应了数字图像的本质——一个由离散像素组成的网格。模型的任务就是为这个网格上的每个像素点赋予合适的颜色值,从而构成有意义的图像。
视觉Token:在更现代的模型(如Vision Transformer, VQ-GAN)中,模型甚至会将图像分解成一个个离散的“视觉词元”(Visual Tokens)。模型的任务就是学习如何像组织语言一样,有逻辑地“排列”这些视觉词元,形成最终的图像。
核心启发:复杂、连续的宏观结构,可以由简单、离散的微观单元通过特定规则组合而成。
从无序的基态到有序的形态 (噪声 -> 图像)
针雕墙的启示:这面墙有一个“基态”或“初始状态”——就是所有针都未被推动,形成一个完全平坦的表面。这个状态是均匀的、无信息的、高熵的。只有当有外力(人的身体)作用时,它才会呈现出复杂的、有信息的、低熵的形态。
这完美地诠释了扩散模型(DDPM)和流模型(Flow Matching)的核心哲学!
初始状态(平坦的墙) <-> 高斯噪声(Gaussian Noise):生成过程的起点是一个完全随机、没有任何结构的高斯噪声图像。
“推动”的过程 <-> 去噪/流动的过程:模型学习一个“力”,这个力引导着每一个像素点(或说噪声中的每一个维度)从随机状态逐渐移动到它应在的最终位置。这个过程就是一步步的去噪(Denoising)或沿着一个学习到的向量场流动(Flowing)。
最终形态(人形雕塑) <-> 生成的清晰图像:当这个过程结束,无序的噪声就被“雕刻”成了有序、有意义的图像。
核心启发:生成过程可以被看作是一个“秩序化”的过程,即从一个简单、高熵的基态分布(噪声)向一个复杂、低熵的目标分布(真实图像)的转化。
用低维信息控制高维表现 (潜在变量 -> 图像特征)
针雕墙的启示:观察每一根针的运动,它其实非常简单。它的 (x, y) 坐标是固定的,唯一变化的自由度就是它的深度 z(被推出了多远)。然而,正是这个一维的深度信息,在整个二维的平面上组合起来,创造了一个三维的立体形态。
这是对“潜在空间”(Latent Space)最直观的解释!
针的深度 z <-> 潜在变量(Latent Variable):在GAN或VAE等模型中,一张高维的图像可以被一个低维的潜在向量 z 所代表。这个向量捕捉了图像最本质的特征。
针的 (x,y) 位置 <-> 图像的空间位置/特征维度:在图像的特定位置或特定特征维度上施加潜在变量的影响。
整个针雕墙所有针的深度集合,就构成了一个“潜在空间”。这个空间中的每一个点,都唯一对应一个最终的雕塑形态。模型学习的就是如何将输入的提示(比如文字)映射到这个潜在空间中的一个点,从而“解码”出最终的图像。
核心启发:复杂的高维数据(如图像)可以由一个更简单、更低维的潜在表示来控制和生成。
生成是对外部条件的响应 (条件生成)
针雕墙的启示:针雕墙自己不会凭空产生图案。它产生的图案完全是对外部物体(人的身体)形状的一种“响应”或“复刻”。没有这个外部的“条件”,它就只能处于平坦的基态。
这正是条件生成(Conditional Generation)的精髓。现在几乎所有的实用模型都是条件生成模型。
按压的身体 <-> 文本提示(Text Prompt)、草图、分割图等条件。
模型在生成图像时,不是自由创造,而是严格地依据给定的条件来“雕刻”噪声。你输入“一只猫”,模型就“按压”出猫的形状;你输入“一座山”,模型就“按压”出山的形状。
核心启发:生成过程可以被精确地引导和控制,其输出是输入条件的函数。
这张照片提醒我们,很多看似高深的AI理论,其底层的哲学思想往往能在现实世界中找到简单、朴素、而又深刻的对应物。对于学习者来说,建立这样的直观联系,远比死记硬背公式要有效得多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号