大模型- 强化学习-TRL中的PPO代码--93
参考
https://newfacade.github.io/notes-on-reinforcement-learning/17-ppo-trl.html
https://gemini.google.com/app/247cc5d3d5bad7de
如何使用 PPO 算法结合 trl 库来微调大型语言模型(LLM)
这是一个巨大的跨越。之前我们学习的都是在像 CartPole 这样的“玩具”环境中应用强化学习,状态和动作都相对简单。
现在,我们将看到完全相同的 PPO 算法,是如何被用来训练像 GPT、Llama 这样的高级人工智能模型的。
当语言模型遇到强化学习
要理解这部分内容,我们必须首先重新定义强化学习中的基本概念,将它们映射到自然语言生成(NLG)任务上。
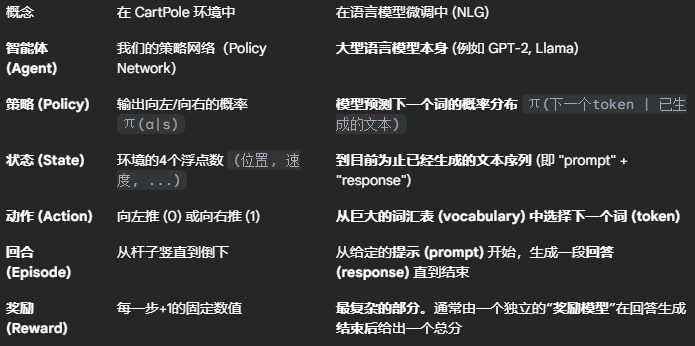
核心挑战:
在语言任务中,没有一个像游戏引擎那样的“环境”能自动在每一步都给出奖励。因此,我们通常需要训练另一个模型,称为奖励模型 (Reward Model),来评估最终生成的文本质量。例如,我们可以训练一个奖励模型来判断一段文本的“帮助性”、“无害性”或“幽默感”,并给出一个分数。这个分数就是 PPO 算法需要的奖励信号。
trl 库:连接 Transformer 与强化学习的桥梁
trl (Transformer Reinforcement Learning) 是 Hugging Face 推出的一个强大工具库,它极大地简化了将 PPO 这类 RL 算法应用于 Transformer 模型(如 GPT-2, Llama)的过程。
如果没有 trl,我们需要手动处理非常复杂的操作,比如:
将模型的生成过程包装成符合 RL 框架的模式。
管理和计算包含数万个词汇的巨大动作空间的对数概率。
实现 PPO 的所有复杂逻辑。
trl 将这一切都封装好了,让我们可以用几行代码就搭建起一个 PPO 的训练流程。
PPO 在 trl 中的工作流程与核心公式
使用 trl 进行 PPO 微调的流程,与我们之前学的 PPO 算法在精神上完全一致,但包含了语言模型特有的元素。
第一步:初始化(三位一体的模型设置)
策略模型 (Policy Model / Actor):这是我们要进行微调的 LLM。它在训练中会不断更新。
参考模型 (Reference Model):这是一个冻结的、不参与训练的原始预训练 LLM 的副本。它的作用至关重要,是用来计算 KL 散度惩罚的基准。
奖励模型 (Reward Model / Critic 的一部分):一个独立的模型(例如一个文本分类器),用于给生成的文本打分。
第二步:PPO 训练循环
在一个训练批次中,trl 的 PPOTrainer 会执行以下操作:
1.生成 (Rollout)
从数据集中取一批提示 (prompts)。
让策略模型 (Actor) 根据每个 prompt 生成一段回答 (responses)。这个 (prompt, response) 对就是我们的“轨迹”。
2.评估 (Evaluation)
对于每个生成的 (prompt, response),我们计算一个总的奖励分数。
这个分数由两部分组成:
来自奖励模型的外部奖励 r: 例如,一个情感分析模型判断生成的文本情感非常积极,给出一个高分。
KL 散度惩罚 r_kl: 这是 PPO 应用于 LLM 的关键。它用来惩罚策略模型偏离原始参考模型太远的行为。
总奖励公式:
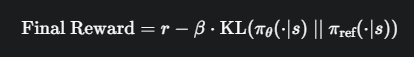
KL 惩罚项解读:KL(...) 衡量了当前策略 π_θ 的输出概率分布与原始参考策略 π_ref 的分布之间的差异。β 是一个超参数,控制 KL 惩罚的强度
为什么需要它? 如果没有 KL 惩罚,PPO 为了最大化奖励分数,可能会让模型生成一些无意义但能在奖励模型上“骗分”的文本,完全丧失了语言模型的通用能力。KL 惩罚就像一根缰绳,拉住模型,让它在追求高奖励的同时,不要忘记自己原本的语言知识,保持生成文本的流畅和合理性。这与 TRPO/PPO 中的“可信区域”思想一脉相承。
3.更新 (Optimization)
trl 的 PPOTrainer 在内部会使用这些计算出的总奖励,结合收集到的 (states, actions, logprobs) 等数据,执行我们熟悉的 PPO-Clip 算法进行更新。
自动计算 GAE 优势,并使用我们上一讲讨论的裁剪代理目标函数来同时更新 Actor 和 Critic(trl内部会有一个价值头来扮演 Critic 的角色)。
4. 代码实现解读
初始化 PPOTrainer
from trl import PPOConfig, PPOTrainer
# 1. 配置 PPO 参数
config = PPOConfig(
model_name="gpt2",
learning_rate=1.41e-5,
batch_size=256,
kl_penalty="kl", # 指定使用 KL 散度惩罚
adap_kl_ctrl=True # 动态调整 KL 惩罚系数 β
)
# 2. 加载模型和分词器
# model 是我们要训练的 Actor
# model_ref 是冻结的参考模型
# tokenizer 用于文本处理
model = ...
model_ref = ...
tokenizer = ...
# 3. 初始化 PPOTrainer
# 它封装了所有 PPO 的复杂逻辑
ppo_trainer = PPOTrainer(
config=config,
model=model,
ref_model=model_ref,
tokenizer=tokenizer,
dataset=dataset
)
主训练循环
for epoch in range(config.epochs):
for batch in ppo_trainer.dataloader:
# 1. 获取一批 prompt
query_tensors = batch["input_ids"]
# 2. 生成 (Rollout)
# 让策略模型(Actor)生成回答
# 这一步会自动记录 logprobs 等信息
response_tensors = ppo_trainer.generate(query_tensors, **generation_kwargs)
batch["response"] = tokenizer.batch_decode(response_tensors)
# 3. 评估 (Evaluation)
# 使用奖励模型计算外部奖励
# texts_for_reward = [q + r for q, r in zip(batch["query"], batch["response"])]
# rewards = reward_model(texts_for_reward)
rewards = torch.tensor([get_reward(text) for text in texts_for_reward])
# 4. 更新 (Optimization) - PPO 核心步骤
# 这是最关键的一步,所有复杂的计算都被封装在 .step() 中
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
# 打印统计信息
ppo_trainer.log_stats(stats, batch, rewards)
ppo_trainer.generate(...)数据收集步骤。它使用当前的 Actor model 来生成文本。
ppo_trainer.step(...)这是学习和更新步骤。你只需要把 (prompts, responses, rewards) 喂给它,它就会在内部自动完成:
计算KL 惩罚 r_kl。
计算最终奖励 Final Reward = r + r_kl。
使用收集到的数据和最终奖励,在内部运行 GAE 来计算优势。
使用裁剪代理目标函数 (Clipped Surrogate Objective) 构建 PPO 损失。
在一个循环中进行多轮 (K-epochs) 小批量梯度下降,更新 Actor 和 Critic 的权重。
总结
范式迁移:PPO 从一个用于简单控制任务的算法,被成功迁移到了微调大型语言模型这个极其复杂的任务上。
核心适配:通过引入奖励模型和KL散度惩罚,解决了在语言任务中没有明确奖励和需要保持语言一致性的核心问题。KL 惩罚可以被看作是 PPO 裁剪思想在 LLM 微调中的一种软约束形式。
trl 的威力:trl 库将 PPO 应用于 LLM 的巨大工程复杂性抽象成了简单的几行代码,使得研究者和开发者可以更专注于模型和奖励函数的设计,而不是陷入 RL 算法的实现细节中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号