大模型- 强化学习-Actor-Critic (演员-评论家) --85
参考
https://newfacade.github.io/notes-on-reinforcement-learning/12-actor-critic.html
https://gemini.google.com/app/247cc5d3d5bad7de
内容
Actor-Critic (演员-评论家) 方法,
这是一个非常强大和流行的强化学习框架。从名字就能看出,它结合了我们之前学过的两类方法:
策略梯度(Policy Gradient)
价值函数(Value Function)
可以把它看作是 REINFORCE 算法的一个重要升级。
为什么需要 Actor-Critic?—— REINFORCE 的痛点
在上一讲中,我们学习了 REINFORCE 算法。它直接学习策略,非常优雅,但有一个致命的缺陷:高方差 (High Variance)。
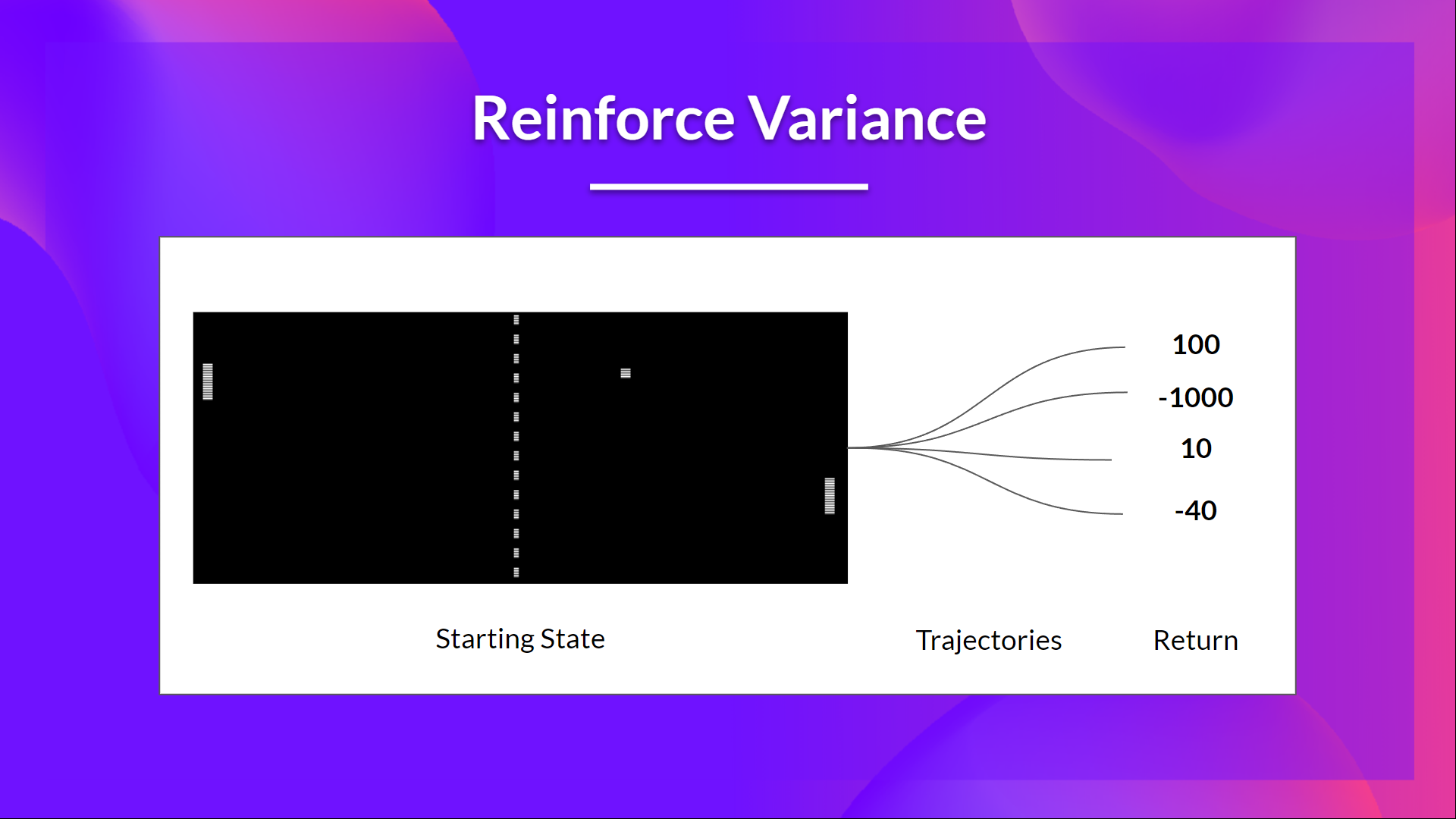
回顾 REINFORCE: 它的更新依赖于一个回合结束后计算出的完整未来回报 G_t。
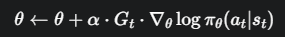
问题所在: G_t 的随机性太大了。在同样的状态下,仅仅因为后续一连串动作中的一点点随机性,最终得到的 G_t 可能会天差地别。
这导致梯度更新的方向非常不稳定,就像一个醉汉走路,虽然大方向正确,但摇摇晃晃,收敛速度很慢。
为了解决这个问题,研究者们提出了一个绝妙的想法:我们能不能不用这个充满噪声的 G_t,而是找一个更稳定、偏差更小的评估信号来指导策略的更新呢?
Actor-Critic 架构:两位一体的合作
Actor-Critic 算法引入了两个网络(或一个网络分出来的两个头),它们各司其职,互相合作。
演员 (Actor)
角色: 策略网络 (Policy Network),和 REINFORCE 中的一样。
职责: 负责决策。它根据当前的状态 s,输出一个动作的概率分布 π(a|s; θ)。我们的最终目标就是训练好这个演员。
参数: θ。
评论家 (Critic)
角色: 价值网络 (Value Network)。
职责: 负责评估。它不直接产生动作,而是对演员的表现进行“打分”。具体来说,它学习一个状态价值函数 V(s; w),用来判断当前状态 s 有多好。
参数: w (为了与演员的参数区分开)。
整个流程就像演戏:演员(Actor)在舞台上表演(做出动作),评论家(Critic)在台下观看并给出评价(这个动作好不好?),演员则根据评论家的反馈来调整自己的表演(更新策略)。
核心思想:用“优势”替代“回报”
评论家是如何给出“评价”的呢?它通过计算一个非常重要的概念——优势函数 (Advantage Function) A(s, a)。
优势函数的定义是:
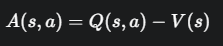
直观含义: 在状态 s 下,采取动作 a 带来的价值 Q(s, a),比该状态的平均价值 V(s) 好多少?
如果 A(s, a) > 0,说明动作 a 比平均水平要好,是“有优势的”动作。
如果 A(s, a) < 0,说明动作 a 比平均水平要差。
在策略梯度定理中,我们可以用优势函数 A(s, a) 来替代原来的 G_t,这样做不仅能大大降低方差,而且在数学上可以证明其期望是不变的。
策略梯度的更新就变成了:
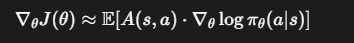
如何计算优势函数?—— TD 误差的登场
问题来了,为了计算优势 A(s, a),我们似乎需要知道 Q(s, a) 和 V(s)。难道我们要同时学习两个网络(Q网络和V网络)吗?
其实不必。我们可以用时序差分误差 (TD Error) 来作为优势函数的一个很好的估计。
我们知道 Q(s, a) 的期望是 r + γV(s')。代入优势函数公式:
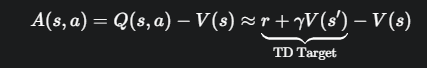
r + γV(s') - V(s) 正是我们熟悉的 TD 误差 δ_t
这是 Actor-Critic 方法最核心的洞见:
评论家(Critic)计算出的 TD 误差,既可以用来评估和更新自己(Critic)的价值网络,又可以作为优势函数的估计来指导演员(Actor)的策略更新。
算法与更新公式
在一个 Actor-Critic 算法中,每走一步,我们都会同时更新两个网络。
假设智能体在状态 s_t 执行动作 a_t,得到奖励 r_t 和新状态 s_{t+1}。
-
计算 TD 误差 (由 Critic 完成)
![image]()
V_w 代表由 Critic 网络计算出的价值 -
更新评论家 (Critic)
Critic 的目标是让自己的价值估计 V_w(s_t) 尽可能接近 TD 目标 r_t + γV_w(s_{t+1})
因此,它的损失函数就是 TD 误差的平方。我们通过梯度下降来最小化这个损失。
Loss_Critic: L(w) = δ_t^2
更新:![image]()
![image]()
-
更新演员 (Actor)
演员用 Critic 提供的 TD 误差 δ_t 作为优势信号,来更新自己的策略
![image]()
![image]()
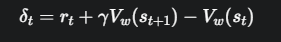
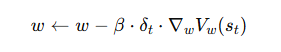

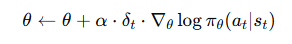

在更新 Actor 时,δ_t 被视为一个从 Critic 传来的常数,我们不希望 Actor 的更新去影响 Critic 的计算(即梯度不从 Actor 流回 Critic)。
在代码实现中,通常会对 δ_t 使用 .detach()。
代码实现解读
Actor-Critic 的代码实现与 REINFORCE 有何不同
模型定义
通常我们会用一个网络,但它有两个不同的“头”(输出层),一个输出策略(Actor),一个输出状态价值(Critic)。
import torch.nn as nn
import torch.nn.functional as F
class ActorCritic(nn.Module):
def __init__(self):
super(ActorCritic, self).__init__()
# 公共的特征提取层
self.affine1 = nn.Linear(4, 128)
# 演员(Actor)的头
self.action_head = nn.Linear(128, 2) # 输出动作概率
# 评论家(Critic)的头
self.value_head = nn.Linear(128, 1) # 输出状态价值
def forward(self, x):
x = F.relu(self.affine1(x))
# Actor 输出动作概率分布
action_probs = F.softmax(self.action_head(x), dim=-1)
# Critic 输出状态价值
state_values = self.value_head(x)
return action_probs, state_values
### 训练步骤(在一个时间步内)
与 REINFORCE 在回合结束后更新不同,Actor-Critic 每一步都可以更新。
# 假设我们已经从环境中得到 s_t, a_t, r_t, s_{t+1}
# a_t 是通过从 actor 的输出概率中采样得到的,同时保存了 log_prob(a_t)
# 使用模型进行前向传播
action_probs, state_value = model(s_t) # Critic 对当前状态的打分 V(s_t)
_, next_state_value = model(s_{t+1}) # Critic 对下一状态的打分 V(s_{t+1})
# 1. 计算 Critic 的 TD 误差 (即优势)
# detach()确保在计算TD目标时,梯度不会流经next_state_value
td_target = r_t + GAMMA * next_state_value.detach()
advantage = td_target - state_value

# 2. 计算 Critic 的损失 (均方误差)
critic_loss = advantage.pow(2)
# 3. 计算 Actor 的损失
# detach()确保梯度只用于更新Actor,而不影响Critic
actor_loss = -log_prob(a_t) * advantage.detach()
# 4. 计算总损失并进行优化
total_loss = critic_loss + actor_loss
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
import gym
env = gym.make('CartPole-v1')
env.reset(seed=1)
# env.observation_space.shape[0], env.action_space.n (4, 2)
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Policy(nn.Module):
"""
implements both actor and critic in one model
"""
def __init__(self):
super(Policy, self).__init__()
self.affine1 = nn.Linear(4, 128)
# actor's layer
self.action_head = nn.Linear(128, 2)
# critic's layer
self.value_head = nn.Linear(128, 1)
# action & reward buffer
self.saved_actions = []
self.rewards = []
def forward(self, x):
"""
forward of both actor and critic
"""
x = F.relu(self.affine1(x))
# actor: choses action to take from state s_t
# by returning probability of each action
action_prob = F.softmax(self.action_head(x), dim=-1)
# critic: evaluates being in the state s_t
state_values = self.value_head(x)
# return values for both actor and critic as a tuple of 2 values:
# 1. a list with the probability of each action over the action space
# 2. the value from state s_t
return action_prob, state_values
model = Policy()
optimizer = optim.Adam(model.parameters(), lr=3e-2)
from collections import namedtuple
import numpy as np
from torch.distributions import Categorical
SavedAction = namedtuple('SavedAction', ['log_prob', 'value'])
def select_action(state):
state = torch.from_numpy(state).float()
probs, state_value = model(state)
# create a categorical distribution over the list of probabilities of actions
m = Categorical(probs)
# and sample an action using the distribution
action = m.sample()
# save to action buffer
model.saved_actions.append(SavedAction(m.log_prob(action), state_value))
# the action to take (left or right)
return action.item()
def finish_episode():
"""
Training code. Calculates actor and critic loss and performs backprop.
"""
R = 0
eps = np.finfo(np.float32).eps.item()
saved_actions = model.saved_actions
policy_losses = [] # list to save actor (policy) loss
value_losses = [] # list to save critic (value) loss
returns = [] # list to save the true values
# calculate the true value using rewards returned from the environment
for r in model.rewards[::-1]:
# calculate the discounted value
R = r + 0.99 * R
returns.insert(0, R)
returns = torch.tensor(returns)
returns = (returns - returns.mean()) / (returns.std() + eps)
for (log_prob, value), R in zip(saved_actions, returns):
advantage = R - value.item()
# calculate actor (policy) loss
policy_losses.append(-log_prob * advantage)
# calculate critic (value) loss using L1 smooth loss
value_losses.append(F.smooth_l1_loss(value, torch.tensor([R])))
# reset gradients
optimizer.zero_grad()
# sum up all the values of policy_losses and value_losses
loss = torch.stack(policy_losses).sum() + torch.stack(value_losses).sum()
# perform backprop
loss.backward()
optimizer.step()
# reset rewards and action buffer
del model.rewards[:]
del model.saved_actions[:]
from itertools import count
def main():
running_reward = 10
# run infinitely many episodes
for i_episode in count(1):
# reset environment and episode reward
state, _ = env.reset()
ep_reward = 0
# for each episode, only run 9999 steps so that we don't
# infinite loop while learning
for t in range(1, 10000):
# select action from policy
action = select_action(state)
# take the action
state, reward, done, _, _ = env.step(action)
model.rewards.append(reward)
ep_reward += reward
if done:
break
# update cumulative reward
running_reward = 0.05 * ep_reward + (1 - 0.05) * running_reward
# perform backprop
finish_episode()
# log results
if i_episode % 10 == 0:
print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(
i_episode, ep_reward, running_reward))
# check if we have "solved" the cart pole problem
if running_reward > env.spec.reward_threshold:
print("Solved! Running reward is now {} and "
"the last episode runs to {} time steps!".format(running_reward, t))
break
if __name__ == '__main__':
main()
这份代码清晰地展示了一个基础但完整的 Actor-Critic 算法流程:
Actor 根据策略采样动作。
与环境交互,并将整个回合的 (log_prob, value) 和 reward 存储起来。
回合结束后,计算出真实的折扣回报 G_t。
计算优势 A_t = G_t - V(s_t)。
Critic 通过最小化 V(s_t) 和 G_t 的差距来学习。
Actor 通过最大化 log(π) * A_t 来学习。
两个网络的损失被加在一起,共同优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号