大模型- PPO大语言模型(LLM)对齐的强化学习算法 -75
故事设定:训练一名弓箭手
智能体 (Agent):一名弓箭手。
策略 (Policy):弓箭手在看到目标距离、风速等情况后,决定“拉弓的力度”和“瞄准的角度”的策略。
动作 (Action):具体的一次拉弓和瞄准。
奖励 (Reward):箭命中靶心(高奖励),命中靶子(低奖励),脱靶(负奖励)。
目标:调整弓箭手的策略,让他射出的每一箭得分尽可能高。
最基础的想法 (Vanilla Policy Gradient)
如果一箭射得好(奖励高),就让弓箭手以后更倾向于这么做。
如果一箭射得差(奖励低),就让他以后尽量避免这么做。
这就是策略梯度 (Policy Gradient, PG) 的核心。它的目标函数很简单
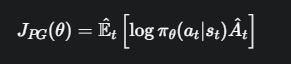
拆解公式:
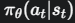 这是我们的策略(Policy),θ 代表策略网络(弓箭手的大脑)的参数。整个式子表示在状态 st (看到靶子和风速)下,执行动作 at(拉弓瞄准)的概率。
这是我们的策略(Policy),θ 代表策略网络(弓箭手的大脑)的参数。整个式子表示在状态 st (看到靶子和风速)下,执行动作 at(拉弓瞄准)的概率。
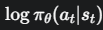 对这个概率取对数。可以理解为我们用来调整策略的“旋钮”。我们正是通过改变这个值来更新策略的。
对这个概率取对数。可以理解为我们用来调整策略的“旋钮”。我们正是通过改变这个值来更新策略的。
 优势函数 (Advantage Function)。这是最关键的信号!它回答的问题是:“这次的动作,相比于平均水平,是更好还是更差?”,
优势函数 (Advantage Function)。这是最关键的信号!它回答的问题是:“这次的动作,相比于平均水平,是更好还是更差?”,
A^t>0:说明这次动作(比如“大力拉弓”)比他平时的平均表现要好。这是一个惊喜,是“好动作”。
A^t>0:说明这次动作是个昏招,比平均表现差。
A^t>0≈0:表现平平,和预期一样。
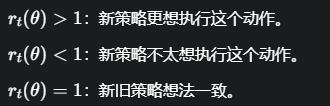
通过梯度上升,我们要最大化 J(θ),
当A^t是一个很大的正数时(射中靶心!),我们会增大 ,意味着以后在类似情况下,执行这个动作的概率会变高。
,意味着以后在类似情况下,执行这个动作的概率会变高。
当A^t是一个负数时(脱靶了!!),我们会减小,意味着以后要降低这么做的概率。
基础想法的致命缺陷
策略梯度方法非常不稳定。想象一下,我们的弓箭手某次只是运气好,一阵妖风把他射偏的箭吹回了靶心,获得了超高的优势 A^t。
如果学习的步子(学习率)迈得太大,弓箭手(算法)就会产生一个“幻觉”:“原来大力出奇迹,以后不管什么情况,我就要这么射!”。这个单一的、错误的巨大更新,可能会彻底摧毁他好不容易学到的所有技巧。策略崩溃了。
这就是 PPO 要解决的核心问题:如何既要利用梯度带来的提升,又要防止这种自毁式的更新
PPO 的解决方案 —— 引入“信任”和“限制”
PPO 说:“我们可以更新策略,但新策略不能和旧策略差别太大”。它引入了两个关键概念。
策略指的就是模型的参数。
我们用旧的策略  收集了一批数据(射了一组箭),现在想用这批数据来评估一个新策略 πθ的好坏。为了修正新旧策略的差异,我们引入了
收集了一批数据(射了一组箭),现在想用这批数据来评估一个新策略 πθ的好坏。为了修正新旧策略的差异,我们引入了重要性采样 (Importance Sampling),其核心就是概率比:
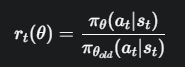
我们的目标函数变成了:
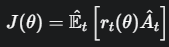
但这并没有解决问题,如果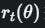 变得非常大,更新步子依然会失控。
变得非常大,更新步子依然会失控。
裁剪 (Clipping) —— PPO 的灵魂
为了限制 rt(θ),PPO 设计了它最核心的裁剪目标函数
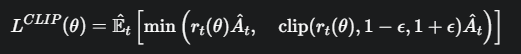
-
ϵ (epsilon):是一个很小的超参数,比如 0.2。它定义了一个信任区间 [1−ϵ,1+ϵ],即 [0.8,1.2]。我们只信任在这个区间内的策略变化。
-
![image]() :这就是裁剪函数。它会把 rt(θ) 强行“摁”在 [0.8,1.2] 这个区间里。
:这就是裁剪函数。它会把 rt(θ) 强行“摁”在 [0.8,1.2] 这个区间里。
![image]()
-
min(…,…):取两个值中较小的一个
 :这就是裁剪函数。它会把 rt(θ) 强行“摁”在 [0.8,1.2] 这个区间里。
:这就是裁剪函数。它会把 rt(θ) 强行“摁”在 [0.8,1.2] 这个区间里。
公式详解:两种情况下的智能博弈
情况1: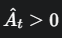 (这是一个好动作,比如射中了靶心)
(这是一个好动作,比如射中了靶心)
目标函数获得尽可能多的奖励,公式变成了:min(原始目标,裁剪后目标)
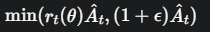

对于好动作,PPO 设置了一个奖励的“天花板”。它鼓励你更新,但当你的更新幅度试图超出信任区间时,它会把你的收益限制住,防止你因为一次巨大的成功而得意忘形,从而毁掉整个策略。
情况二: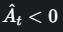 (这是一个坏动作,比如脱靶了)
(这是一个坏动作,比如脱靶了)
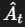 是一个负数,目标依然是最大化 L CLIP (即让这个负数尽可能接近0)
是一个负数,目标依然是最大化 L CLIP (即让这个负数尽可能接近0)
乘以负数会改变不等号方向。
当策略更新还比较“温和”时,rt(θ) 在 1 附近,还没有低于 1−ϵ (比如 r t =0.9,ϵ=0.2)。此时,min 依然会选择原始目标 ,允许策略正常地减小执行这个坏动作的概率。
,允许策略正常地减小执行这个坏动作的概率。

对于坏动作,PPO 设置了一个惩罚的“地板”。它允许你从错误中学习,但当你试图过度惩罚一个动作,可能导致策略变得“畏手畏脚”时,它会限制这个惩罚的力度,告诉你“没关系,不用这么恐慌,我们小步调整就行”。
总结
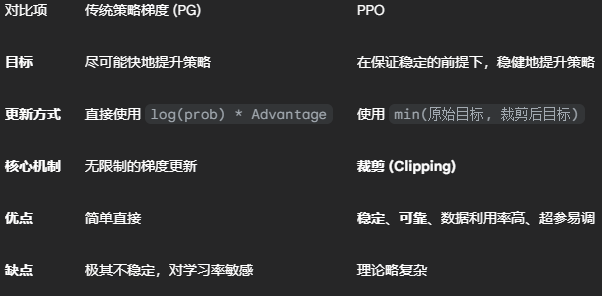
PPO 的理论精髓就在于,它通过一个极其巧妙的、分情况讨论的 min-clip 结构,为策略更新自动地施加了一个动态的、柔性的“刹车”和“安全带”。这使得它在获得良好性能的同时,极大地避免了训练过程中可能出现的灾难性崩溃,成为当今强化学习领域最可靠和常用的算法之一。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号