大模型-权重绑定: tie_word_embeddings技术的来龙去脉-67
先说结论:
模型不再需要为 lm_head 单独学习一个巨大的权重矩阵,而是直接“重用”embedding 的权重。
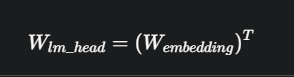
一、核心思想:模型的“输入”与“输出”为何要关联?
要理解权重绑定,我们首先要理解语言模型的两个关键部分:
词嵌入层 (Input Embedding Layer):
作用:将输入的每个词(或 token)的 ID 转换成一个高维的、稠密的向量。这个向量就代表了这个词的“语义”。
形式:它本质上是一个巨大的查找表(Look-up Table),其权重矩阵的形状是 (词汇表大小, 隐藏层维度),即 (vocab_size, hidden_size)。
可以理解为:模型的“耳朵”或“眼睛”,负责将人类的符号(单词)翻译成模型能理解的数学语言(向量)。
语言模型头 (Output LM Head):
作用:在模型经过一系列复杂的计算后,将最终的内部状态(一个 hidden_size 维的向量)转换成在整个词汇表上每个词的得分(logits)。这个得分越高,表示模型认为下一个词是这个词的概率越大。
形式:它通常是一个标准的线性层,其权重矩阵的形状是 (hidden_size, vocab_size)。
可以理解为:模型的“嘴巴”,负责将模型的内部“思考”结果翻译回人类能理解的符号(预测下一个单词)。
直觉来了:
输入嵌入层学习 单词 -> 语义向量 的映射。
输出语言模型头学习 语义向量 -> 单词得分 的映射。
这两者在功能上是高度相关甚至是互逆的。既然一个是将单词编码为语义,另一个是将语义解码为单词,那么它们使用的“密码本”(权重矩阵)有没有可能是同一个呢?
答案是肯定的。权重绑定技术就是基于这个直觉,强制让这两个矩阵共享同一份权重。
二、什么是权重绑定 (Weight Tying)?
权重绑定是一种模型设计技术,它规定:输出语言模型头 (lm_head) 的权重矩阵,直接使用输入词嵌入层 (embedding) 的权重矩阵的转置 (Transpose)。
用公式表达就是:
lm_head= W_embedding^T
这意味着,模型不再需要为 lm_head 单独学习一个巨大的权重矩阵,而是直接“重用”embedding 的权重。
三、为什么要使用权重绑定?
这项技术带来的好处是巨大的,主要有两点:
- 显著减少模型参数量(最主要的好处)
这是最直接、最显著的优点。大语言模型的词汇表通常非常大(例如 50,000 到 150,000),而隐藏层维度也很高(例如 4096)。
我们来算一笔账:
embedding 矩阵的参数量 = vocab_size * hidden_size
lm_head 矩阵的参数量 = hidden_size * vocab_size
假设 vocab_size = 50,257 (类似 GPT-2) 且 hidden_size = 4096 (类似 Llama 7B):
单个矩阵的参数量 ≈ 50,000 * 4000 = 200,000,000 (2亿)
两个矩阵加起来就是 4亿 参数。
通过权重绑定,我们直接省掉了 lm_head 的这2亿参数。对于一个70亿参数的模型来说,这就节省了约 3% 的总参数量,这相当可观。这不仅减少了模型在硬盘上的存储体积,也降低了加载到显存中的占用。
- 可能提升模型性能(正则化效果)
权重绑定强迫模型在输入端和输出端使用同一套“语义-符号”转换规则。这相当于给模型增加了一种很强的归纳偏置(inductive bias),可以起到正则化的作用。
防止过拟合:模型不能为输入和输出学习两套独立的、可能存在噪声的映射,而是必须学习一套更通用、更一致的表示。
提升学习效率:在训练过程中,当模型通过反向传播更新 embedding 层的权重时,lm_head 的权重也同时被隐式地更新了(反之亦然)。这使得梯度的利用更有效率。
这项技术最早由 Press and Wolf 在2017年的论文《Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling》中提出,并被后续几乎所有的 Transformer 模型(包括 GPT 系列、Llama 系列等)所采纳,证明了其有效性。
代码
import torch
from torch import nn
class SimpleLanguageModel(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
print(f"初始化模型...\n词汇表大小: {vocab_size}\n隐藏层维度: {hidden_size}\n")
# 1. 定义输入词嵌入层
self.embedding = nn.Embedding(vocab_size, hidden_size)
# 2. 假设这是模型的中间计算层 (例如 Transformer Blocks)
# 为了简化,我们只用一个简单的线性层代替
self.transformer_body = nn.Linear(hidden_size, hidden_size)
# 3. 定义输出语言模型头
# 注意:这里的输出维度是 vocab_size
# 通常 lm_head 不需要偏置项 (bias)
self.lm_head = nn.Linear(hidden_size, vocab_size, bias=False)
# 4. ✨✨✨ 权重绑定发生在这里!✨✨✨
# 将 lm_head 的权重指针指向 embedding 的权重
# PyTorch 的 nn.Linear 的权重形状是 (out_features, in_features)
# nn.Embedding 的权重形状是 (num_embeddings, embedding_dim)
# 正好符合 W_lm_head = (W_embedding)^T 的关系,可以直接赋值
print("执行权重绑定:self.lm_head.weight = self.embedding.weight")
self.lm_head.weight = self.embedding.weight
def forward(self, input_ids):
# input_ids: (batch_size, sequence_length)
# 1. 转换为词嵌入向量
# -> (batch_size, sequence_length, hidden_size)
x = self.embedding(input_ids)
# 2. 通过模型主体进行计算
# -> (batch_size, sequence_length, hidden_size)
x = self.transformer_body(x)
# 3. 通过语言模型头计算 logits
# -> (batch_size, sequence_length, vocab_size)
logits = self.lm_head(x)
return logits
# --- 验证 ---
VOCAB_SIZE = 1000
HIDDEN_SIZE = 128
model = SimpleLanguageModel(VOCAB_SIZE, HIDDEN_SIZE)
# 打印参数量来验证
total_params = sum(p.numel() for p in model.parameters())
embedding_params = model.embedding.weight.numel()
transformer_body_params = sum(p.numel() for p in model.transformer_body.parameters())
# lm_head 的权重已经被绑定,所以它的参数不会被独立计算
# model.parameters() 会自动处理共享权重,只计算一次
print(f"\n模型总参数量: {total_params}")
print(f"词嵌入层参数量: {embedding_params}")
print(f"模型主体参数量: {transformer_body_params}")
print(f"预期总参数量 (Embedding + Body): {embedding_params + transformer_body_params}")
# 最终验证:检查两个权重张量是否是内存中的同一个对象
# 如果ID相同,说明它们是完全同一个东西,而不是简单的数值相等
is_tied = id(model.embedding.weight) == id(model.lm_head.weight)
print(f"\n权重真的绑定了吗? (内存地址是否相同): {is_tied}")
# 我们可以看到,lm_head的权重确实指向了embedding的权重对象
print(f"Embedding weight ID: {id(model.embedding.weight)}")
print(f"LM Head weight ID: {id(model.lm_head.weight)}")
代码输出分析:
初始化模型...
词汇表大小: 1000
隐藏层维度: 128
执行权重绑定:self.lm_head.weight = self.embedding.weight
模型总参数量: 144512
词嵌入层参数量: 128000
模型主体参数量: 16512
预期总参数量 (Embedding + Body): 144512
权重真的绑定了吗? (内存地址是否相同): True
Embedding weight ID: 140263620290880
LM Head weight ID: 140263620290880
从输出可以清晰地看到,模型的总参数量正好是 embedding 和 transformer_body 的参数之和,lm_head 没有贡献新的参数。最关键的是,id() 函数的验证结果为 True,证明了这两个权重在内存中是同一个对象,完美实现了权重绑定。
在像 Hugging Face Transformers 这样的库中,你通常不需要手动写这段代码,只需要在模型配置文件中设置 config.tie_word_embeddings = True,库就会在模型初始化时自动为你完成绑定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号