大模型-大模型权重文件打包技术-64
好的,完全没有问题。我们来用中文详细介绍一下大模型中 “打包模块 (Packed Modules)” 和 “权重打包 (Weight Packing)” 这项关键技术。
这项技术并不是单一的某个方法,而是一系列优化策略的统称。它的核心目标非常明确:在保证模型效果的同时,大幅提升大模型的推理性能(速度)并降低其对内存/显存的占用。
下面我们从“是什么”、“为什么”和“怎么做”三个方面来深入解析。
一、 是什么:权重打包的核心概念
在高层次上,“权重打包”指的是将模型中多个、分离的权重(参数)以更紧凑、更高效的方式组织和存储起来。这主要通过两种方式实现:
算子融合 (Operator Fusion),或称矩阵打包
这指的是将多个独立但相关的运算(算子)及其权重矩阵合并成一个单一的、更大的矩阵。最经典、最常见的例子就是 Transformer 模型中的注意力机制。模型原本有三个独立的权重矩阵,分别用于计算 Query (Wq)、Key (Wk) 和 Value (Wv),通过打包技术,可以将这三个矩阵在存储上拼接成一个大的 Wqkv 矩阵。
量化与比特打包 (Quantization & Bit-Packing)
这指的是首先降低权重的数据精度(例如,从32位浮点数降为8位或4位整数,即“量化”),然后将多个低精度的权重“塞”进一个标准的数据类型中。例如,我们可以将两个 4-bit 的权重打包存入一个 8-bit 的整数中。
相应地,“打包模块” 就是指神经网络中经过改造、能够直接在这种打包后的权重上进行运算的模块(例如,一个注意力层或全连接层)。这通常需要专门编写的计算代码(在GPU上称为 “自定义计算核心” 或 Custom CUDA Kernel)来配合。
二、 为什么:使用打包技术的强大动机
部署和运行大模型对硬件的要求极高。其性能瓶颈往往不是 GPU 的原始计算能力(算力),而是内存带宽——也就是数据(主要是模型权重)从 GPU 显存移动到负责计算的芯片缓存中的速度。打包技术正是为了解决这个核心瓶颈。
| 动机 | 打包技术如何实现 |
|---|---|
| 1. 提升推理速度 | 通过 算子融合(如合并 QKV),将三次独立的小规模矩阵运算合并为一次大规模矩阵运算。这显著减少了 计算核心启动开销(即 CPU 指令 GPU 开始一个新任务所需的时间),并让 GPU 的计算单元一次性处理更多数据,保持“火力全开”的状态。 |
| 2. 降低内存占用 | 量化与比特打包 可以极大压缩模型体积。一个使用 4-bit 权重 的模型,大小仅为原始 32-bit 版本的 1/8。这使我们可以在相同显存的硬件上运行更大的模型,或使用更经济的硬件。 |
| 3. 提高系统吞吐量 | 由于模型更小、计算更快,像 vLLM 这样的推理框架可以在一个批次(Batch)中容纳更多用户请求(得益于 连续批处理 技术)。这显著提升了模型同时服务用户的能力,即吞吐量。 |
| 4. 优化缓存效率 | 对 GPU 而言,一次性读取一大块连续的内存(打包后的权重),比读取三块分散的小内存要高效得多。这种模式更好地利用了 GPU 上宝贵的高速缓存(Cache),避免了重复从慢速显存读取数据。 |
三、 怎么做:两种主流打包技术的实现方法
- 算子融合实例:合并 QKV
在标准的 Transformer 注意力层中,计算 Q、K、V 需要三步独立的矩阵乘法:
Q=输入数据×Wq
K=输入数据×Wk
V=输入数据×Wv
这需要对“输入数据”这个张量进行三次读取,并启动三次独立的GPU计算任务。
采用打包/融合技术后:
Wq、Wk、Wv 这三个矩阵会离线(在模型加载前)被拼接成一个单独的大矩阵 Wqkv。
W qkv =concat(W q, W k, W v)
现在,计算过程变成了一次更高效的、更大规模的矩阵乘法:
QKV packed =输入数据×W qkv
一个经过特殊优化的“融合计算核心 (Fused CUDA Kernel)” 会执行这个单一的运算,然后在GPU内部的高速共享内存中直接将结果切分回 Q、K、V 三个部分,整个过程无需将中间的 QKV_packed 结果写回到慢速的全局显存中,效率极高。
packed_modules_mapping = {
"q_proj": ("qkv_proj", "q"),
"k_proj": ("qkv_proj", "k"),
"v_proj": ("qkv_proj", "v"),
"gate_proj": ("gate_up_proj", 0),
"up_proj": ("gate_up_proj", 1),
}
这正是您之前展示的 vLLM 代码所处理的情况。 代码中的 packed_modules_mapping 字典就像一个“配方”或“说明书”,它告诉模型加载器:
“当你在权重文件中看到一个名叫 ...q_proj... 的权重时,不要直接在模型里找同名参数。你应该去模型里找到名叫 ...qkv_proj... 的那个参数,然后把从文件中读到的数据加载到这个大参数的指定分片(shard_id)中去。”
- 量化与比特打包实例
假设你已经将模型的权重“量化”到了 4-bit 精度,这意味着每个权重的值是 0 到 15 之间的一个整数。但现代计算机没有原生的 4-bit 数据类型,最小的存储单元通常是 8-bit(一个字节,即 uint8)。
如果用一个 8-bit 的空间去存一个 4-bit 的数据,就浪费了一半的存储空间。
采用比特打包技术后:
解决方案是将两个 4-bit 的权重“打包”存入一个 8-bit 的整数中。
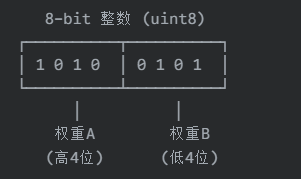
假设有两个 4-bit 权重:
权重 A = 10 (二进制 1010)
权重 B = 5 (二进制 0101)
我们可以将它们打包进一个 8-bit 整数。例如,让权重 A 占据高4位,权重 B 占据低4位。
打包后的值 (二进制) = 1010 0101,即十进制的 165。
如何使用:
模型在保存时,权重就被打包好。在加载进内存进行推理时,它们也保持着打包状态。在进行矩阵乘法时,专门的计算核心会:
从内存加载这个打包后的 8-bit 值。
在计算前的一瞬间,通过位运算(如移位和掩码操作)将其“解包”,还原成两个独立的 4-bit 权重。
用解包后的权重完成计算。
这个“解包”操作在GPU的寄存器或高速共享内存中进行,速度极快,其带来的微小开销远小于因内存占用减少而获得的巨大收益。
总而言之,“权重打包”是一项非常强大且实用的工程优化技术。它通过算子融合和量化比特打包两种核心手段,直接优化了LLM推理中最关键的瓶颈——内存带宽,从而实现了更快的速度、更低的显存占用和更高的系统吞吐量。
虽然它增加了实现的复杂性(需要专门的计算核心和配套的模型加载逻辑,如vLLM所示),但带来的性能提升是巨大的,是当今所有主流高性能LLM推理框架的必备技术。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号