

大模型微调(七):近端策略优化PPO
奖励模型 R_\phi(x,y) 不会输出“好”或“坏”这样的标签。相反,它会生成一个连续的分数,通常是一个实数,类似于:
R_\phi(x,y) \in \mathbb{R}。
该分数反映了对于给定提示 x,响应 y 的可取性或与人类价值观的契合程度。在训练过程中,模型会观察对同一提示 x 的响应对 (y^+, y^-)。假设人类已经认定 y^+ 比 y^- 更好。
损失函数鼓励模型对 y^+ 给出比 y^- 更高的分数:
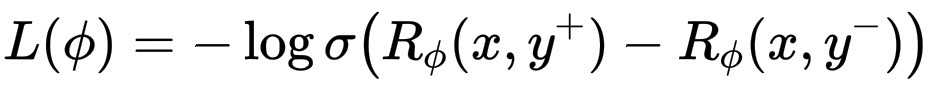
L(\phi) = -\log \sigma\big(R_\phi(x,y^+) - R_\phi(x,y^-)\big)
经过训练后,模型可以对单个响应 y 进行评分,并得出 R_\phi(x,y)。分数越高,预测该响应就越“符合人类偏好”。该分数随后成为 PPO 阶段的“奖励信号”,引导经过微调的模型生成更好的响应。
接下来,我们将学习到的奖励与KL惩罚相结合,使其逐渐回到基础模型,这一步也被称为shape reward:
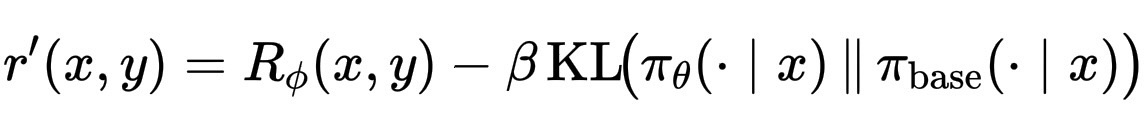
r’(x,y) = R_\phi(x,y)-\beta\, \mathrm{KL}\!\big(\pi_\theta(\cdot\mid x)\,\|\,\pi_{\text{base}}(\cdot\mid x)\big)。
其中,R是奖励模型的得分,表示人类对该响应的喜爱程度。KL 衡量微调策略与原始基础模型的偏离程度。\beta 控制平衡,较小的 beta 值会让模型更大胆;较大的 beta 值则使其更安全,更“贴合模型”。
这里的KL惩罚项像刹车一样,抑制了“夸张的”人类偏好。它可以防止模型过度拟合奖励模型的偏差或训练数据中的极端样本,让模型更贴近人类的喜好,但不要忘记最初的良好习惯。
一旦我们有了shape reward r'(x,y),我们就需要一种方法来判断某个输出是比预期更好还是更差。这就是优势函数 A(x,y) 所捕捉到的。
在大模型(策略 \pi_\theta)针对提示 x 生成多个响应 y 后,我们使用奖励模型得到 R_\phi(x,y)。然后我们添加 KL 项,得到形状奖励 r'(x,y)。
我们还有一个价值函数 V_\psi(x)。这是一个经过训练的小模型,用于预测对于给定提示 x,我们平均预期的奖励金额。它通过提供“基线”期望来帮助稳定训练。
现在我们计算:
A(x,y) = r’(x,y) - V_\psi(x)
如果 A > 0,则响应优于预期,因此 PPO 应该增加其概率。
如果 A < 0,则响应低于预期,因此 PPO 应该降低其概率。
PPO 会将 \pi_\theta 推向具有正优势的动作(标记/序列),并远离具有负优势的动作,但会进行裁剪,以免移动过远。设概率比为:
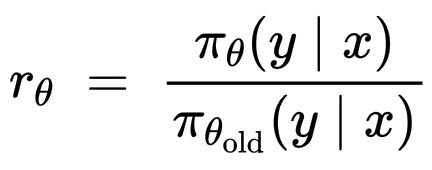
r_\theta = \frac{\pi_\theta(y\mid x)}{\pi_{\theta_{\text{old}}}(y\mid x)}
PPO 会在小批量上最大化:
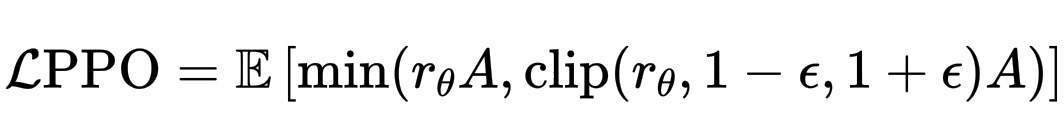
\mathcal{L}{\text{PPO}} = \mathbb{E}\,\left[\min(r_\theta A, \text{clip}(r_\theta, 1-\epsilon, 1+\epsilon)A)\right]
其中 \epsilon 是一个较小的数(例如 0.1–0.2),\hat{R} 是价值学习的回报/目标。min-with-clip 表示:“如果有帮助,则增加概率,但一次更新不要增加太多。”
整个循环可以简单总结为:
1. 样本提示 x,并使用当前 \pi_\theta 生成响应 y。
2. 使用奖励模型和 KL 项计算 r’(x,y)。
3. 估算 A(使用V_\psi)。
4. 通过最大化 PPO 目标(带裁剪)更新 \theta。
5. 对收集的数据重复几个 epoch,然后收集新的样本。
PPO 并非语言模型独有。它是 OpenAI 于 2017 年开发的一种通用强化学习算法,适用于任何需要稳定策略更新的智能体,机器人、游戏玩家或文本生成器。
在 LLM 的案例中,工程师们借用了 PPO,因为它很好地解决了一个非常具体的问题:如何利用奖励改进策略,同时避免突然的、破坏性的更新。因此,在模型的强化学习高频阶段,PPO 成为了调整参数的工具。
在一般强化学习中,PPO 可以训练智能体玩 Atari 游戏、控制机器人等。
在 LLM 的案例中:PPO 训练生成文本的策略。“环境”是指提示-响应过程,“奖励”来自奖励模型(基于人类偏好),“策略”是语言模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号