

python工作中的使用;
1.求出两个日期,间隔的天数;如某个时间查询区间,只能查询180天内的数据;
import datetime x=datetime.date(2021,10,21) y=datetime.date(2021,4,24) print(x.__sub__(y))
2.对比两个文件的差异;如开发,将线索的线索标记为A,批量刷为B,则需要对比刷新前后的数据;
最终结果:

Difflib作为pytohn的标准库,无需安装,作用是对比文本之间的差异,而且支持输出可读性比较强的HTML文档;
HtmlDiff()可以用于创建一个完整HTML文件,该文件显示具有行间和行内更改突出的文本逐行比较。
make_file()比较字符串列表并返回一个字符串,该字符串是一个完整的HTML文件,其中包含一个表格,显示逐行差异,突出显示行间和行内更改。
splitlines()方法将字符串,拆分为一个列表,其中每一行都是一个列表项。
import difflib data1="x.txt" data2="y.txt" with open(data1,"r",encoding='utf-8') as file1,open(data2,"r",encoding='utf-8') as file2: f1=file1.read().splitlines(keepends=True) f2=file2.read().splitlines(keepends=True) diff=difflib.HtmlDiff() result1=diff.make_file(f1,f2) with open('a_b.html','a+',encoding='utf-8') as f: f.write(result1)
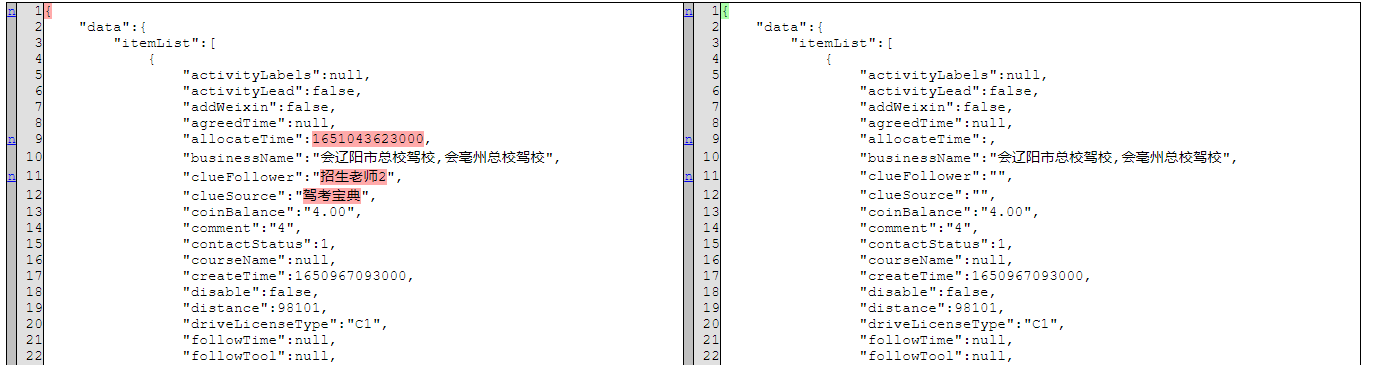
注意:页面查出的响应结果,可能含有unicode码,如,{"data":{"itemList":[{"activityLabels":null,"activityLead":false,"addWeixin":false,"agreedTime":null,"allocateTime":1651043623000,"businessName":"\u4F1A\u8FBD\u9633\u5E02\u603B\u6821\u9A7E\u6821,;
1.可先将Unicode编码,转为中文;链接:https://tool.chinaz.com/tools/unicode.aspx;
2.直接复制Unicode转中文后的内容 到txt文档,会报错;再转一次json格式;复制粘贴到txt文档,运行*.py还是报错;下载-改成.txt文档,可正常运行.py文件;链接:https://www.json.cn/#;
3.直接复制响应结果到txt文本执行,也可以,但数据是一行,不方便查看;转换为json格式,方便查看;
复制粘贴到txt文档,报错,可能是Windows Unix(LF)格式造成的,具体原因未知;

补充知识:
ANSI,是一种字符代码,扩展的ASCII编码;
unicode编码;
中国电脑常用编码:gbk,utf-8;
URL 解码、编码;
3.url不同地方,投放的的url不同,用来区分来源;
可以使用requests.get方法去请求URL,再用正则去匹配关键词;并且断言结果;已判断url可正确访问且埋点正确;
4.报表相关的测试;
方式一、根据相关条件直接去数据库查询;
方式二、根据页面响应结果,使用python对数据进行处理,再和报表去对比;
为什么要去对数据进行处理呢?因为报表中某项定义的值可能有几百条,但页面没有条件,可直接查询出来;
如线索标记为无效,无效有12种,需要算出某个创建期间,标记为无效的线索条数,怎么办?页面无法直接查询出来,可以使用python对数据处理一下;一般的响应结果为json格式;可以使用json.load,将字符串解码为python对象(如,解码为字典格式);后续就按照python对字典、列表的处理,进行操作了;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号